 While at Hadoop Summit 2016, I had the opportunity to catch up with Matthew Morgan, Vice President, Product and Alliance Marketing at Hortonworks, to discuss all the progress the company has made in the past year. In this role, Matt oversees product marketing, industry vertical marketing, solution marketing, technical marketing, global sales enablement, alliance marketing, partner marketing and overall product launch governance. Also present at the briefing were Wei Wang, Senior Director, Global Project Marketing, and Michelle Lazzar, Director of Communications.
While at Hadoop Summit 2016, I had the opportunity to catch up with Matthew Morgan, Vice President, Product and Alliance Marketing at Hortonworks, to discuss all the progress the company has made in the past year. In this role, Matt oversees product marketing, industry vertical marketing, solution marketing, technical marketing, global sales enablement, alliance marketing, partner marketing and overall product launch governance. Also present at the briefing were Wei Wang, Senior Director, Global Project Marketing, and Michelle Lazzar, Director of Communications.
Daniel D. Gutierrez – Managing Editor, insideBIGDATA
insideBIGDATA: It’s great to be attending another Hadoop Summit. Can you give me a 30,000 ft. view of what’s new at Hortonworks?
Michelle Lazzar: Sure, there have been a number of different things that have been going on. The main product announcement was Hortonworks Data Platform (HDP) 2.5. Earlier this year in March we revealed we were changing up the way that we deliver HDP to our customers. Previously we had been releasing it annually, with one big “everything” upgrade. We listened to our customers and what we found was customers want the rapid innovations from Apache. They want a stable core. So we’ve broken up the way we deliver HDP. We’ll continue to do those core updates annually for HDFS, YARN, MapReduce, and foundational elements of HDP. But we’re going to be rapidly giving extended services updates to our customers in dot releases for components like Hive, Spark, all of the engines, and all of the projects like Ambari, Ranger, Atlas, etc.
This means that as the Apache community updates and releases those projects, we’ll be able to give them to our customers more quickly, put them through our testing, but they won’t have to update everything because the core will still be the same. So you could actually run different versions of the Apache projects on top of the stable core.
We’ve also got some updates with HDP, primarily integration of security and governance which is something the customers have been really asking for and we’ve been working on for a while. Security governance with HDP 2.5 is the first piece.
We’re also are talking a lot about our relationship with Microsoft and we named Azure HDInsight as our premiere connected data platform cloud solution. We have worked with Microsoft for four years. HDInsight is built on top of HDP, and this is now our premiere data platform cloud solution, so when you go to our website under products you’ve got Hortonworks Data Platform, Hortonworks DataFlow for the Data Center, and then for cloud you can get HDInsight. We’ve been talking a lot about Microsoft and our partnership. We do joint engineering, and they’re our premiere sponsor here, so these are some cloud theme updates.
We also have an update to our partner program – we have a new managed service providers program. And we kicked off an initiative for genomics, where we’re working to create an open source genomics platform with Arizona State University, and Mayo Clinic, Yale New Haven Health, and Baylor College of Medicine and that’s along the lines of the precision medicine initiative that the Obama administration’s put out.
Matt Morgan: We have introduced an industry narrative around connected data platforms. It’s been a big push for us. We are clarifying a little bit about what that means. People are very interested in the fact that we have a Data in Motion and a Data at Rest solution. But what the connected data platform’s architecture truly refers to is the nature of how that data architecture needs to be laid out to facilitate these modern data apps. It’s very, very different than a lot of people initially perceive it to be. There’s a competing conversation in the industry around a “converged platform” — let me create one platform, and have everything stored in it. The reality is that these modern data apps like a connected car, or intelligent retail, or factories of the future, they can’t get away with a single platform.
The nature of the data and where it’s being generated requires that data to be analyzed at conception. The idea that these sensors can read an upcoming curve on the road; they need to be able to capture the insight associated with that curve and act on it, provide intelligence before the curve hits. They can’t send that to some converged platform back in a data center. They have to be able to act on it immediately. So, our view is that there are a lot of stakeholders, there’s a lot of data, it’s in motion and at rest, but the architecture that’s required is one that simultaneously branches from the cloud to the data center, and that data by itself in these modern data apps must truly be hybrid.
