BlueData®, provider of the leading Big-Data-as-a-Service (BDaaS) software platform, announced breakthrough performance results. The results from a new Intel® benchmarking study show comparable performance for Hadoop when running in a bare-metal environment or in a containerized environment using the BlueData EPIC™ software platform.
BlueData Announces Bare-Metal Performance for Hadoop on Docker Containers
April 2, 2017 by Leave a Comment
Waterline Data Releases Smart Data Catalog 4.0 for Faster Use of Big Data
March 31, 2017 by Leave a Comment
Waterline Data, a leader in Data Lifecycle Management, announced the immediate availability of its latest platform offering, Smart Data Catalog 4.0.
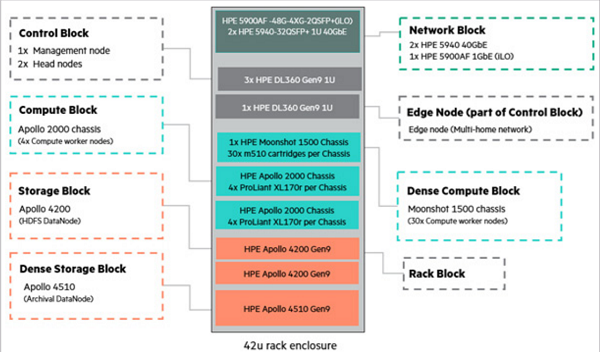
The Five Blocks of the HPE WDO Solution
March 29, 2017 by Leave a Comment
This is the sixth and final entry in an insideBIGDATA series that explores the intelligent use of big data on an industrial scale. This series, compiled in a complete Guide, also covers the exponential growth of data and the changing data landscape, and the HPE Workload and Density Optimized System. The final entry in the series is focused on the five blocks of the HPE WDO Solution.
Big Data and The HPE Workload and Density Optimized System
March 22, 2017 by Leave a Comment
This is the fifth entry in an insideBIGDATA series that explores the intelligent use of big data on an industrial scale. This series, compiled in a complete Guide, also covers the exponential growth of data and the changing data landscape, as well realizing a scalable data lake. The fifth entry in the series is focused on the HPE Workload and Density Optimized System.
Apache Spot (Incubating) Provides Scalable, Flexible, Open Source Cybersecurity Hub for Forensic, Telemetry and Contextual Data
March 4, 2017 by Leave a Comment
Cloudera, a provider of a data management, analytics and machine learning platform built on the latest open source technologies, announced that Apache Spot (incubating) now acts as a modern, open-source solution that can economically provide a comprehensive cybersecurity hub for forensic, telemetry, and contextual data.
Arcadia Data Introduces Visual Analytics Platform Native to Cloudera Enterprise
January 21, 2017 by Leave a Comment
Arcadia Data, the visual analytics software that solves the most complex big data problems, announced new native integration features for Arcadia Enterprise and Cloudera Enterprise to deliver a comprehensive real-time, Hadoop-native analytics platform. Directly integrated with Cloudera Manager and with new support for Apache Kudu and Cloudera Search, users will now have access to data-native architecture that enables both real-time dashboards and rich data visualization for large-scale, big data uses cases such as IoT data, spanning cloud, on-premises, and hybrid deployments.
Fuzzy Logix Announces Availability of DB Lytix™ for Cloudera Enterprise 5
January 20, 2017 by Leave a Comment
Fuzzy Logix announced availability of its advanced analytics suite DB Lytix™ on Cloudera Enterprise 5. DB Lytix software enables analysts and data scientists to perform predictive and advanced statistical analysis on Cloudera using fast, fully supported and scalable analytics running natively on the cluster.
Research Firm Advises Analytics Stakeholders and Security Professionals to Build Plans for Securing Hadoop-based Assets
January 9, 2017 by Leave a Comment
Dataguise, a technology leader in secure business execution, announced inclusion in a report by Gartner titled, “Rethink and Extend Data Security Policies to Include Hadoop.” The report provides best practices for addressing data security concerns related to Apache Hadoop deployments and highlights several leading vendors in the category to support these endeavors.
Splice Machine’s New OLAP Engine Adds Columnar Storage and In-Memory Caching to its Hybrid Relational Data Platform
December 23, 2016 by Leave a Comment

Splice Machine, provider of the open-source SQL RDBMS powered by Apache Hadoop® and Apache Spark™, announced the release of version 2.5 of its industry-leading data platform for intelligent applications. The new version strengthens its ability to concurrently run enterprise-scale transactional and analytical workloads, frequently referred to as HTAP (Hybrid Transactional and Analytical Processing).
Hortonworks Advances Cloud Strategy with Availability of Hortonworks Data Cloud for Amazon Web Services
December 21, 2016 by Leave a Comment

Hortonworks, Inc. ® (NASDAQ: HDP), a leading innovator of open and connected data platforms, announced the availability of Hortonworks Data Cloud on the Amazon Web Services (AWS) Cloud. Hortonworks Data Cloud for AWS enables users to harness the agility and elasticity of Apache® Hadoop™ and Apache® Spark™ in the cloud for powering new workloads and analytic applications. The new cloud service, powered by open source, delivers the most popular enterprise-grade capabilities of Hortonworks Data Platform (HDP®) with both hourly and annual billing options available on the AWS Marketplace.


