
 In this special guest feature, George Demarest, Director of Solutions Marketing at MapR Technologies, traces through the history of computing architectures and concludes that the “converged data center” is the ultimate panacea we’re all looking for in terms of the format, speed, and context needed to drive rapidly evolving applications and analytics. George Demarest is a technology industry veteran with stints as a software engineer, technical marketer and marketing strategist for companies such as AT&T Bell Labs, UNIX System Labs, Oracle and EMC. For the last 15 years, he has worked on all aspects of outbound marketing and go-to-market activities for enterprise technology platforms such relational database, cloud computing, technology architecture and Big Data. He has worked extensively with CIOs and IT leadership to promote IT Transformation, ITaaS and service oriented data center operations.
In this special guest feature, George Demarest, Director of Solutions Marketing at MapR Technologies, traces through the history of computing architectures and concludes that the “converged data center” is the ultimate panacea we’re all looking for in terms of the format, speed, and context needed to drive rapidly evolving applications and analytics. George Demarest is a technology industry veteran with stints as a software engineer, technical marketer and marketing strategist for companies such as AT&T Bell Labs, UNIX System Labs, Oracle and EMC. For the last 15 years, he has worked on all aspects of outbound marketing and go-to-market activities for enterprise technology platforms such relational database, cloud computing, technology architecture and Big Data. He has worked extensively with CIOs and IT leadership to promote IT Transformation, ITaaS and service oriented data center operations.
The modern computing paradigm began with a completely converged data center: the mainframe. As soon as the required compute capacity exceeded the largest mainframe, distributed computing was born. What started as Sun Microsystem’s notion that “the network is the computer” now implies that the cloud—public, private or hybrid—is the computer; a fantastically complex, powerful, and mammoth computer. But that computer is incomplete, because it is not yet the completely integrated, boundless, or frictionless application and data platform that one would get from a “limitless mainframe.”
That is the direction the software industry, and open source software movement, has been heading since the network became the computer: the converged (virtual) data center. You can tick off a progression of technologies that enable the converged data center: a common microprocessor architecture (x86), an open source server operating system (Linux), an open source way to converge server instances (Xen/KVM hypervisor), an open source containerization of applications (Docker/Mesos) and a way to store and manage data at a vast scale (Hadoop). You can add software-defined networking, database services (SQL/NoSQL), application execution engines (Spark, Elastic, MapReduce), and a management harness (OpenStack) to more or less complete the picture.