We also are articulating a name for what that’s called. That was the data lake, which is still part of the conversation for sure. But we see this as a “data plane,” reaching from the cloud to the data center, all the way from the end point, all the way to the data lakes that might be behind the firewall in your own data center, and of course in between. This data plane helps articulate the nature of data in the future, and the nature of the required data architecture when you’re dealing with these modern data apps. So, the innovations that we’re seeing on HDP 2.5, help provide better governance in this world, helps provide better security in this world. It gives us the capability to reach across boundaries to give you more assuredness that you’re managing the data appropriately. We’ve also innovated the operations side, giving you a single pane of glass to be able to manage your clusters. That was important. We innovated an integration between our instrumentation technologies, called Smartsense, which does proactive recommendation on how to maintain the health of your cluster.
insideBIGDATA: When you talk about data at rest, and data in motion (fast data) a lot of the discussion centers around performing analytics at the edge. There are a lot of people that say, “Well, it’s not really possible at this point.” In reality, what you’re talking about having is a powerful engine at the sensor level, e.g. a sensor on a farm tractor. So where is that analytics truly happening? What is the need for enrichment using data at rest to supplement what’s being captured at the sensor level? How do you see that scenario?
Matt Morgan: I think that the first thing to point out is you have to segment the insights. Complete historical insights being conducted at the edge is not a very realistic conversation today. Fully enriched with all the historical data, that’s not what we’re talking about. We’re talking about what we see as “perishable insights.” Insights that have immediate impact for tactical decisions that are being made in a certain condition. Whether I’m on the tractor, or I’m in a self-driving car coming up on a curve. These are the type of insights that can be acted on and are available. We have the technology to pull them from the sensors today.
I think the other piece that I want to articulate is there are other insights that aren’t the deep, rich historical ones that can be facilitated between the sensor and your data lake back in your data center. And that’s where the cloud computing world comes into play. Since most of the connections of the sensors are using LTE – open cloud-based connectivity – having the ability to have data lakes that sit in the cloud that can facilitate immediate machine-learning that’s required for an architecture is part of the solution.
Wei Wang: I want to make you aware of a couple of things about our data pull product that speaks about data at rest. I’m going to give you just an example of an oil rig and how the data flows. In an oil rig we are using Hortonworks DataFlow as a technology to basically collect the data. I came from the Business Objects world so I know BI. First you have to do ETL. When you load it in, you’ve already extracted which one you want to analyze on.
DataFlow can do some of that. First off, is picking and choosing what type of data you want from that oil rig, or tractor sensor to send it back to the edge of the data center to do analysis. The second is that the technology is robust enough and let’s say you only selected very few items of that data flow to send it back but you needed to go back in and get the data. For example the oil rig is now on fire, you say from this time period to this time period I want you to send me all the data you need. That’s also business analytics. You can go back in and actually collect that data immediately. I think that DataFlow truly has, to me as a technologist from the BI world, provided me the flexibility to extract the data and then later on be able to enrich it with data at rest. So you asked what kind of analysis needs to be done? I want to also point out that our DataFlow as a technology is not just used in IoT scenarios and many times that we could have also used it in the edge of the data center that to enrich, to basically do some analysis and helping to make sure that we get the right data flow and the right processing.
insideBIGDATA: Can you run you through what Hortonworks announced for data at rest, HDP 2.5?
Wei Wang: If I move from 2.5 to 3.0, there will be a lot of things that I’m packaging in on YARN, i.e. next generation YARN components which we’re going to package into HDP 3.0. We announced the Apache Atlas / Apache Ranger integration for unified Hadoop security and governance, and also Spark, Zeppelin (a completely open web-based notebook), Storm, HBase, Phoenix, and Ambari.
Let me run through the Atlas / Ranger Integration. In the figure below, Atlas will perform on the left and Ranger will perform on the right. Atlas is essentially is a data governance tool. Apache Atlas is an Apache project that allows the data store to tag all the data coming in using PII, that is you can tag where the data is located using a certain tag instead of using their IP addresses depending on where the data is generated.
