
This article is the fourth in an editorial series that has the goal to provide direction for enterprise thought leaders on ways of leveraging big data technologies in support of analytics proficiencies designed to work more independently and effectively in today’s climate of working to increase the value of corporate data assets.
Last week’s article explored the benefits that the area of credit scoring and back trading/testing can achieve by adopting big data technologies.
Adopting Big Data for Finance
 The big data revolution has dramatically changed the financial services industry. The following driving factors have motivated the need for financial sector companies to collect, store and analyze massive volumes of data:
The big data revolution has dramatically changed the financial services industry. The following driving factors have motivated the need for financial sector companies to collect, store and analyze massive volumes of data:
- Changes in the delivery of financial products and services. Customers no longer need to physically visit their local bank to make deposits, make investment decisions or complete their banking transactions. Buyers and sellers of stocks execute their trades online instead of relying on brokers. Individuals file their taxes using online tools versus meeting with a tax accountant to prepare and file. As the industry has increasingly moved online, it’s become faster, easier, and more affordable for consumers to handle their own banking and financial transactions.
- The result of these trends is that financial services and products have become commoditized. Instead of establishing relationships with a local service provider, customers often choose the most convenient and inexpensive online offering available. Personal connections as a requirement for customer loyalty has changed dramatically. However, every action made by a customer can be captured and analyzed by organizations seeking to understand the behaviors and preferences of their customers as they would have traditionally done through in-person interactions—now however, the process has become digitized.
- Increased volume of activity. The ease and affordability of executing financial transactions via online mechanisms has led to ever-increasing activity and expansion into new markets. Individuals can make more trades, more often, across more types of accounts, because they can do so with online tools in the comfort of their own homes, or on the go from a mobile device. Increased access and ease of use translates into increased volume of activity, which in turn translates into rapidly growing data volumes.
- It is important for banks, investment firms, and other financial services organizations to be able to collect and analyze this information in order to accurately assess risk and determine market trends. This became apparent during the market downturn of 2007-2008, when banks and brokerage houses scrambled to understand the implications of massive capital leverage and their ability to model and refine liquidity management. A single bank might capture internal transactions exceeding two billion per month, in addition to collecting public data of over a billion monthly transactions. These tremendous transaction volumes have made it nearly impossible to create models that take into account multi-year data sets using detailed data. Financial firms manage anywhere from tens to thousands of petabytes of data, yet most systems used today build models using only samples as small as 100 gigabytes. Relying on data samples requires aggregations and assumptions, resulting in inaccuracies in projections, limited visibility into actual risk exposure, instances of undetected fraud, and poorer performance in the market.
- New sources of data. The increased pace of online activity has led to the availability of new sources of data that are complex to consume, such as unstructured social media data. This information, if combined with individual financial transactions and history, can help to paint a holistic picture of individuals, families, organizations, and markets. Big data technologies are required to process these structured and unstructured data sources since using traditional relational database and data warehousing technologies for this purpose is no longer possible.
- Increased regulatory compliance. As result of more rigorous regulatory compliance laws, the financial services industry has had to store an increasing amount of historical data. New technology tools and strategies are needed to address these demands.
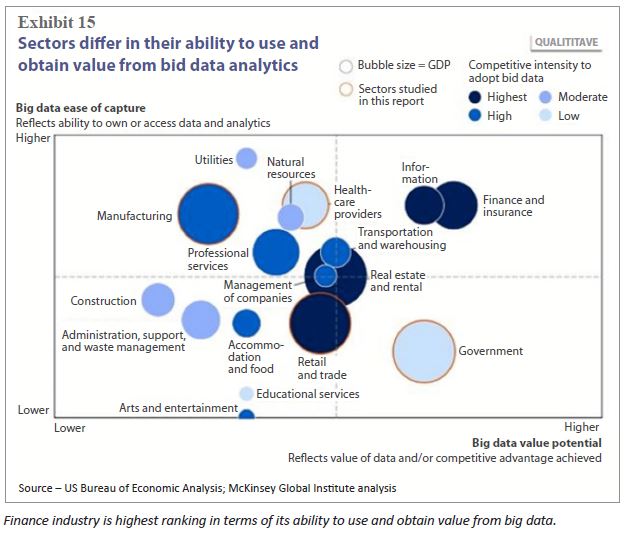
Not all industries are created equal when it comes to being able to put data to use. Some, like the construction industry, are constrained by the amount of data they can capture and even more hamstrung by their ability to get value from it. Others, like the finance industry, both generate a lot of data and can put it to use. In the graphic below from the U.S. Bureau of Economic Analysis, it is clear that the finance industry ranks
highest in terms of its ability to use and obtain value from big data.
