This article is the third in an editorial series with a goal to provide a road map for scientific researchers wishing to capitalize on the rapid growth of big data technology for collecting, transforming, analyzing, and visualizing large scientific data sets.
In the last article, we took a look at the primary motivators for scientific researchers to engage the big data technology stack. The complete insideBIGDATA Guide to Scientific Research is available for download from the insideBIGDATA White Paper Library.
 Big Data Technology for Scientific Research
Big Data Technology for Scientific Research
The continued and rapid evolution of big data technology and services has formed a fertile foundation for scientific applications in the past several years. We’ve seen big data hardware and software solutions promulgate access to analytics and methods of statistical learning like never before. And one thing researchers have learned along the way is that management of computing resources is one of the primary questions to be answered with big data. It is not just a case of determining the scale of resources needed for a project, but also how to configure them, all within the available budget. For example, running a large project on fewer machines might save on hardware costs but will result in a longer project timeline. In some cases, scientific big data are being stored in the cloud instead of on conventional hardware in a research lab. Instead of having to invest in the infrastructure of an on-premises High Performance Computing (HPC) cluster to analyze the data, some researchers are using HPC and big data methods in the cloud. The disadvantage of the cloud is that large data sets must be transferred to cloud storage.
In this section we’ll examine specific areas of big data technology that scientific researchers are deploying in order to see significant increases in their ability to manage the scientific data deluge.
Colliding Worlds of HPC and Big Data
In order to address the needs of data-centric scientific research projects, the profiles of traditional HPC and big data are merging and becoming closely intertwined. The compute nature of HPC is finding significant benefit from big data analytics and its ability to process high volume, high velocity data sets. The current most effective software platform for big data analytics—Hadoop —has its classic architecture consisting of HDFS and MapReduce, running on commodity cluster nodes, and the HPC environment has a different architecture where compute is distinct from the storage solution. You’d like to leverage your current investment in HPC by doing big data analytics on the architecture you already have. This is where two worlds come together.
An area of scientific research that’s benefiting from HPC and big data merging is genomics. The advancement of this area of research depends on the availability of HPC because of the compute resources needed to process genomic data sets. But these problems also require solving big data issues like analyzing the data, making sense of what’s in the data, identifying what patterns emerge from the data, and more. Essentially, every aspect of what genomic researchers do is becoming an opportunity to capture, analyze and use big data. This is the same net effect seen from the perspective of many other scientific disciplines.
Data Sources and Data Integration
Scientific researchers routinely collect extremely large data sets, primarily for computational analysis with an HPC system. These data sets can also be analyzed with big data tools to look for valuable insights with data visualization tools or advanced analysis algorithms. The difference between HPC and big data analytics is primarily that HPC is CPU bound, whereas big data analytical problems are IO bound. As the two environments continue to merge, researchers can apply big data analytics against a primarily HPC data set without moving the data set from the HPC environment to a Hadoop Cluster with HDFS.
A paradigm shift in big data analytics relative to scientific research use cases, as well as other use cases where there is value from analyzing HPC data sets, necessitates a new direction away from the common HDFS architecture, and towards using MapReduce on the Lustre parallel file system. The Intel® Enterprise Edition for Lustre software unleashes the performance and scalability of the Lustre for HPC workloads, including big data applications becoming common within today’s research labs. Dell built the reference architecture where Lustre is used in place of HDFS. Further, Dell layers analytics on top of this architecture as well.
A key component to connecting the Hadoop and Lustre ecosystems is the Intel Hadoop Adapter for Lustre plug-in (Intel HAL). Intel HAL is bundled with the Intel Enterprise Edition for Lustre software. It allows the users to run MapReduce jobs directly on a Lustre file system. The immediate benefit is that Lustre is able to deliver faster, stable and easily managed storage for the MapReduce applications directly. A potential long term benefit using Lustre as the underlying Hadoop storage would be a higher raw capacity available when compared to HDFS due to the three time replication as well as the performance benefits of running Lustre on InfiniBand connectivity.
Researchers are interested in multiple additional classes of data sets. Many of them may be on premise and consist of multiple types of data. Other data sources may come from publicly available sites, or purchased from one of the many services that provide data sources to labs. Dell’s Data Integration Platform as a Service called Boomi could be used for such applications.