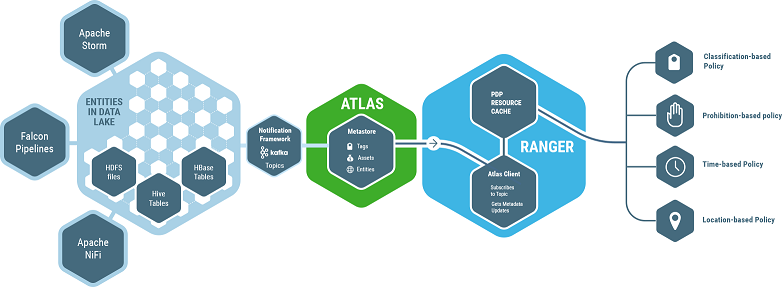
Now you categorize the metadata. Then you’re going to reinforce that based on Apache Ranger as a security tool – reinforce who can access based on the tags. So users belonging to marketing, for example, cannot access any data that is tagged with PII, etc. So the use case is very simple, basic tag policy, basic PII, or using IP addresses. For example, in Germany, I know that the rule is all the data has to processed, especially the vehicle data has to be processed within Germany. So when that piece of data moved from the data center in Germany to France, then you can’t process the piece of data. Financial services, trading data, you can only access the data from eight o’clock to 5:00pm. So if the data is being accessed after 5:00pm, then that’s not allowed. There’s also prohibition in US because there are the rural areas that you link people’s name with a zip code, then you actually know who they are. That’s not right. In certain circumstances, you cannot link them together. So those actually can all be defined as tags, and then Ranger will actually reinforce that. This is very unique to Hortonworks because there’s no one else doing anything this sophisticated for security.
insideBIGDATA: Can you tell me about what Hortonworks is doing with data lineage?
Wei Wang: Apache Atlas is Hadoop’s data governance tool that’s used at Hortonworks that allows for data lineage. Data cell lineage is very important. So we do Hive, Storm, Kafka and we can link to others through the connector, essentially any of the commercial databases, and the BI tools, as well as Teradata, we’ll have a Teradata connector.
There is also the business catalog, a metadata catalog, that’s also very important. This week a number of vendors all made announcements about Atlas integration: Waterline, Attivio and also Trifacta, a new BI tool they actually integrated with Atlas.
insideBIGDATA: What is Hortonworks doing with Spark?
Wei Wang: We’re now GA with Apache Zeppelin, a data science notebook, that you can use to do interactive data ingestion and data exploration. Actually, we’re using it internally. We’re working very hard to make sure it’s enterprise ready with security functionalities, so that now we have a single sign-on and also encryption built into it. It’s like a dashboard. There’s also Storm and HBase.
A lot of our customers are using Storm who request connectors for search. We now support both Elasticsearch and also Solr. We support Cassandra and Couchbase. And then for enterprise readiness functionality, we have Automatic Back Pressure which is very important when you run the data down the pipe and if you need to cache it up and make sure that allows empty time for processing. And we actually have Storm view in Ambari for basically describing and also configuring for Storm.
insideBIGDATA: What can you tell me about Hive and Hbase?
Wei Wang: Phoenix is the SQL skin for Hbase. 40% of our customers are actually using Hbase. I was at our customer advisory council Monday, and I combined Hive and Hbase. So I have Fortune 100 customers, four of them sitting at my table, and one is very heavy on HBase use cases and I said, “How many of you are interested in talking about Hive? And he replies, “I’m not interested, but I want to know about HBase.” And another other guy replies, “I’m such heavy Hive user. I don’t care about HBase.” So you can see there’s a variety of use cases or tools my customers are using with almost the same business use cases, but different tools.
So for this release, most of the work is done on the Phoenix side, so now you can curate the Phoenix tables in Hive so you can see the two are now somewhat connected. We have incremental backup and restore, which is important for petabytes of data – you don’t want to do the whole backup and whole restore, you want to do incremental, and also a performance boost for high-scale loads.
insideBIGDATA: Where do you stand with Ambari?
