
An Insider’s Guide to Apache Spark is a useful new resource directed toward enterprise thought leaders who wish to gain strategic insights into this exciting new computing framework. As one of the most exciting and widely adopted open-source projects, Apache Spark in-memory clusters are driving new opportunities for application development as well as increased intake of IT infrastructure. This article is the first in a series that explores a high-level view of how and why many companies are deploying Apache Spark as a solution for their big data technology requirements. The complete An Insider’s Guide to Apache Spark is available for download from the insideBIGDATA White Paper Library.
Apache Spark – An Overview
Apache Spark is an open source cluster computing framework originally developed in 2009 at the AMPLab at University of California, Berkeley but was later donated in 2013 to the Apache Software Foundation where it remains today.
Spark allows for quick analysis and model development, plus it provides access to the full data set thus avoiding the need to subsample, as often needed in environments like R. Spark also supports streaming which can be used for building real-time models using full data sets. When you have a task that is too big to process on a laptop or single server, Spark enables you to divide that task into more manageable pieces. Spark then runs these pieces in-memory, on a cluster of servers to take advantage of the collective memory available on the cluster. Spark processing is based on its Resilient Distributed Dataset (RDD) application programming interface (API).
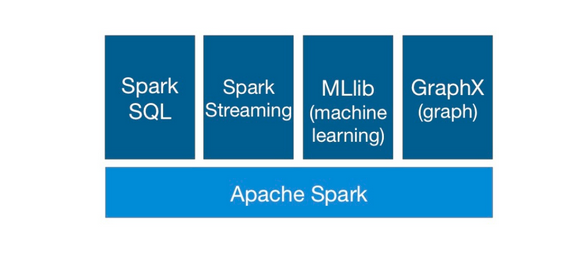
Spark has gained a lot of popularity recently in the big data world due to its computing performance and its wide array of libraries, including Spark SQL (with DataFrames), Spark Streaming, MLlib (machine learning) and GraphX. Spark SQL provides for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine. Spark Streaming enables scalable, high-throughput, faulttolerant stream processing of live data streams. The goal of MLlib is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, and dimensionality reduction. GraphX is a component in Spark for graphs and graph-parallel computation.
 Apache Spark is quickly becoming a core technology for big data analytics in a surprisingly short period of time. Spark addresses many of the key issues in big data environments, which has helped fuel its phenomenal rise. Companies need a toolset that meets the growing demands of a data-driven enterprise. Until now, a single processing framework that fits all those demands has not been available. This, however, is the fundamental advantage of Spark, whose benefits cut across the following critical areas for companies that deal in the business of big data.
Apache Spark is quickly becoming a core technology for big data analytics in a surprisingly short period of time. Spark addresses many of the key issues in big data environments, which has helped fuel its phenomenal rise. Companies need a toolset that meets the growing demands of a data-driven enterprise. Until now, a single processing framework that fits all those demands has not been available. This, however, is the fundamental advantage of Spark, whose benefits cut across the following critical areas for companies that deal in the business of big data.
Advanced Analytics
Spark offers a framework for advanced analytics out-of-the-box. It includes a tool for accelerated queries, a machine learning library, a graph processing engine, and a streaming analytics engine. Instead of trying to implement these analytics via MapReduce, Spark provides pre-built libraries,
which are easier and faster to use.
Simplicity
One of the earliest criticisms of Hadoop was that it was hard to use. Although it has gotten simpler and more powerful with every subsequent release, this complaint has persisted. Instead of requiring users to understand a variety of complexities, such as MapReduce and Java programming, Spark was built to be accessible to anyone with knowledge of databases and some scripting skills in Python or Scala.
Faster Results
As the pace of business continues to accelerate, so does the need for real-time analytics. Spark provides parallel in-memory processing that returns results many times faster than any other approach requiring disk access. Instantaneous results eliminate delays that can slow business processes and incremental analytics. As industry players like TIBCO build applications on Spark, dramatic improvements to the analyst workflow will follow. Accelerating the turnaround time for answers means that analysts can work iteratively, honing in on more precise, and more complete, answers. Spark lets analysts do what they are supposed to do—find better answers faster.
No Preference for Hadoop Vendors
All of the major Hadoop distributions now support Spark, and with good reason: Spark is vendor agnostic, which means it doesn’t tie the user to any specific provider. Due to Spark’s open-source nature, businesses are free to create a Spark-based analytics infrastructure without worrying about what happens if they change Hadoop vendors later. If they make a switch, they can bring their analytics with them.
Spark Ecosystem Survey
Typesafe conducted a survey of the Spark ecosystem recently. Key takeaways were useful in determining how Spark is being deployed:
- For data source, 62% of Spark survey respondents were using HDFS. Nearly half, 46%, were using some form of database. 41% were using Kafka, and 29% were using Amazon S3.
- For cluster management, 56% were running standalone Spark. 42% were on YARN, and 26% were on Apache Mesos.
- For languages, 88% were using Scala, 44% were using Java, and 22% were using Python.

Over the next few weeks we will explore these Apache Spark topics:
- Apache Spark – An Overview
- Why Spark is So Hot?
- Looking at Spark from a Hadoop Lens
- Spark SQL
- The TIBCO – Spark Connection
If you prefer the complete An Insider’s Guide to Apache Spark is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of TIBCO. Click HERE to take in a webinar event recorded on November 17, 2015.



Speak Your Mind