
After a data science team has finished building a hopefully pristine data model, you might be left having some of these very natural questions:
What is our processing model?
What are our performance characteristics?
How do we refine our models?
Who does the work?
Training models thrives on large batches of data and, while performance is very important to address processing needs, no one has expectations that the training is instantaneous. Models are often refined rapidly with a focus on experimentation. Primarily, data scientists are performing this work, lovingly cleaning their samples and elegantly attaining algorithmic excellence.
When we’d like to score streaming inputs with these models, things change. Now, we need to deal with samples at a very fine granularity and expect a near-immediate response. This is analogous to deploying a traditional application in production, so experiments in this phase are targeted at concerns that are ancillary to the data science process. This is the job of dedicated engineers, carefully crafting the code and wrangling the rigmarole of getting it where it can do useful work.
So how do we move our analytics from training to scoring? There are a few methods in practice. One way is to have data scientists produce analytics on their platform of choice and have engineers figure out how to get it directly into production. This method tends to be rather difficult to support and scale. Another way is to task the engineers with translating the analytics output into a separate production environment (often using another language entirely), and then do even more work chasing the inevitable bugs from the translation process. Clearly, neither of these are ideal. What we need is a way to programmatically express the models in a common format so that data scientists can produce them and engineers can deploy them.
Luckily, open standards for describing predictive models do exist. This removes the requirement for the costly re-implementation of models when deployed into production. Models can be described in a standard interchange format that allows the efficient interchange of models between vendors, such that a model developed by data scientists on Hadoop can be deployed in production against a real-time stream with confidence in the preciseness of the implementation.
To date, most of the focus around predictive analytics standards has been on the PMML (Predictive Model Markup Language) model interchange format. This format, developed by the DMG (Data Mining Group), is well established in the analytics space. PMML is a specification expressed in XML that is designed to represent a collection of specific-purpose, configurable statistical models. Most analytic tools support the export of PMML models, and a number of tools support the deployment of PMML models into production.
Though this is all great, there is a downside. PMML has limited support for computation. The standard defines the set of supported models, so things the standard accommodates are fairly simple to accomplish. But, it fails as a uniform deployment methodology due to its lack of expressiveness. One can only represent models in PMML that are baked into the standard itself. Filling needs outside the standard requires tremendous effort, or may be impossible.
To address this, the DMG has introduced PFA (Portable Format for Analytics), an evolution of the notion of serializing analytics. Like PMML, PFA is an industry standard serialization format that allows the scoring of trained models to be abstracted from the training itself, allowing computations to move between disparate environments.
PFA incorporates several improvements informed from observing the use of PMML over many years. One improvement to note is the comprehensive support for encapsulating data pre- and post- processing. In modern scoring flows, significant processing is typically applied to the input data prior to application of the model (e.g. cleansing, feature extraction and feature construction). Historically, these needs may have required a companion code fragment or script to complement the PMML model, complicating operationalization. With PFA, the entire scoring flow can be represented in a standardized manner in a single executable document, making the operationalization of models much more turn-key.
On the implementation side, PFA hosts have defined responsibilities, among them enforcing a well-defined memory model that allows for correct concurrent execution of engines. Additionally, the PFA specification allows for user-defined functions that a cooperative host can permit to be invoked from outside the engine. This enables a number of interesting possibilities.
To demonstrate some of these capabilities in a concrete fashion, we can walk through a prepared PFA engine. This engine is a simple tunable filter that tracks basic metrics internally. The main action accepts an idea, represented here as an ID and a score. If the score meets a threshold, the engine passes it to the output. The threshold can be changed via a user-defined function. Each pass and failure is tracked, and another function is defined that allows these counts to be retrieved.
So what does all of this look like?
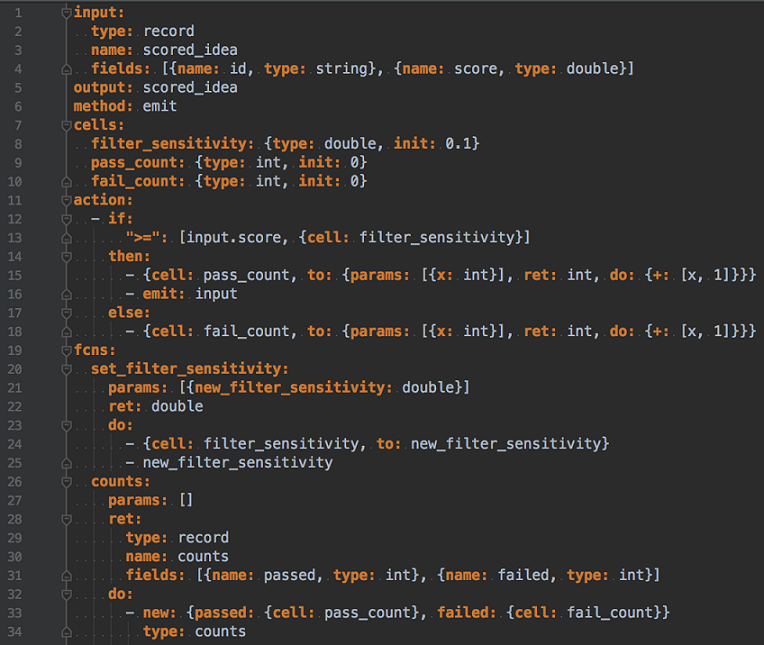
Not what anyone would call an easy read. In fairness, PFA is intended for machine generation, so the somewhat unwieldy syntax is not an obstacle in practice.
The first line of this engine defines the input, which is the type of data the engine accepts for the main action. Types are expressed using Apache Avro, an open-source data interchange standard. The output type is defined on line 5, in this case re-using the input definition.
The method field declares the main execution semantics of the engine. In this case, we’ve chosen to make an emitter engine, which means that output from the main action is done via explicit invocation of an emit function rather than simply returning a value.
The cells field defines typed concurrent storage. We’re using this feature to maintain a filter cut-off, as well as some basic metrics. As noted, the memory model for these cells is well-defined to ensure that disparate hosts treat this storage similarly, allowing predictable operation.
The action field provides the focus of the engine. In our engine, a condition is checked. If the incoming score meets the set threshold, the ‘pass_count’ cell is incremented automatically \and the input is emitted to the output. Otherwise, the ‘fail_count’ cell is incremented, and execution ends.
The fcns field defines functions, as most programming languages allow and with similar semantics. In this example, we have two simple functions that allow external actors to update our filter sensitivity, and query the engine for its metrics.
Additional examples are available in the interactive PFA tutorials that are provided by the DMG, as well as a much deeper dive into the functionality provided by the standard, if more information is desired.
A shift to PFA has the potential to be a watershed event in predictive analytics. We see predictive engines deployed and instrumented into business processes and applications, allowing data science assets to drive significant business impact, not just esoteric slide decks. We at Alpine Data and others have begun to introduce support for PFA with deeper support expected in the near future, and it is going to be exciting to see the adoption of PFA change the game in deployment of data science.
 Contributed by: Jason Miller, Industrial Applications Engineer, Alpine Data. Jason spent 15 years doing targeted high-value software consulting for fortune 100 businesses and the government before deciding to apply his knowledge of real-world business needs to the analytics space in Silicon Valley.
Contributed by: Jason Miller, Industrial Applications Engineer, Alpine Data. Jason spent 15 years doing targeted high-value software consulting for fortune 100 businesses and the government before deciding to apply his knowledge of real-world business needs to the analytics space in Silicon Valley.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind