As the big data hype recedes, companies face the stark realities of their Hadoop clusters and have a looming question: how to best use them? Odds are, departments who made an early commitment to Hadoop may be looking for better ways to manage the clusters or derive more business value out of them. The challenge is that while Hadoop is a powerful technology, the ecosystem around it is still lagging and, at times, misunderstood.
Hadoop has many advantages and can play a very important role in a company’s Modern Data Architecture, especially as a functional data lake. The data lake concept is particularly powerful as it allows businesses to create a centralized point of data ingestion. The catch is finding the right technologies to take that data lake and move it one step further into a data quality lake or even a master data management lake.
By design, the data must come into a central repository where the data is parsed, cleansed, completed, matched and mastered. This allows the Hadoop environment, with all of its associated flexibility, to become the source of high speed canonical data.
This idea of the data lake as a Master Data Management (MDM) hub is not new and, frankly, it’s truly the goal for it. However, until now the tools to get there have been lacking. Many of the big players cannot operate easily in and around Hadoop due to their reliance on Hive, which then uses Tez to eventually pull the data out of HDFS for processing.
The madness of this Hive-reliant MDM approach is that is defies one of the very basic tenants of Hadoop: bring the work to the data rather than bringing the data to the work.
Because of this, none of the major providers have the functionality needed to deliver on the promise of Hadoop. Worse, those that attempt it through this process commit to lengthy timeframes in delivering Hadoop-ingested data. The graphic below courtesy of Intel outlines how this approach tends to look.
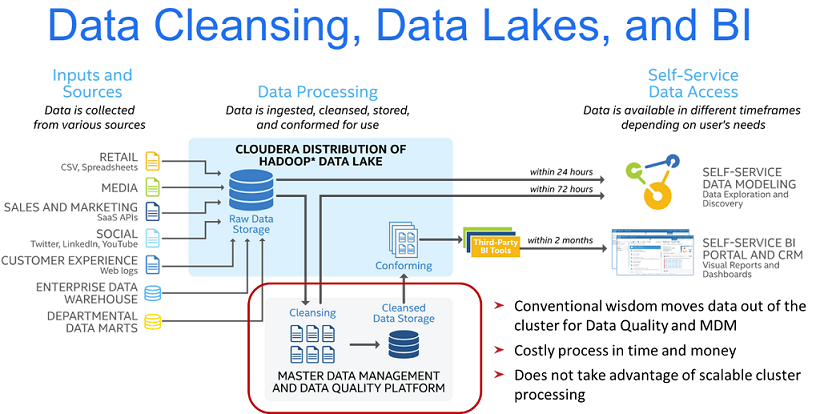
Skip Hive and Get Straight to Business
Consider taking a different approach to the problem, one that is direct, native and unique to Hadoop integration. At RedPoint, we’ve leveraged its existing distributed processing and highly-parallelized architecture to integrate directly with YARN and inject executables directly into Apache Hadoop HDFS. This is done without a shred of MapReduce, Hive or any other code. In fact, the only code that runs is RedPoint code, under the auspices and direction of YARN. Thus the operations are balanced against other workloads in Hadoop, the code is only distributed to the nodes that contain the data in scope for a given job, and YARN promptly evaporates our code once the processing is complete.
Skipping Hive is unique to the market and has multiple implications, the most important of which is that the data does not need to be structured into the tabular data Hive requires. It does all of the data quality and MDM processing against the Hadoop native data (at the data document level). In addition, the work (or code) is moved to the data rather than the data being moved to the code.
Together these performance characteristics yield a highly-performant platform that can process data immediately upon ingestion and have canonical data available for consumption across the enterprise in minutes rather than hours and months. We’ve seen the results customers can achieve using this approach, and it’s surprising more companies don’t architect without Hive reliance.
What about Spark?
Spark is currently on fire. Part of it is due to its performance profile and part because it is a better development environment than the native MapReduce that is part of Hadoop. However, Spark is still code and suffers from the same ills that all code-based solutions suffer from. Code-based solutions are only as good as your coders. Inherently, this means that your solutions and their quality are inconsistent (a fact that enterprises hate). Secondly, regardless of the quality or speed of your coder, it would take minimally months or years of a team of coders to develop robust data quality or MDM functionality in Spark. Data quality and MDM are complex processes that take years to develop and optimize. Nobody wants to wait that long, particularly when attractive alternatives already exist. Full data management is not likely to be re-developed in Spark any time soon.
Furthermore, there is the question of scale. Not the scale out of the solution but the scale out of the technology. As long as the processing is code based, there will be processing bottlenecks as only a limited set of elite users will be able to build, modify and run these processes. Thus many of the early adopting companies are left with the problem of enabling a broader use of the technologies to get better ROI but are limited by required skills that are hard to find and expensive when found.
No specialized coding required
RedPoint Data Management brings a broad feature set that enables data managers to span the spectrum of data processing needs from ingestion and ETL to data quality to MDM and all of it running natively in Hadoop (through YARN). More importantly, however, it does so in a scalable fashion. The jobs themselves are scalable from a technical perspective but they are also scalable form a skills or human perspective. Since this is a full drag and drop UI with no coding required, a standard DBA, business analyst or statistician can be trained on it.
Why does this all matter?
It matters because Hadoop technology has many benefits and the data lake approach enables a level of agility that is new for data processing. Further as we bring computing closer to the “edge,” the tools needed to develop precisely matched, clean and auditable data are less frequently in central IT and more frequently out in the business units where the technical skills are not as deep. Further, as we continue to evolve with the world of IoT, these needs will grow as the data volume and velocity grow exponentially.
Hadoop does have the potential to be the central point in an actionable, canonical, high-speed data lake provided companies can put the right tools in place. This enables the data lake to deliver fresh, linked, formatted data for consumption within minutes of ingestion, as needed. Not only is this a better performing, faster and more flexible environment for analytics, but also opens up the process to the business users who need it most.
And that gives business the true value of Hadoop.
 Contributed by: George Corugedo, CTO at RedPoint Global, Inc. A mathematician and seasoned technology executive, George Corugedo has more than 20 years of business and technical expertise. As co-founder and CTO, George is responsible for leading the development of the RedPoint’s technology products. A former math professor, George left academia to co-found Accenture’s Customer Insight Practice, which specialized in strategic data utilization, analytics and customer strategy. Previous positions included Director Client Delivery at ClarityBlue, Inc., a provider of hosted customer intelligence solutions, and COO/CIO of Riscuity, a receivables management company specializing in the utilization of analytics to drive collections.
Contributed by: George Corugedo, CTO at RedPoint Global, Inc. A mathematician and seasoned technology executive, George Corugedo has more than 20 years of business and technical expertise. As co-founder and CTO, George is responsible for leading the development of the RedPoint’s technology products. A former math professor, George left academia to co-found Accenture’s Customer Insight Practice, which specialized in strategic data utilization, analytics and customer strategy. Previous positions included Director Client Delivery at ClarityBlue, Inc., a provider of hosted customer intelligence solutions, and COO/CIO of Riscuity, a receivables management company specializing in the utilization of analytics to drive collections.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind