
 In this special guest feature Tarun Thakur of Datos IO, discusses the changing nature of storage and recovery in a distributed database world. Tarun is a self-proclaimed product guy with a systems technology background, and the CEO and co-founder of Datos IO, which provides enterprise-class recovery tools for next-generation applications and scale-out databases to help organizations compete in today’s evolving economy.
In this special guest feature Tarun Thakur of Datos IO, discusses the changing nature of storage and recovery in a distributed database world. Tarun is a self-proclaimed product guy with a systems technology background, and the CEO and co-founder of Datos IO, which provides enterprise-class recovery tools for next-generation applications and scale-out databases to help organizations compete in today’s evolving economy.
Today’s enterprise data center is fast transforming into a data-centric world, one that supports the social, mobile, and cloud environments in which modern consumers live. Large-volume, high-ingestion, real-time data from various sources is becoming mainstream for enterprise applications—including new web-scale and distributed apps designed to help the enterprise gain deeper business insights from data and support new business investments in the Internet of Things (IoT), on-demand commerce, digital advertising, fraud detection, real-time analytics, and much more. And as a result, distributed databases such as Cassandra, MongoDB, Apache HBase, etc. and cloud databases such as Amazon DynamoDB, Amazon RDS, etc. have emerged to become new de-facto standards for these next-generation applications.
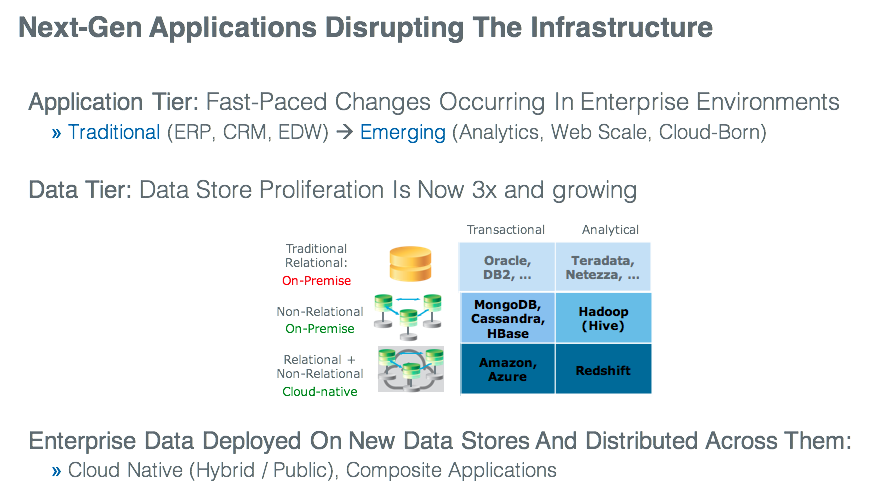
These distributed databases differ fundamentally from traditional databases in that they:
- Are de-facto standards for cloud, social, and mobile-based applications
- Are scale-out (eventual consistency) vs. scale-up (strong consistency) in nature
- Offer flexible data models (schema), for ease of application development
- Provide cross-data-center replication for application availability
- Create “elastic” infrastructures that grow or shrink per application or user growth
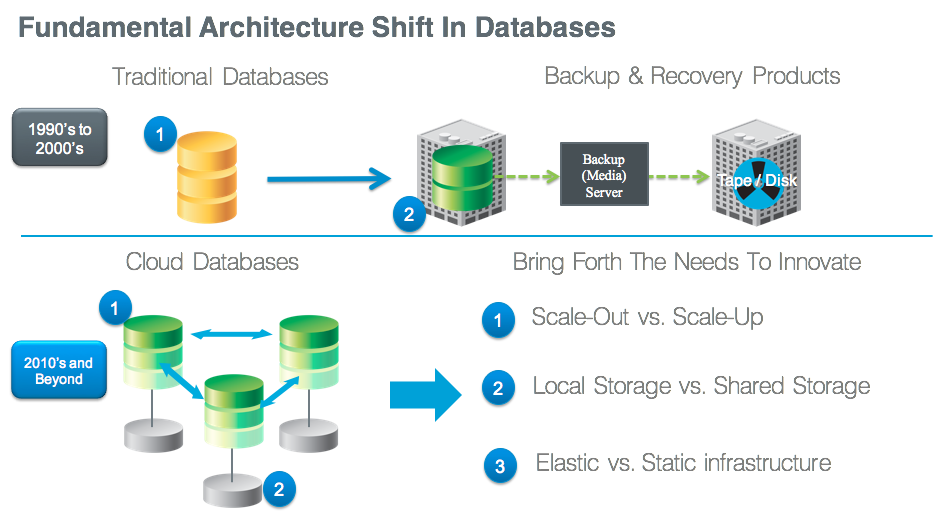
To innovate and compete in today’s economy, enterprises are being driven to adopt next-generation applications in support of these innovative business models. But while new scale-out databases permit the rapid development of these next-generation applications—they do so at a cost: the cost of application downtime, the cost of additional operational expenses required to create “hand-scripted” solutions, the cost of unreliable and non-scalable solutions based on “hand-scripted” solutions, and the cost of additional infrastructure that is needed to maintain and manage multiple of copies of data over the lifecycle of the data. And while the adoption of next-generation databases is rising, the full potential of enterprise-wide deployment is limited by the increased risk of data loss.
What’s at stake is the lack of viable and novel data protection or data recovery solutions for next-generation databases. No solutions (until now) have existed to allow for corrupted data to be removed, replayed, and propagated with minimal downtime to customer-facing applications. In addition, the entire landscape of recovery requirements has changed—all the way from “new” business needs to determine the value of data (driven by CIO/CTO needs), “new” product requirements (driven by the new owners of application architects), “new” users of recovery products (DevOps and DBAs) to “new” models of cloud-native deployment.
This said, these emerging scale-out databases do offer capabilities like cross data-center replication, but these properties address availability requirements only. They do not provide point-in-time versioning and recovery, so enterprises cannot go back and fix operational errors (for example, corrupted schema, “fat fingers”, etc). In fact, if errors are introduced, the databases’ redundant-node replication can lead to almost immediate corruption across all nodes of the enterprise’s data center.
In this data-centric world, traditional backup products are a misfit. Legacy backup recovery products: a) were designed for scale-up databases that reside on shared storage (SAN or NAS); b) use media-server based architectures that lose the value of metadata with non-native formats of databases; c) address the requirements of storage admins or backup admins, and d) store backups on classical media like tapes and disk.
This static, confined legacy construction is at complete in odds with the new recovery requirements and new users (database admins and DevOps) of today’s data-centric infrastructure. The old guard is unable to provide even the most basic operational recovery solution for next generation applications and distributed databases.
So, why the desperate need for enterprise-grade next-generation data protection and data recovery products? In a nutshell, it’s because our data-centric world is increasingly driven by next-generation applications and distributed databases, yet traditional backup applications can’t be relied upon to deliver the vital “live” access and recovery that today’s enterprise needs. As next generation databases make their way from test/development environments into production and mission critical environments, the necessity for backup and recovery will become paramount, requiring novel, enterprise-grade and most importantly—reliable and scalable—data recovery solutions.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind