
This article is the third in an editorial series that will provide direction for enterprise thought leaders on ways of leveraging in-memory computing to analyze data faster, improve the quality of business decisions, and use the insight to increase customer satisfaction and sales performance.
A confluence of factors have contributed to the strong business case for IMC, including the steep upward slope for the collection of business data, the demand for analytics approaching real-time, and increased complexity of business software applications as mentioned in last week’s article.
 In this installment we’ll set the stage for in-memory computing technology in terms of its current state as well as its next stage of evolution. We’ll begin with a discussion of the capabilities of in-memory databases (IMDBs) and in-memory data grids (IMDGs), and show how they differ. We’ll finish up the section by demonstrating how neither one is sufficient for a company’s strategic move to IMC; instead, we will explain why a comprehensive in-memory data platform is needed.
In this installment we’ll set the stage for in-memory computing technology in terms of its current state as well as its next stage of evolution. We’ll begin with a discussion of the capabilities of in-memory databases (IMDBs) and in-memory data grids (IMDGs), and show how they differ. We’ll finish up the section by demonstrating how neither one is sufficient for a company’s strategic move to IMC; instead, we will explain why a comprehensive in-memory data platform is needed.
Traditionally, IMC is comprised of two primary classes of technology: in-memory databases (IMDBs) and in-memory data grids (IMDGs). In-memory databases come in two flavors— traditional databases with in-memory options such as Oracle 12c (including Exalytics and Exadata), IBM DB2 with BLU Acceleration, and Microsoft SQL Server 2014. The IMC offerings from traditional RDMS vendors can be considered point solutions (Band-Aid solutions) that represent a single feature in a long list of advertised tools, rather than a more strategic approach toward in-memory architecture. There also are native in-memory databases like Altibase, MemSQL, VoltDB, EXASOL, H20, SAP Hana and others.
IMDGs, on the other hand, provide MPP-based (Massively Parallel Processing) capabilities where data is processed in parallel fashion and dispersed across a large cluster consisting of commodity servers. This organization has been made popular
with Hadoop’s MapReduce methodology.
One way to compare IMDBs and IMDGs is in the level of scalability made possible by the respective technologies. On the one hand, IMDBs utilize SQL that cannot be effectively performed in a distributed environment. This means IMDBs are unable to scale horizontally and as a result, most existing SQL databases (disk or memory based) are based on vertically scalable Symmetrical Processing architecture. But with IMDGs and their horizontally scalable MPP architecture, there is an inherent capability to scale to hundreds or even thousands of servers.
Another point of comparison between IMDBs and IMDGs involves the prerequisite work needed to employ the technology. With IMDBs, replacing existing databases often is required, unless you choose to use an in-memory option to temporarily boost your database performance. This method will require considerably fewer changes to the application itself due to its continued reliance on SQL. On the other hand, IMDGs always work with an existing database, providing a layer of massively distributed in-memory storage and processing between the database and the application. Most IMDGs are highly integrated with existing databases, and can seamlessly perform read and write operations with the databases when necessary. In these instances, developers must modify the application in order to take advantage of these new capabilities but the existing database remains untouched. Here the application no longer is primarily SQL-based, rather it needs to learn how to use MPP, MapReduce or other scalable data processing techniques.
IMDGs also involve the use of a genre of middleware software allowing data to reside in RAM across a cluster of servers, and to be processed in parallel. This means you can take data sets typically stored in a centralized database and now store them in connected RAM across multiple servers. RAM is several orders of magnitude faster than a traditional mechanical spinning disk. Add to the mix native support for parallel processing, and overall performance experiences significant gains. RAM storage and parallel distributed processing form the primary tenets of IMC.
Let’s take a step back to understand how IMDG parallelization, and distributed data processing are coupled. Parallel distributed processing capabilities of IMDG are essential. Consider a typical scenario: a typical x86 server (in the 2014 time frame) may have a complement of RAM between 32GB to 256GB. Although this capacity could be considered a significant amount of memory for a single server, it is generally not enough to store many of today’s operational datasets that easily measure in terabytes.
In order to circumvent this problem, IMDG software is designed from the ground up to store data in a distributed fashion, where the entire data set is divided across the memory of individual computers, each storing only a portion of the overall data set. Once the data is partitioned, parallel distributed processing becomes essential. As a result, end users of IMC-based applications see dramatic performance and scalability increases.
In the end, there are pros and cons associated with both approaches. Coming from the perspective of building a new application, it is advantageous to go with IMDGs since you get to work with existing databases in your organization where necessary, while benefitting from top level performance and scalability. Alternatively, if you’re reconditioning an application, you can use an IMDB under the following conditions:
- You’re able to upgrade or replace an existing disk-based RDBMS
- You’re unable to make changes to your applications
- Increased speed is necessary, but scalability isn’t
With the IMDB option, enterprises are able to boost application speed by replacing or upgrading RDBMS without having to adjust the application itself. Conversely, you can use an IMDG under the following conditions:
- Replacing an existing disk-based RDBMS isn’t possible
- You’re able to make changes to the data access portion of your application
- Both increased speed and scalability are desirable
The following table summarizes the IMDG/IMDB decision making process.
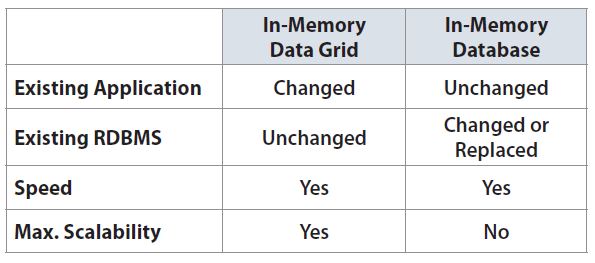
Let’s finish up this section by reviewing the path traversed by IMC over the recent past and justify the next stage in its development. Inmemory
computing within the last 5 years, can be characterized by a variety of “point solutions”— IMDGs, IMDBs, in-memory analytics, in-memory
business intelligence tools, etc.
As an analogy, look back at the web 20 years ago, and we see plenty of point solutions—different portions of a web server, or application server
collectively addressed business requirements. Today, in contrast, we have thoroughly complex web services showing there was an evolution
from a quilt work of specific point solutions to more comprehensive offerings. The same thing happened with the cloud as these commonly used
technologies all went through the same growth pattern. Companies started to realize the strong benefit of using more cohesive platforms.
IMC is in about the same place right now— graduating from a zoo of point solutions to a comprehensive in-memory data platform, or rather an in-memory “data fabric”, which is what GridGain calls it. The drivers behind this evolution are very familiar. Customers were giving the same message in unison—“We’ve been using IMC for the last 5 years, but we don’t want half a dozen products in our data center. Rather, we want a more comprehensive and strategic view of IMC. ”
To more fully complete the IMC picture, another significant trend is developing—RAM-based data centers where memory will be the primary data store and disks, whether spinning disks or flash, will be used predominantly as back-up devices. What happened to magnetic tapes is what’s happening to disk/flash memory. The data centers will become completely RAM-based, especially with non-volatile RAM so if you unplug the power, the data is still there. Further, the speed will be almost identical to DDR3 memory today. This is a huge step forward in the evolution of high-performance, low-carbon-footprint data centers.
If a holistic view of this progress is taken, many CIOs are starting to think of IMC more strategically, and that’s the primary motivation for a new generation of IMC technology—the in-memory data fabric. We’ll see in the last section of this Guide how GridGain has taken this important step forward in the marketplace.
Next week’s article will look at Performance Benchmark. If you prefer the complete insideBIGDATA Guide to In-Memory Computing is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of GridGain.



Speak Your Mind