Hadoop YARN (Yet Another Resource Negotiator) is a resource-management platform responsible for managing compute resources in clusters and using them for scheduling of user applications. YARN was added as part of Hadoop 2.0. Over the past several months of going to conferences like Hadoop Summit, attending big data Meetup groups like LA Big Data Users Group, talking to practitioners, and even a Big Data Camp event in my home base of Los Angeles, I have compiled an informal list of “tips and guidelines for administrators” – how to operate a YARN cluster efficiently. The article that follows is a hodge-podge collection of these ideas that are sure to change over time as the software continues to mature.
Overview of YARN Configuration
Almost all YARN related configurations are found in yarn-site.xml where there are nearly 150 configuration properties, most are well documented. In this one file you’ll see configs for Security, ResourceManager, NodeManager, TimelineServer, and Scheduler. Some properties are required like hostnames, some are common like client and server, and some are more advanced like RPC retry policy.
Generally, any property of the form yarn.resourcemanager.* and yarn.nodemanager.* are server-side configs, not to be looked at by clients. YARN administrators can mark these as “final” which says they can’t be overridden. Properties of the form yarn.client.* are client-side configs meant for clients submitting apps.
ResourceManager
The memory requirement for ResourceManager is 4-8GB, but if you’re running JobHistoryServer for MapReduce this is pretty memory intensive so at least 8GB is needed.
A new feature is ResourceManager High Availability (RM HA) which is recommended to be enabled, but a Zookeeper cluster is needed for leader election and fencing support. Zookeeper is also used for automatic failover.
You can start 2 or 3 ResourceManagers and to do this you specify rm-ids using the configuration variable: yarn.resourcemanager.ha.rm-ids and then associate hostnames for the rm-ids using yarn.resourcemanager.hostname.rm1, yarn.resourcemanager.hostname.rm2, etc. You don’t need to change any other configs since scheduler, resource-tracker addresses are automatically updated. In addition, the Web UI is automatically redirected to the active resource manager.
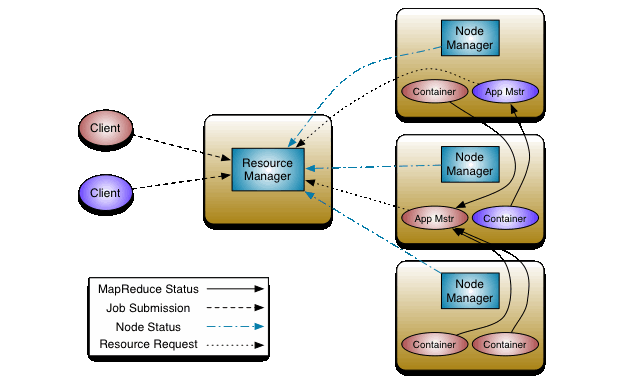
Hadoop 2.0 YARN architecture
Schedulers
There are two main types of schedulers: capacity scheduler and the fair scheduler. While the cluster is up and running, you can use admin files for both types of schedulers to dynamically change the setup. As a caution, if you have HA enabled, you need to be aware that the queue configuration files are stored on local disk. A new feature is coming that will centralize configs in progress, otherwise you need to make sure that the queue configuration files for your schedulers are in sync.
The capacity scheduler allows you to setup queues to split resources which is useful for multi-tenant clusters where you want to guarantee resources. Best practices for the capacity scheduler should take into account some or all of the following:
- There are multiple queues with dedicated resources and the queues are hierarchical where capacity must add up to 100% at each level of the hierarchy.
- The configuration file for the capacity scheduler is capacity-scheduler.xml.
- It is important to take some time to setup your queues. Setting up queues makes things a lot easier down the road when there is a competition for resources.
- Queues have per-queue ACLs (access control lists) to restrict queue access; particularly useful if you’re running test and production on the same cluster.
- Elasticity can be limited on a per queue basis, so if you have a queue that has 30% of the cluster and you do not want to allow the queue to take more than 50% then you can use the variable yarn.scheduler.capacity.<queue-path>.maximum-capacity to limit its maximum capacity.
- You can also drain a queue at run-time if you find that queues are overwhelming a cluster you can use yarn.scheduler.capacity.<queue-path>.state in order to decommission a queue so you can get the throughput back to an acceptable level. Then you can re-commission the queue to a running state.
The YARN fair scheduler is somewhat different in that it was designed to give apps equal share of resources on average over time, i.e. split resources “fairly” across applications. Here are some of best practices considerations for the fair scheduler:
- You don’t have to worry about starvation, which is a potential problem of the capacity scheduler.
- There is support for queues, but they are meant for preventing users from flooding the system with apps.
- Has a fairness policy that can be changed dynamically. This scheduler is good if you have a lot of small jobs that tend to finish quickly.
Container Size
A container represents an allocated resource in the cluster. It is important to size containers through use of 4 variables of the form: yarn.scheduler.*-allocation-* which control the minimum and maximum memory and CPU a container can obtain (the default boundary values are 1GB, 8GB, 1 core and 32 cores). Currently, the NodeManager only enforces memory limits, so it is recommended that you map most of your resource requirements to a memory requirement.
NodeManagers
There is a variable called yarn.nodemanager.resource.memory-mb sets how much memory YARN can use for containers (default is 8GB). Be careful not to set it too high because it can lead to thrashing on the node.
It is recommended to set up a health-checker script. YARN has a communications resource manager to determine the health of a node, but it doesn’t really do very much health checking. For example, an app can fill up a disk on a node, but NodeManager won’t detect the full disk. A health-checker script can do things like (i) check disk, (ii) check network, (iii) check external resources required for job completion, and (iv) weed out bad nodes automatically.
There is a physical and virtual memory monitor that runs on every node. By default it checks the physical and virtual memory a task is using. The default virtual memory limit is 2.1 times the physical limit but many people find this to be way too low.
Typically containers on NodeManagers have multiple disks and HDFS is also running on those nodes. HDFS can affect your disk performance. So you might consider allocating a couple of disks for YARN and the rest for HDFS so you have some separation.
YARN Log Aggregation
Everyone should turn on log aggregation. Log aggregation can be turned on using yarn.log-aggregation-enable and you tell YARN where on HDFS to put the files. You can also control the retention period for logs by setting parameters for purging. App logs can be obtained using the “yarn logs” command. Logs make debugging easy, and the only downside is the creation of a lot of small files that could affect HDFS performance, but they can be cleaned up using the purging parameters.
YARN Metrics
Here are some useful URLs many people aren’t aware of to get metrics.
To get JMX metrics use: http://:/jmx, http://:/jmx
- Cluster metrics for apps running: successful, failed
- Scheduler metrics such as queue usage (for every queue in the hierarchy)
- RPC metrics
To get Web UI metrics use: http://<rm address>:<port>/cluster
Web UI metrics has a lot of similar information such as cluster metrics, but the scheduler metrics are easier to digest especially for queue usage because they are visually much more informative using color coding, for example, to denote queue usage.
Download the latest YARN white paper from the insideBIGDATA White Paper Library.



Speak Your Mind