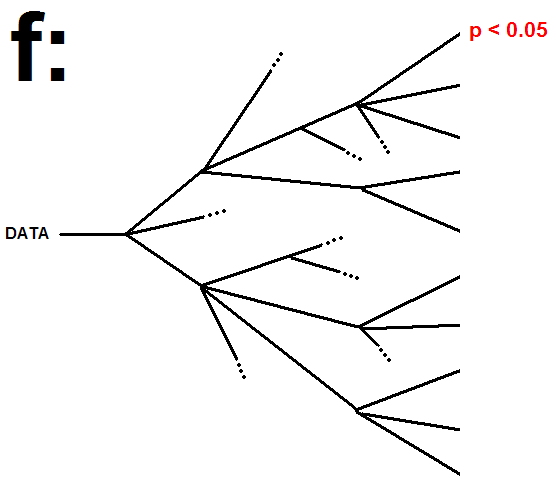
 As a data scientist, I’m constantly researching and examining the theoretical foundations of my field. One area that frequently pops up in the literature is how to select the best statistical model for the data set at hand. I found this helpful blog post over at Discover Magazine that serves to summarize the situation as the F problem, where F is the Forking path (see inset diagram). The F problem has many other names: degrees of freedom, analytic flexibility, p-value fishing, false positive psychology, and others.
As a data scientist, I’m constantly researching and examining the theoretical foundations of my field. One area that frequently pops up in the literature is how to select the best statistical model for the data set at hand. I found this helpful blog post over at Discover Magazine that serves to summarize the situation as the F problem, where F is the Forking path (see inset diagram). The F problem has many other names: degrees of freedom, analytic flexibility, p-value fishing, false positive psychology, and others.
Those who tried every statistical test in the book until they got a p value less than 0.05 find themselves here, an enormous lake of murky water. Sinners sit on boats and must fish for their food. Fortunately, they have a huge selection of different fishing rods and nets (brandnames include Bayes, Student, Spearman and many more). Unfortunately, only one in 20 fish are edible, so they are constantly hungry.
Given any particular set of raw data set, a researcher faces a series of choices about how to turn it into a “result.” There are many choices over which statistical tests to run, on which variables, after excluding which outliers, and applying which preprocessing, and so on. For machine learning applications, there is the decision for which algorithms to use for a particular data set in order to minimize over-fitting.
Yet f is not a problem for all of science. Broadly, f only affects research in which the results take the form of p-values. In statistical significance testing the p-values are the probability of obtaining a test statistic at least as extreme as the one that was actually observed, assuming that the null hypothesis is true.



Speak Your Mind