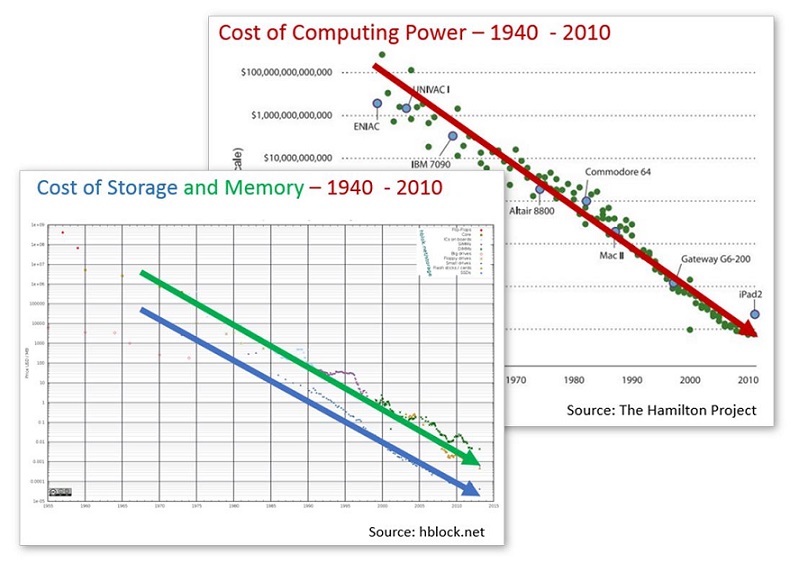
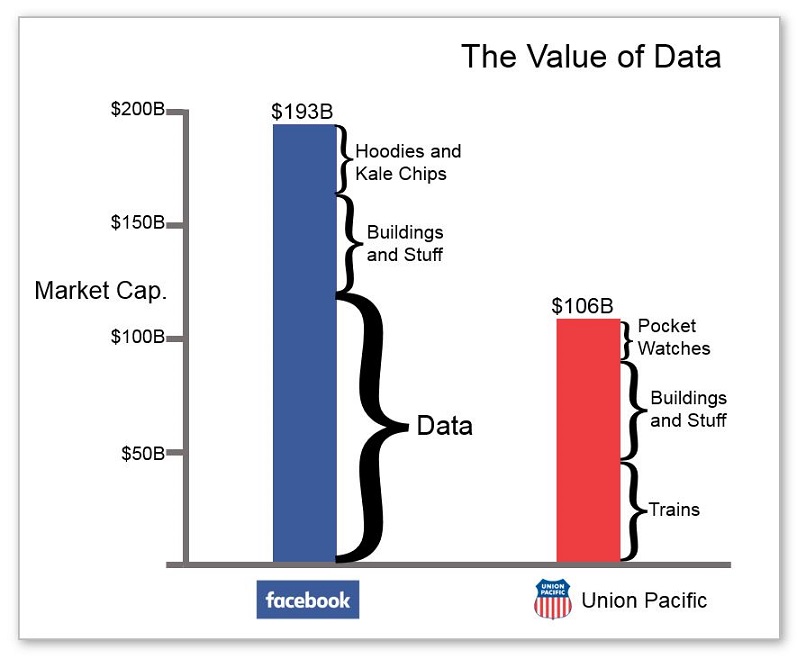
At the same time, the economics of computing have completely changed. The cost of compute, memory, and storage continues to drop, and the value of data—though hard to measure—has clearly skyrocketed. Entire industries have sprung to life or have been transformed by data, such as advertising technology firms, financial data vendors, and social media data providers. Many industries simply cease to function without reliable access to their data assets. Another indicator of the value of data is reflected in the market valuation of a data-driven company like Facebook ($180B), which is almost double that of Union Pacific that, it must be said, has a lot of cool, expensive trains.
So, when a freely available big data management system emerged (Apache Hadoop), it seemed like we had data convergence covered. However, it has become clear that Hadoop on its own will not serve as a master data repository for the enterprise. Why? Because Hadoop—and more specifically the Hadoop Distributed File System (HDFS)—does not provide native support for all enterprise data. HDFS does not manage NoSQL data, event streaming, or files (which is a little ironic for something with “FS” in the name). So, you end up with massive amounts of data in a Hadoop cluster, massive amounts of data in a NoSQL database cluster (MongoDB, Cassandra, etc.), massive amounts of data-in-motion in your streaming (Kafka) cluster, and massive amounts of files in a filer or file system; a new set of technology silos that must be negotiated by IT ops, architects, and developers.
While IT organizations are able to cope with these silos, many IT leaders must feel like it’s deja vu all over again. The leading Hadoop vendors (Cloudera, Hortonworks, and MapR) are each taking unique steps to address this issue. Cloudera relies on HDFS/Kudu for data management, HBase as their in-Hadoop NoSQL solution, Kafka streaming data on a separate cluster, and file data on filers or server file systems. Hortonworks’ “Connected Data Platforms” offer separate but connected clusters for data-in-motion and data-at-rest, and rely on HBase for NoSQL, while files are managed by other file systems. MapR offers the MapR Converged Data Platform that natively supports files, NoSQL tables, JSON documents, and event streams on the same cluster.
IT architects are keeping an eye on the horizon for signs of the converged data center. They want a complete three-dimensional view of all of their data that can be served up seamlessly and automatically in the format, speed, and context needed to drive their rapidly evolving applications and analytics portfolio. That converged data center may be a decade away, but data convergence has already begun.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind