One of the newest techniques to detect anomalies is called Isolation Forests. The algorithm is based on the fact that anomalies are data points that are few and different. As a result of these properties, anomalies are susceptible to a mechanism called isolation.
This method is highly useful and is fundamentally different from all existing methods. It introduces the use of isolation as a more effective and efficient means to detect anomalies than the commonly used basic distance and density measures. Moreover, this method is an algorithm with a low linear time complexity and a small memory requirement. It builds a good performing model with a small number of trees using small sub-samples of fixed size, regardless of the size of a data set.
Typical machine learning methods tend to work better when the patterns that they try to learn are balanced, meaning the same amount of good and bad behaviors are present in the data set.
How Isolation Forests Work
The Isolation Forest algorithm isolates observations by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of the selected feature. The logic arguments goes: isolating anomaly observations is easier as only a few conditions are needed to separate those cases from the normal observations. On the other hand, isolating normal observations require more conditions. Therefore, an anomaly score can be calculated as the number of conditions required to separate a given observation.
The way that the algorithm constructs the separation is by first creating isolation trees, or random decision trees. Then, the score is calculated as the path length to isolate the observation.
In order to avoid issues due to the randomness of the tree algorithm, the process is repeated several times, and the average path length is calculated and normalized. It is shown that the average path length converges after a few iterations as shown in the following figure.
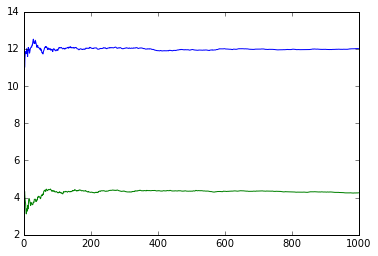
Comparison of Isolation Forest and One-Class Support Vector Machines
The Isolation Forest algorithm shows strong promise, and I tried to estimate its performance against the well-known One-Class Support Vector Machine outlier detection algorithm. First, I compare the two algorithms when the normal observations behave normally and belong to a single group.
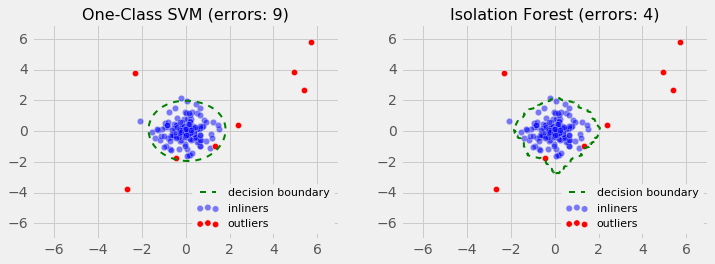
As observed, the Isolation Forest algorithm, detections have fewer errors, as it did not construct a parametric representation of the search space.
Lastly, I evaluated the performance using a slightly more complex case, when the observation is grouped in two uneven clusters.
Similarly to the previous case, the Isolation Forest algorithm performs better than the One-Class SVM.
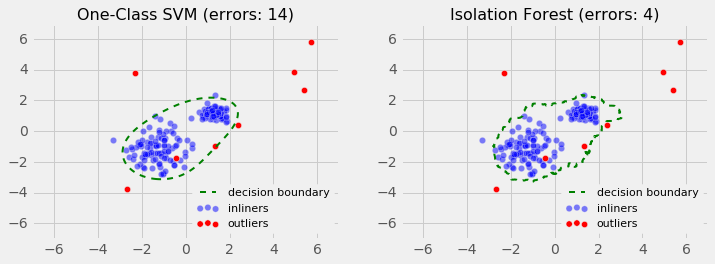
The Takeaway
The method of using Isolation Forests for anomaly detection in the online fraud prevention field is still restively new. It’s no secret that detecting fraud, phishing and malware has become more challenging as cybercriminals become more sophisticated. We should be using the most advanced tools and methods to prevent current and future fraud.
Advanced outlier detection methods such as Isolation Forests are imperative for companies looking to reduce fraud because this method detects anomalies purely based on the concept of isolation without employing any distance or density measure—fundamentally different from all existing methods.
As a result, Isolation Forests are able to exploit subsampling to achieve a low linear time-complexity and a small memory-requirement, and to deal with the effects of swamping and masking effectively. This gives us better tools to improve our detections rates and react faster to new fraudulent attacks.
 Contributed by: Alejandro Correa Bahnsen, Data Scientist at Easy Solutions. Alejandro has several years of experience in banking analytics, applying data mining models in a variety of areas from advertisement to credit risk. He holds a PhD in Machine Learning from Luxembourg University. Alejandro is currently working as Lead Data Scientist at Easy Solutions Inc, a security provider focused on the comprehensive detection and prevention of electronic fraud across all devices, channels and clouds. In this role, he is modifying state-of-the-art machine learning algorithms by adjusting them to the particularities of credit card fraud. He is also in charge of developing advanced machine learning models for intrusion detection, context-based user authentication and phishing classification. Bahnsen is also an experienced lecturer in econometrics, machine learning and business analytics.
Contributed by: Alejandro Correa Bahnsen, Data Scientist at Easy Solutions. Alejandro has several years of experience in banking analytics, applying data mining models in a variety of areas from advertisement to credit risk. He holds a PhD in Machine Learning from Luxembourg University. Alejandro is currently working as Lead Data Scientist at Easy Solutions Inc, a security provider focused on the comprehensive detection and prevention of electronic fraud across all devices, channels and clouds. In this role, he is modifying state-of-the-art machine learning algorithms by adjusting them to the particularities of credit card fraud. He is also in charge of developing advanced machine learning models for intrusion detection, context-based user authentication and phishing classification. Bahnsen is also an experienced lecturer in econometrics, machine learning and business analytics.
Sign up for the free insideBIGDATA newsletter.



Hello! Is it possible to see on the source code?
By any chance can we get the source code.
Here is an example of using Isolation Forests:
http://laranikalranalytics.blogspot.com/2019/05/using-r-and-h2o-isolation-forest-to.html