
In this new Guide to In-Memory Computing the goal is to provide direction for enterprise thought leaders on ways of leveraging in-memory computing to analyze data faster, improve the quality of business decisions, and use the insight to increase customer satisfaction and sales performance.
This article is the first in a series that explores the benefits that enterprises can achieve by adopting in-memory computing technologies. The complete insideBIGDATA Guide to In-Memory Computing is available for download from the insideBIGDATA White Paper Library.
 Introduction to In-Memory Computing
Introduction to In-Memory Computing
In-memory computing (IMC) is an emerging field of importance in the big data industry. It is a quickly evolving technology, seen by many as an effective way to address the proverbial 3 V’s of big data—volume, velocity, and variety. Big data requires ever more powerful means to process and analyze growing stores of data, being collected at more rapid rates, and with increasing diversity in the types of data being sought—both structured and unstructured. In-memory computing’s rapid rise in the marketplace has the big data community on alert. In fact, Gartner picked in-memory computing as one of the Top Ten Strategic Initiatives.
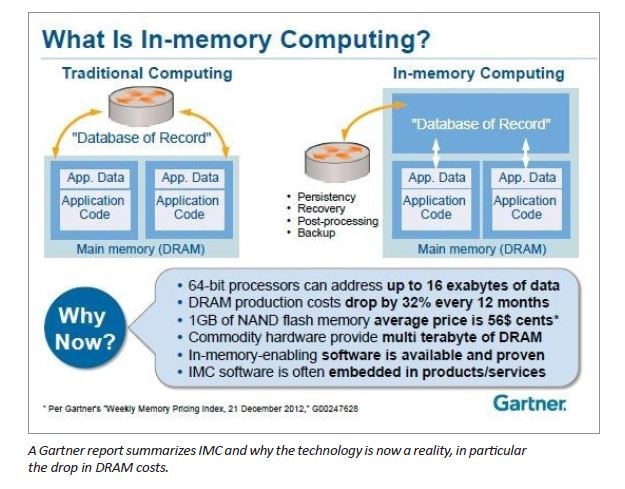
But what is In-memory computing? Put simply, in-memory computing primarily relies on keeping data in a server’s RAM instead of much slower spinning disk or flash devices and massive parallelization as a means of processing at faster speeds. In-memory computing especially applies to processing problems that require extensive access to data analytics, reporting, data warehousing, high-speed transactions and big data applications.
There are two primary ways for how IMC solves the problems of big data—lowering latency time for analytics applications and yielding higher
throughput for transactional applications. By removing high-latency devices like disk drives out of the equation, the time it takes to process
a request and deliver a response (latency) is dramatically reduced. Estimates vary depending on disk speed and available input/output (I/O) bandwidth, but by one measure, RAM latency is estimated at 83 nanoseconds and disk latency at 13 milliseconds, a whopping speedup of 6 orders of magnitude. You can’t own this entire speed advantage because there are CPU processing time and other constraints in the mix, but disk
I/O has long throttled performance. In-memory performance improvements vary by application, data volume, data complexity, and concurrent-user loads, but by any measure the speedup with IMC can be dramatic.
The case for IMC and analytics applications is clear, but what about mainstream transactional systems? IMC represents a significant opportunity when you can run a query, process, or transaction 10x, 20x, even 100x faster than you used to. What will that difference do for your business? The answer will determine whether IMC is a specialty tool for only a few unique use cases, or a platform upon which your entire enterprise IT runs. The purpose of this Guide is to provide the information that enterprise thought-leaders need to make strategic decisions about the use of IMC.
Let’s take a step back here and review what is meant by “in-memory.” You often see discussions of IMC with references to DRAM (dynamic random access memory), SSD (solid state disk), PCI-based flash (server-side flash), memory channel storage (non-volatile DIMM memory that delivers low latency storage directly on the processor bus), and others. Most storage vendors provide a tiered storage model where part of the data is stored in DRAM which is complemented by a variety of flash or disk devices. Rarely is there a DRAM-only, Flash-only, or disk-only product. Generally speaking however, it is DRAM that best deserves the label as facilitator for IMC.
The most important factor for why IMC is a reality now: DRAM costs are dropping about 32% every 12 months. Big data is getting bigger, and costs are getting lower. If you looked at the price of a Dell server with a terabyte of memory three years ago, it was almost $100,000. Today, a server with more cores—sixteen instead of twelve—and a terabyte of DRAM, costs less than $40,000.
The high-level architecture of a traditional and in-memory data warehouse architecture is shown in the figure below. The shift from traditional,
hard disk-based data warehouses to IMC-based data warehouses yields an organization with fewer layers along the path from raw data to analytics results.
With traditional data warehouses, raw data are stored in a data warehouse and portions of the data are extracted to data marts for use by specific
departments—providing user specific aggregations and calculations. The content stored in a data mart is then utilized by business intelligence applications for the processing and visualization of final results. As in a traditional data warehouse, raw data is stored in an IMC-enabled data warehouse, however business intelligence applications do not request partial results from data marts but rather final results from the data warehouse as a whole. The data mart layer becomes obsolete. Furthermore, IMC-enabled data warehouses allow for a frequent update of raw data so that transactional applications can directly feed data into an IMC based data warehouse.
 IMC is becoming a favorite approach in transactional systems such as ERP or financial trading applications with the expectation that IMC will both improve performance for line-of-business applications and allow more sophisticated analytics within them. This means that data-intensive processes and transactions can be performed much faster.
IMC is becoming a favorite approach in transactional systems such as ERP or financial trading applications with the expectation that IMC will both improve performance for line-of-business applications and allow more sophisticated analytics within them. This means that data-intensive processes and transactions can be performed much faster.
As with many new fields of technology, the genesis often arises from academic research. In the case of IMC, the technological foundation comes from the mid-1980s. At the time, so-called “database machines” received a hotbed of research activity in an effort to build computer architectures specifically designed for database operations. An early research paper that defined initial ideas about IMC was MARS: The Design of a Main Memory Database Machine1. At that time, the goal was to build a machine with an address space of 1-20 GB which was very large for that period.

Over the next few weeks we will explore these In-Memory Computing topics:
- Introduction to in-memory computing
- The business case for in-memory computing
- Types of in-memory computing
- Performance benchmark
- GridGain in-memory data fabric
If you prefer the complete insideBIGDATA Guide to In-Memory Computing is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of GridGain.



Speak Your Mind