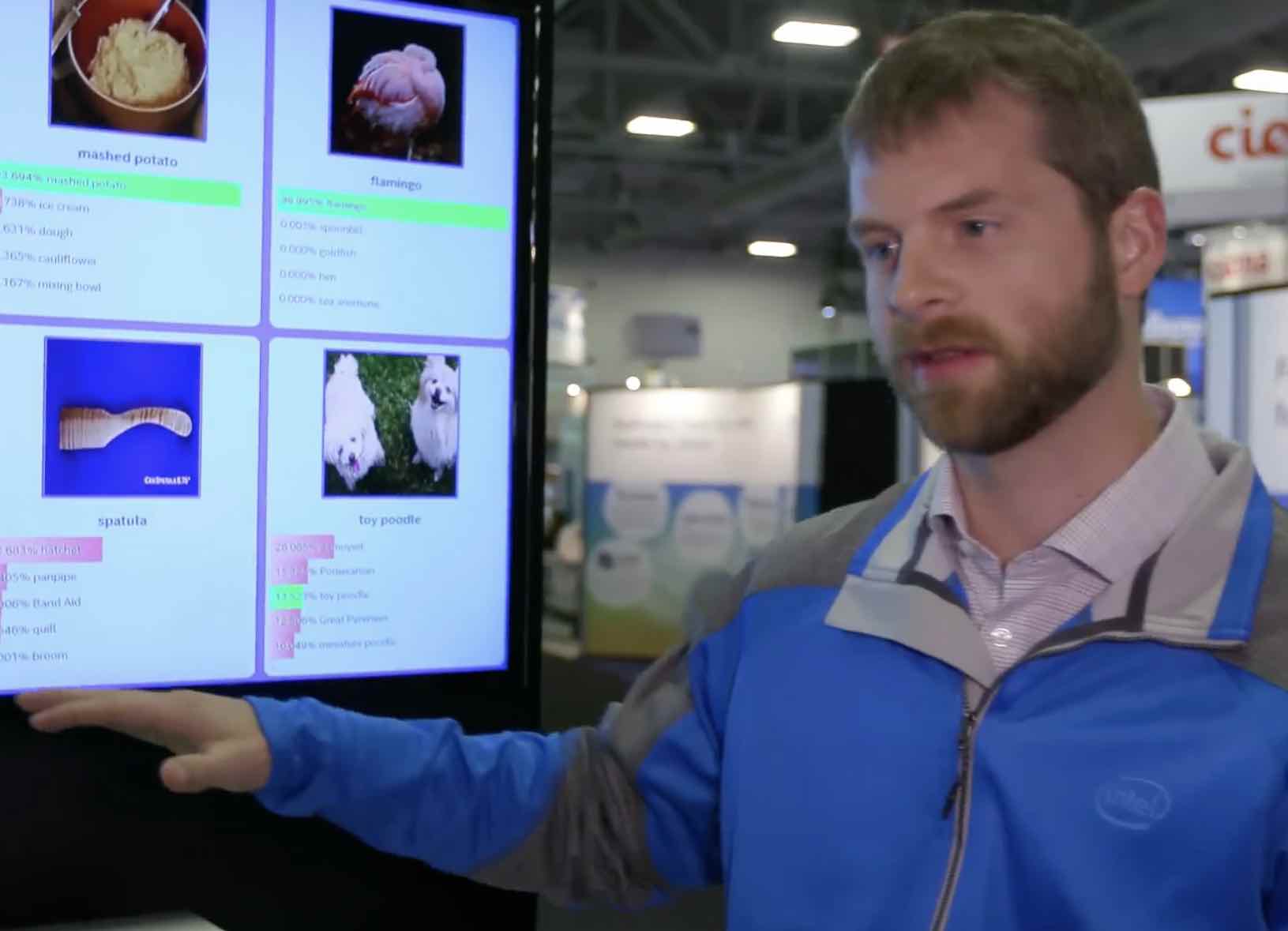
 In this video from SC16, Intel demonstrates how Altera FPGAs can accelerate Machine Learning applications with greater power efficiency.
In this video from SC16, Intel demonstrates how Altera FPGAs can accelerate Machine Learning applications with greater power efficiency.
The demo was put together using OpenCL design tools and then compiled to FPGA. From an end-user perspective, they tied it together using Intel MKL-DNN with CAFFE on top of that. This week, Intel announced the DLIA Deep Learning Inference Accelerator that brings the whole solution together in a box.
“Today, one of the most popular machine learning methods is using neural networks for object detection and recognition. Neural networks are modelled after the brain’s interconnected neurons and use a variety of layers that extract lower levels of detail for each layer in the network. The FPGA implements these layers very efficiently because the FPGA has the ability to retrieve the data and perform classification in real time. By leveraging 8 TBps of on-die memory bandwidth and minimizing the need to interact with external memory, designers can leverage the flexible FPGA architecture to obtain very power efficient implementations. FPGAs can also efficiently move data in and out of the network directly to classify in-line video, signal, or packet processing.”



Speak Your Mind