Industrial environments such as those found within large electric and gas utilities are producing massive volumes of data in real-time that is overwhelming traditional ICT architectures. Additionally, the variety of operational data generated in industrial environments is orders of magnitude more complex than what is typically found in ICT environments. With the ever-increasing number of connected devices, sensors and network systems throughout industrial environments, these organizations are often struggling to integrate millions of unstructured data streams from disparate sources, trapped in siloed legacy systems, all in different formats. All this data can be a valuable resource for driving operational efficiency and coping with transformational changes, but only if it can be transformed into actionable insights and meaningful intelligence.
Many open-source architectures such as Hadoop data lakes, Storm, and even data warehousing methods have been touted as solutions to these types of “Big Data” challenges. However, these approaches alone simply cannot handle the scale and complexity of industrial data, or provide real-time analysis and situational awareness. Without the ability to integrate the raw data into a common model and gain a holistic view of the big picture and potential risks in real-time, industrial enterprises are struggling to achieve operational and business benefits from the sensor technology and data integration and management architectures they have implemented. Hadoop may work in many businesses, but it simply cannot handle the massive amount of data generated in industrial environments. It simply wasn’t built for it.
Solving this data challenge requires a new thought process and approach, including a new purpose-built architecture for industrial infrastructure, communications and storage.
Hadoop is inherently a batch-oriented system and has limitations, particularly when organizations’ needs are increasingly mandating real-time operations. Batch jobs are used to scan data that matches the query, return distributed results and allow a process to feed the results back to the calling system such as HBASE. This also means that data from the field has to be collected in a centralized lake – even before analytics can be tapped. The underlying batch process can mean scalability but does not necessarily offer the real-time results and performance required for guaranteed results, and any insights are discovered far from the parts of the network that are actually involved In the process.
For real-time data processing and analytics, Apache Storm provides streaming capability for ingesting data into the Hadoop system. However, Storm is a framework that requires development for data handling/processing – development that requires time and resources to implement, test and deploy each and every process. This additional provisioning becomes particularly burdensome in attempts to scale and automate future processes.
In short, Hadoop is a good data infrastructure component for handling the I/O requirements for massive volumes of data and for the demands of large data scans, but falls short compared to a data architecture that can make complex decisions without reliance on a centralized data lake and can make real-time decisions from processes running on the very edge of the network.
We recommend industrial organizations implement a layered architecture that is purpose-built and incorporates data stores, data indexing and data analytics. It should be flexible enough to allow for new use cases and future requirements including functional and performance scalability.
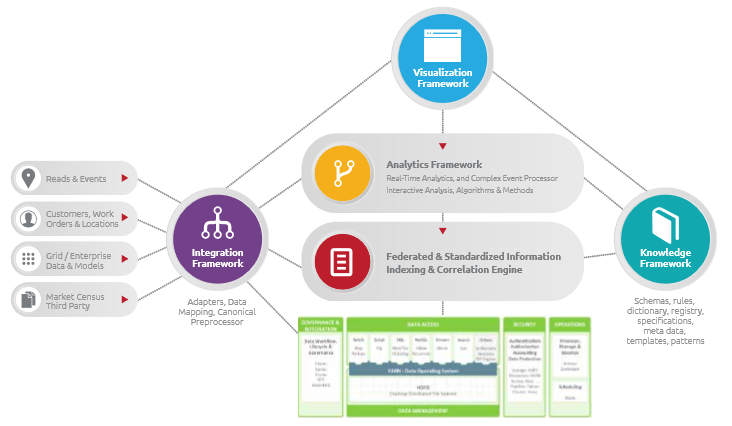
This diagram illustrates the recommended architecture, which includes a software platform leveraging a semantic data model layered on top of a Hadoop-based data lake. With this layered approach, the architecture provides key framework elements for integration, analytics, knowledge and visualization as well as a critically important information-indexing layer that uses a power semantic model. The base of the architecture includes a Hadoop infrastructure that provides flexibility and scalability for raw and processed data storage. This layer includes a HDFS platform for scaling the data storage aspects as well as data layers for structuring and organizing information such as HBASE and HIVE.
Key Architecture Points
The Hadoop infrastructure is a base solution for the data lake, providing scalability with raw storage of data, flexible layers of structure, and data typing. HBASE is recommended for its column wide and massive data storage and data analysis capabilities, but care is recommended for the HBASE data structure and approach to data retrieval. For industrial environments, the import of the data into the system is of critical importance. It is best to use a data ingestion method with semantic modeling (outlined in greater detail below), along with power indexing methods for fast data retrieval. HIVE can be layered in separately and as needed for more common SQL-like access to data for relational purposes.
The Federated and Standardized Information Indexing layer is provided by the semantic data model layer and utilizes a highly distributed and scalable indexing approach based on Elastic Search and Lucene. The indexing normalizes the information for analysis and retrieval and allows for rapid access to data within the data lake and is mandatory for fast access during analytics and operations. Without an indexing method, the data lake would rely on limited primary keys or full data scans for data retrieval.
The addition of the software platform leveraging the semantic data model enables industrial organizations to efficiently structure the indexes and create a dynamic adaptive approach to information indexing. Indices will vary and change as necessary and is easily accommodated as an independent layer from the data storage. In this case, re-indexing is a process that is easily accommodated based on business requirements and layered in effectively rather than brute-forced after the fact. Data mapping, modeling and ingestion methods are based on common semantic models.
Integrating the Right Data to Remove Interpretation and Create Automation
For industrial environments, we recommend a process for ingesting data into a Hadoop infrastructure that leverages semantic modeling capabilities for fast data integration. This not only ensures that the data lake is populated intelligently, but allows for changes and adaptations at a later time. This gives industrial organizations the ability to process business rules at-speed for: data quality checks; data transformation; and other data processing requirements. It also allows for semantic modeling and mapping of information from source to target and to handle normalization and de-normalization activities automatically.
Without a semantic data model there is little a machine can use to baseline data and thus becomes reliant on human interpretation. The human element can be inconsistent and is a time-consuming hindrance when the ultimate goal for these processes should be increased automation resulting in more efficient operations; or, software defined operations through a semantic data model.
By leveraging a software platform with semantic data modeling with their Hadoop architecture, industrial organizations can more quickly integrate extremely large volumes of operational data from a variety of disparate sources, correlate that data into a common data model, and apply predictive analytics and machine learning at the edge to derive actionable intelligence in real-time. Gaining actionable insights from large volumes of unstructured data enables utilities to improve power distribution, lower operational costs, proactively identify and address risks, and accommodate new distributed energy resources.
 Contributed by: Alex Clark, founder & chief software architect at Bit Stew Systems. Alex’s 15-year career has made him a seasoned data architect and leading expert in web service technologies, global class computing, and building high-performance, secure, scalable and distributed architectures. He is responsible for developing the initial software that has evolved into Grid Director and is an expert in real-time systems and data integration.
Contributed by: Alex Clark, founder & chief software architect at Bit Stew Systems. Alex’s 15-year career has made him a seasoned data architect and leading expert in web service technologies, global class computing, and building high-performance, secure, scalable and distributed architectures. He is responsible for developing the initial software that has evolved into Grid Director and is an expert in real-time systems and data integration.
Download the InsideHPC Guide to Manufacturing



Speak Your Mind