Determining the appropriate level of engagement for a big data deployment project is an important consideration toward insuring the success of the project. For example, department-level big data projects generally are more successful than large-scale initiatives which routinely fail. An incremental approach is better.
Here is a short list of guidelines toward the adoption of big data for finance:
- Develop methods and services for the valuation of data—and extend their role in compliance and internal control to the ethical and effective stewardship of data assets.
- Unite disparate data from a variety of systems designed to meet the diversity across regions regarding language, regulations, currency, time zone, etc.
- Use big data to offer more specialized decision making support—often in real time—and decide when data can most usefully be shared with internal and external stakeholders and monetized as new products or services.
- To offset flat or declining revenue streams, financial services firms need to develop new big data centric products while also targeting existing products to new audiences.
- Use big data and its associated tools not only to identify risks in real time and improve forensic accounting abilities but also to evaluate the risks and rewards of long-term investment in new products and new markets.
- Gaining agility starts with an assessment of existing processes and systems. Financial industry firms must identify what existing practices will not support the progress they need. To get significant advantage in today’s competitive landscape, they should pursue technologies that support new, innovative practices.
Hadoop represents a good path for financial sector firms to adopt big data. With Hadoop, firms have access to a powerful platform providing both highly scalable and low cost data storage tightly integrated with scalable processing. Financial firms are now able to tackle increasingly complex problems by unlocking the power of their data. The capability to understand and act upon their data opens the door to a richer and more robust financial ecosystem.
A recent addition to the Hadoop ecosystem is Spark. Spark is an open-source data analytics cluster computing framework built on top of HDFS. Spark serves as evidence of the continuing evolution within the Hadoop community—away from being a batch processing framework tied to the two-stage MapReduce paradigm to a more advanced in-memory, real-time platform.
Now, these firms can better serve their customers, understand their risk exposure and reduce incidents of fraud. Here is a short list of benefits afforded by Hadoop to the financial services industry:
- Scalability to capture and analyze data previously untapped
- An economical way to store and process data
- A central repository for various data structures from existing and new data sources
- Operational efficiency by moving jobs to technology designed to process multiple data types
- The ability to ask different questions to improve decision making
By implementing a Hadoop solution, an organization processing approximately 20 billion events per day is able to significantly decrease operational costs: decreased storage costs from ~$17/GB to ~21 cents, experience a one year payback on the entire initiative.
The Intel Powered Dell™ | Cloudera™ Apache Hadoop Solution is a superb choice for lowering the barrier to adoption for financial institutions
intending to use Apache™ Hadoop® in production. Dell Xeon based PowerEdge servers, Force10 networking, the linux operating system and the Cloudera Manager tools make up the foundation on which the Hadoop software stack runs.
You can start planning out your Hadoop infrastructure using one of the global network of Dell Solution Centers, technical labs that enable you to architect, create a proof-of-concept (POC), validate, and build data center solutions. In a recent POC for a large provider of financial data, Dell partnered with StackIQ to configure a 60-datanode cluster to compare two different big data technologies, Cassandra and HBase. Using StackIQ’s Cluster Manager software the customer was able to rapidly provision and re-provision the servers to run the two different applications with various configurations. The use of Cluster Manager enabled the customer to complete more and higher quality tests than originally expected.
Next week’s article will look at Security and Regulatory Compliance Considerations. If you prefer the complete insideBIGDATA Guide to Big Data and Finance is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of Dell and Intel.



Speak Your Mind