Wei Wang: We released our Phase 1 in the last release, with Ambari 2.2. Our customers who are using our current version of HDP already benefit from it. In the current release, HDP 2.5, we’re going to do the consolidate cluster activity reporting, and then we’re technical previewing something with log search which many of our customers are waiting for. Everything is pre-built, click of a button from Abari, and we have YARN, HDFS and HBase statistics for Hadoop operators. Those are done. Many of our customers want to know who are my top ten users, what are my top ten activities, which are the jobs that take the most time, and also if I need to charge back to individual departments who are all my customers. These are the services that we’re announcing right now. We’re using our own notebook to achieve that. And again, everything is pre-built that you essentially do not need to do any in-house development.
insideBIGDATA: There seems to be a lot of hype with LLAP. Can you drill down on that for me?
Matt Morgan: Sure, LLAP stands for “Live Long and Process.” This is all about speedy access. People want to have really rapid fire access when they’re trying to do ad hoc analytics. And look at the performance delta. This, by the way, before this was released, Hive was already setting benchmarks for SQL access with scale. Yeah, this is increasing it. I get really excited about speed.
This is a V8 engine all right, It’s got a turbo charger and headers out the back okay, so it’s ready to go. The thing is cutting time to response by an average of 65%, in some cases up to 95%. Minimal amount is 30%.
insideBIGDATA: What’s this I hear about a new MSP offering?
Matt Morgan: Right, as part of the Connected Data Platform strategy, we also introduced a whole new program around customers who want a managed service approach to their cloud. They have verticalized requirements. They want special needs boxes. They want specific performance needs. Sometimes it’s a lot easier than trying to going to the public cloud and just using the generic resources. I’m going to go out and buy my super scale machine, dedicate the process. I’m going to have it co-located at a Rack Space or something. We’ve got the opportunity for those partners to be an extension of our connected data platform strategy.
insideBIGDATA: In terms of new use cases, is there anything in the life sciences industry?
Michelle Lazzar: Yes, with genomics, it’s the start of a consortium, essentially, that we’re doing with a number of customers and companies. Arizona State University, which did a fine keynote with Dr. Ken Buetow talking about the kind of genomics based medicine for increasing the accuracy of mammograms. Along those same lines with the precision medicine initiative, that was the rallying call to basically have all these industries and technologies, areas, medical providers, the research guys, all come together to figure out what are the tools in the specialty areas that we can focus in, and how can we can together and really try to make progress here on solving genomics based medicine?
This consortium is actually meeting here at Hadoop Summit. They’re going to start the work here, and they’re going to first phase define what kind of platform and what kinds of requirements do even need to get this going. And open source is really the perfect thing to help with that. There’s a lot of Legacy tools that have to plug into something like this. We ran through some of the data governance requirements you have as well, especially in healthcare industry. So open source is a really great way to kind of start to build this. And so they’re going to look at what do you need on the research side, and what do you need on the pharmaceutical side, and then how does this work on the insurance side? We’re going to start that think tank work now, and then we’ll have more updates and progresses as that work goes along. But we’re just kicking it off now. And so it was great to have Arizona State University on stage today kind of talking about how they view some of those challenges and it’s all online with the work on the precision medicine initiative that we got involved with earlier this year. Our CEO went to the White House for the kick off of that which was pretty neat. We’re just beginning that here now.
The first phase in what they’re doing here is to all get in a room with Hadoop Summit as the backdrop, because obviously Hadoop is the force that’s going to play a huge part in what they’re doing. They’ve recognized that using legacy proprietary platforms is not going to give them the speed or flexibility or scale to solve a complex giant problem like genomics based medicine. You have to use open source, that’s kind of the only way to take on a problem this huge and this complex. So this is more about first defining what are the components that we need? What technologies do we need? What regulations are we up against? How can we break down the data silos and try to get all of our information together? So it’s just the scoping and defining is the first phase that they’re working on here.
insideBIGDATA: It’s interesting that they are here versus an HPC conference, which traditionally genomics research and so forth has traditionally been an HPC domain.
Matt Morgan: I think that there is a compute angle to this. But I think there’s a data angle that’s even bigger, and I think that the focus here is going to be how you deal with the data. And it’s not just the source data, it’s all the combinations and permutations on their analytics data. Yes, there is compute that’s associated with that, but even Hadoop’s got a compute role. We help take those workloads, we distribute them, you can maximize your commodity hardware, you can leverage the cloud, you have the ability to do that.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind