This article is the second in an editorial series with a goal to provide a road map for scientific researchers wishing to capitalize on the rapid growth of big data technology for collecting, transforming, analyzing, and visualizing large scientific data sets.
In the last article, we took a look at the ways a number of prominent research projects are gaining benefit from the big data technology stack. The complete insideBIGDATA Guide to Scientific Research is available for download from the insideBIGDATA White Paper Library.
 Primary Motivators of Big Data vis-à-vis Scientific Research
Primary Motivators of Big Data vis-à-vis Scientific Research
With all of the discussion about big data these days, there continues to be frequent reference to the 3 V’s that characterize big data: Volume (size of the data set), Velocity (rate at which data is generated), and Variety (types of data collected). These representations of big data are familiar to most researchers, however, they still are useful when assessing the important benefits brought to the table. Most researchers in scientific areas agree that the complexity of the data and its relationships are truly the biggest challenges at all scales and in most applications.
To illustrate how one high-profile, large-scale scientific research project has engaged the primary tenets of big data technology, let’s consider the Large Hadron Collider (LHC), the world’s premiere particle accelerator located at CERN (Conseil Européen pour la Recherche Nucléaire). CERN is the laboratory, and the LHC is the machine, near Geneva, Switzerland. As the most complex scientific human endeavor ever attempted, LHC is representative of a scientific research project with a strong international collaboration. The goal is to smash protons moving at 99.999999% of the speed of light into each other. The beams of protons collide in four experiment points, each collecting big data class data: Alice, ATLAS, CMS and LHCb.
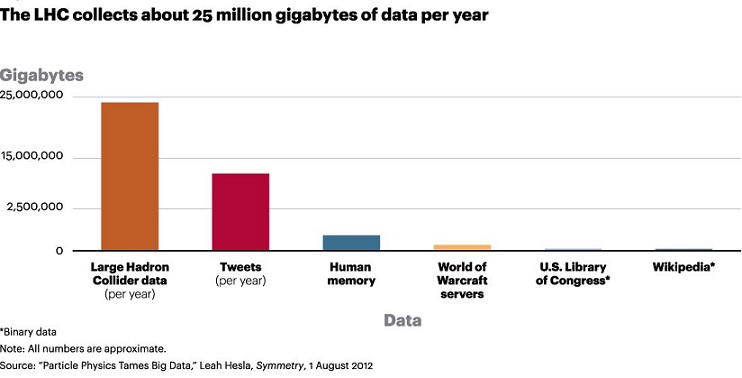
After a 3 year run beginning in September 2008, the LHC confirmed the discovery of the elusive Higgs boson. The accelerator was shut off on February 14, 2013 and then underwent a 2 year retrofit in order (TeV). During 2012, the LHC collected 30 petabytes of data (about 100 terabytes per day during normal operation), for a total of 100 petabytes since inception. As of June 3, 2015 the LHC is now back in full operation.
CERN uses Apache Hadoop for storing the metadata of the experimental LHC data. The data is supported by 3 HBase clusters. The LHC experiment is a good example of big data 3 V’s in the following ways:
- Open accessibility of data
- Volume of data
- Data transported in real-time for analysis
- Long term data retention
- Data is semi-structured
 An important tool at LHC visualizes the real-time transfers of data in the Hadoop Distributed File System (HDFS) system. Called HadoopViz, this visualization technology shows all packet transfers in the HDFS system as raindrops arcing from one server to the other. The figure below shows a collection of displays in the LHC control center—the Hadoop status page as the screen in the top-right, and the HadoopViz Visualization of Packet Movement as the screen in the bottom-right.
An important tool at LHC visualizes the real-time transfers of data in the Hadoop Distributed File System (HDFS) system. Called HadoopViz, this visualization technology shows all packet transfers in the HDFS system as raindrops arcing from one server to the other. The figure below shows a collection of displays in the LHC control center—the Hadoop status page as the screen in the top-right, and the HadoopViz Visualization of Packet Movement as the screen in the bottom-right.
If you prefer, the complete insideBIGDATA Guide to Scientific Research is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of Dell and Intel.



Speak Your Mind