 In this special guest feature, Eric Frenkiel of MemSQL champions the use of Apache Spark in the enterprise coupled with in-memory database technology to achieve the promise of real-time analytics. Eric Frenkiel co-founded MemSQL and has served as CEO since inception. Before MemSQL, Eric worked at Facebook on partnership development. He has worked in various engineering and sales engineering capacities at both consumer and enterprise startups. Eric is a graduate of Stanford University’s School of Engineering. In 2011 and 2012, Eric was named to Forbes’ 30 under 30 list of technology innovators.
In this special guest feature, Eric Frenkiel of MemSQL champions the use of Apache Spark in the enterprise coupled with in-memory database technology to achieve the promise of real-time analytics. Eric Frenkiel co-founded MemSQL and has served as CEO since inception. Before MemSQL, Eric worked at Facebook on partnership development. He has worked in various engineering and sales engineering capacities at both consumer and enterprise startups. Eric is a graduate of Stanford University’s School of Engineering. In 2011 and 2012, Eric was named to Forbes’ 30 under 30 list of technology innovators.
The industry intensity around Apache Spark, an in-memory processing framework widely believed to succeed MapReduce, has captured the market’s imagination for its impressive data exploration engine. Spark gives data scientists and analysts a rich language to explore data rapidly, iteratively and with a suite of timesaving and advanced function libraries.
But Spark itself does not include a datastore, instead relying on popular repositories like the Hadoop Distributed File System (HDFS) and Amazon Web Services S3. Coupling a memory-optimized framework like Spark with these slower storage solutions however, can lead to mixed results. Coupling Spark with an in-memory database however, can change the game for enterprise deployments.
A Memory-Optimized End-to-End Deployment
By coupling Spark with an in-memory database, enterprises can bring data scientists closer to real-time business. And when businesses require cutting edge advanced analytics, the operational data can be shared with Spark in an instant. Let’s explore a few configurations.
Making Contact with Real-Time Data
Data scientists too often have to rely on a data warehouse or HDFS repository, which can be hours or days behind the pulse of the business, giving only a chance to see yesterday’s data tomorrow. By connecting Spark to an in-memory database running critical applications, data scientists can see data in the light of day, including running analyses on real-time data and developing more accurate models based on the most recent data.
Real-Time Streaming Repository
With real-time streams becoming pervasive, enterprises need a way to persist them and make the ongoing data available. Liking from a publish-subscribe messaging system such as Kafka, to Spark Streaming and then an in-memory database creates an instant data pipeline. Developers can then have a simple way to build a real-time application with SQL such as what Pinterest showcased at the recent Strata + Hadoop World in San Jose.
While Kafka allows for consuming events at real-time, it’s not a great interface for a human to ask questions on the real-time data. We wanted to enable running SQL queries on the real-time events as they arrive. As MemSQL was built for this exact purpose, we built a real-time data pipeline to ingest data into MemSQL using Spark Streaming.
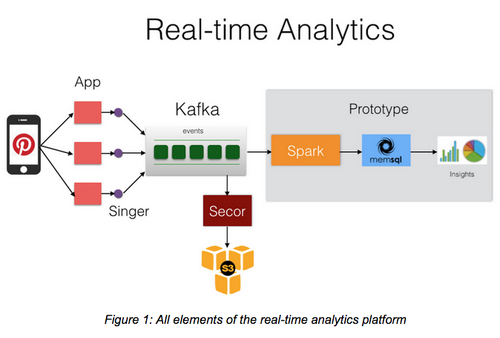 [Image credit: Real -Time Analytics at Pinterest – Pinterest Engineering Blog]
[Image credit: Real -Time Analytics at Pinterest – Pinterest Engineering Blog]
Extending Analytics for Operational Databases
When connected to an operational database, Spark can serve as an extended analytics layer, in places replacing the former practice of user-defined functions. Ideal connections between an operational in-memory database and Spark will be parallel and bi-directional for maximum performance. One example of connecting Spark to an operational in-memory database is the MemSQL Spark Connector as covered recently on the Databricks blog.
Two primary components of the MemSQL Spark Connector enable Spark to query from and write to MemSQL
- A `MemSQLRDD` class for loading data from a MemSQL query
- A `saveToMemSQL` function for persisting results to a MemSQL table
For more information see, Extending MemSQL Analytics on the Databricks blog.
With Spark linked to an operational database, the real-time application data can quickly be transferred for advanced processing and then easily returned into operation and accessed directly from the application. Frequently, Spark will be connected to a replica of the database so that the operations team can ensure the smoothest workflow while still having instantaneous access to real-time data.
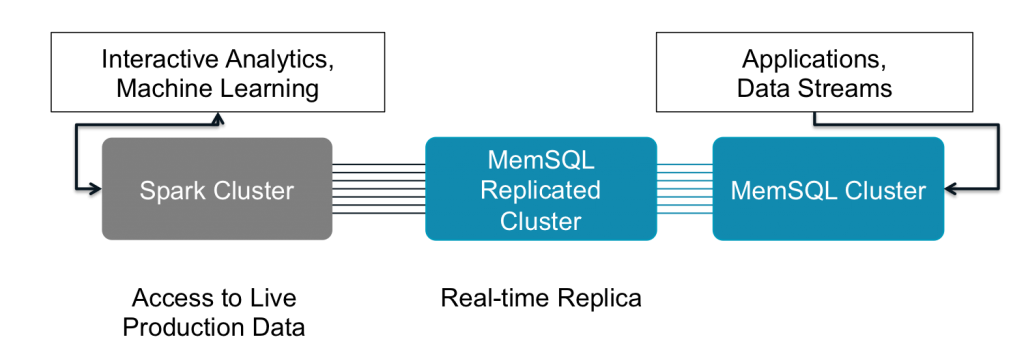
Enterprise-wide Access to Spark
The result sets from Spark processing can provide unique insight to organizational data. Persisting that data available and making it available to large groups of enterprise users allows companies to get the most out of Spark.
When the operational database is relational, and supports SQL, Spark results can be stored for near universal access to enterprise applications and data analytics.
Whether Spark provides a path into the operational database, or a mechanism for advanced analytics on real-time data, the coupling of solutions delivers value to enterprise customers. An in-memory, operational, relational database is the gateway to Spark adoption that many enterprises seek.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind