
This article is the third in an editorial series that will review how predictive analytics helps your organization predict with confidence what will happen next so that you can make smarter decisions and improve business outcomes..
It is important to adopt a predictive analytics solution that meets the specific needs of different users and skill sets from beginners, to experienced analysts, to data scientists as mentioned in last week’s article.
 At its core, predictive analytics relies on capturing relationships between past data points, and using those relationships to predict future outcomes. In order to make predictions based on a given data set, one or more predictor variables are used to predict a response variable. In its simplest form, predictive analytics assists with developing forecasts for business decision making. To handle more complex requirements, advanced predictive analytics techniques are applied to drive critical business processes. In this section we will provide a high level view of the primary classes of predictive analytics: supervised learning and unsupervised learning.
At its core, predictive analytics relies on capturing relationships between past data points, and using those relationships to predict future outcomes. In order to make predictions based on a given data set, one or more predictor variables are used to predict a response variable. In its simplest form, predictive analytics assists with developing forecasts for business decision making. To handle more complex requirements, advanced predictive analytics techniques are applied to drive critical business processes. In this section we will provide a high level view of the primary classes of predictive analytics: supervised learning and unsupervised learning.
Supervised learning is divided into two broad categories: regression for responses that are quantitative (a numeric value), such as miles per gallon for a particular car, and classification for responses that can have just a few known values, such as ‘true’ or ‘false’.
- Regression – Regression is the most common form of predictive analytics. With regression, there is a quantitative response variable (what you’re trying to predict) like the sale price of a home, based on a series of predictor variables such as the number of square feet, number of bedrooms, and average income in the neighborhood according to census data. The relationship between sale price and the predictors in the training set would provide a predictive model. There are many types of regression methods including the above – multivariate linear regression, polynomial regression, and regression trees, to mention a few.
- Classification – Classification is another popular type of predictive analytics. With classification, there is a response categorical variable, such as income bracket, which could be partitioned into three classes or categories: high income, middle income, and low income. The classifier examines a data set where each observation contains information on the response variable as well as the predictor variables. For example, suppose an analyst would like to be able to classify the income brackets of persons not in the data set, based on characteristics associated with that person, such as age, gender, and occupation. This is a classification task that would proceed as follows: examine the data set containing both the predictor variables and the already classified response variable, income bracket. In this way, the algorithm learns about which combinations of variables are associated with which income brackets. This data set is called the training set. Then the algorithm would look at new observations for which no information about income bracket is available. Based on the classifications in the training set, the algorithm would assign classifications to the new observations. For example, a 51 year old female marketing director might be classified in the high-income bracket. There are many types of classification methods such as logistic regression, decision trees, support vector machines, Random Forests, k-Nearest Neighbors, naïve Bayes, to mention a few. Unsupervised learning is used to draw inferences from datasets consisting of input data without labeled responses. The most common unsupervised
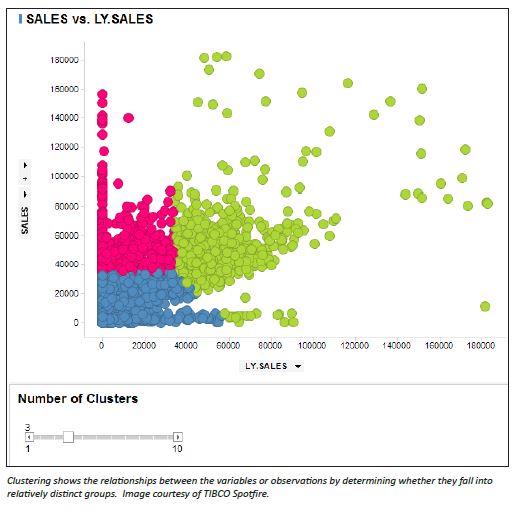
learning method is cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data. - Clustering – Using unsupervised techniques like clustering, we can seek to understand the relationships between the variables or
between the observations by determining whether observations fall into relatively distinct groups. For example, in a customer segmentation analysis we might observe multiple variables: gender, age, zip code, income, etc. Our belief may be that the customers fall in
different groups like frequent shoppers and infrequent shoppers. A classification analysis would be possible if the customer shopping
history were available, but this is not the case in unsupervised learning — we don’t have response variables telling us whether a customer
is a frequent shopper or not. Instead, we can attempt to cluster the customers on the basis of the variables in order to identify distinct customer groups. There are other types of unsupervised statistical learning including k-means clustering, hierarchical clustering, principal component analysis, etc.
Next week’s article will look at Predictive Analytics Software. If you prefer the complete insideBIGDATA Guide to Predictive Analytics is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of TIBCO Software.



Speak Your Mind