Hadoop
The Hadoop distributed computing architecture increasingly is being deployed for scientific applications requiring big data capabilities, specifically managing, collecting and analyzing the data. Dell™ Apache™ Hadoop® solutions for big data provide an open source, end-to-end scalable infrastructure that allows you to:
- Simultaneously store and process large data sets in a distributed environment—across servers and storage—for extensive, structured and unstructured statistical learning and analysis
- Accommodate a wide range of analytic, exploration, query and transformation workloads
- Tailor and deploy validated reference architectures
- Reduce project costs
- Drive important insights from scientific data
Take the complexity out of analyzing research data sets. With Dell’s extensive Hadoop-ready library of analytics solutions, you can easily create “what if” scenario dashboards, generate graphs for relationship analysis and innovate over legacy systems. Dell has teamed up with Cloudera and Intel to provide the most comprehensive, easy-to-implement big data solutions on the market for research applications.
Dell’s tested and validated Reference Architectures include Dell PowerEdge servers with Intel® Xeon® processors, Dell Networking and Cloudera Enterprise. This broad compatibility can help your research group build robust Hadoop solutions to collect, manage, analyze and store data while leveraging existing tools and resources. The Intel® Xeon® powered Dell | Cloudera solution can give your research group everything it needs to tackle big data challenges including software, hardware, networking and services.
Spark
Apache Spark is another distributed processing environment that’s gained much interest in the scientific community. Spark is an open-source platform for large-scale distributed computing. MapReduce is a widely adopted programming model that divides a large computation into two steps: a Map step in which data are partitioned and analyzed in parallel, and a Reduce step, in which intermediate results are combined or summarized. Many analyses can be expressed in this model, but systems like Hadoop have key weaknesses in that data must be loaded from disk storage for each operation, which can slow iterative computations (including many machine learning algorithms), and makes interactive, exploratory analysis difficult. Spark extends and generalizes the MapReduce model while addressing this weakness by introducing a primitive for data sharing called a resilient distributed data set (RDD). With Spark, a data set or intermediate result can be cached in the memory across cluster nodes, performing iterative computations faster than with Hadoop MapReduce and allowing for interactive analyses.
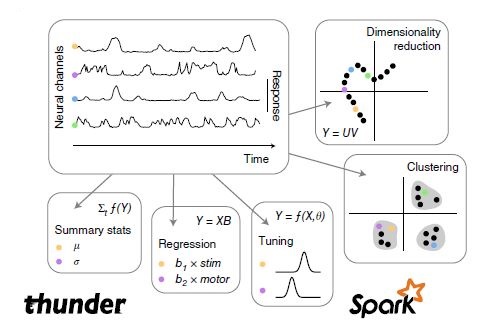
One example of a research project taking advantage of Spark is the Howard Hughes Brain Institute. The project’s goal is to understand brain function by monitoring and interpreting the activity of large networks of neurons during behavior. An hour of brain imaging for a mouse can yield 50-100 gigabytes of data. The researchers developed a library of analytical tools called Thunder which is based on Spark using the Python API along with existing libraries for scientific computing and visualization. The core of Thunder is expressing different neuroscience analyses in the language of RDD operations. Many computations such as summary statistics, regression and clustering can be parallelized using MapReduce.
 Statistical Analysis Software
Statistical Analysis Software
The scientific community is fortunate to have many quality statistical environments and analytics tools with which to use for developing analytical pipelines that connect data to models and then to predictions—SAS, SPSS, Matlab and Statistica. On the open source front, many researchers employ tools like R and Python—each containing vast libraries of statistical functions and machine learning algorithms.
It is important to transform complex and time-consuming manipulation of scientific data sets into a fast and intuitive process. Statistica Big Data Analytics from Dell combines search and analytics in a single, unified environment. Statistica is an advanced content mining and analytics solution that is fully integrated, configurable and cloudenabled. It deploys in minutes and brings together natural language processing, machine learning, search and advanced visualization.
If you prefer, the complete insideBIGDATA Guide to Scientific Research is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of Dell and Intel.



Speak Your Mind