
An Insider’s Guide to Apache Spark is a useful new resource directed toward enterprise thought leaders who wish to gain strategic insights into this exciting new computing framework. As one of the most exciting and widely adopted open-source projects, Apache Spark in-memory clusters are driving new opportunities for application development as well as increased intake of IT infrastructure. This article is the third in a series that explores a high-level view of how and why many companies are deploying Apache Spark as a solution for their big data technology requirements. The complete An Insider’s Guide to Apache Spark is available for download from the insideBIGDATA White Paper Library.
Looking at Spark from a Hadoop Lens
Considering Hadoop and Spark is not an either-or question. Many companies use both frameworks, especially if there is an existing Hadoop installation. Spark is quite data agnostic as it can access data in HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source.
Many looking at Spark from across the aisle naturally seek a significant performance differential. One often quoted benchmark comparing the two frameworks is the Daytona Gray Sort 100TB Benchmark. Using Spark on 206 EC2 machines 100TB of data on disk was sorted in 23 minutes. In comparison, the previous world record set by Hadoop MapReduce used 2,100 machines and took 72 minutes. This means that Spark sorted the
same data 3x faster using 10x fewer machines.
Spark is intended to enhance, not replace, the Hadoop technology stack. From day one, Spark was designed to read and write data from and to HDFS, as well as other storage systems, such as HBase and Amazon’s S3. As such, Hadoop users can enrich their processing capabilities by combining Spark with Hadoop MapReduce, HBase, and other big data frameworks.
A flexible analytics tool like TIBCO Spotfire® is agnostic in terms of data sources. Spotfire can access Hadoop and Spark RDDs using SparkSQL.
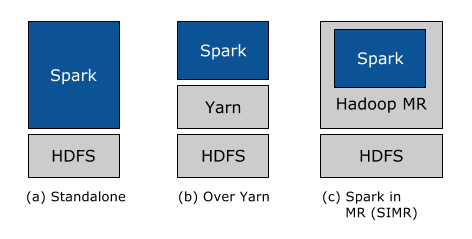
Spark’s focus is on making it as easy as possible for every Hadoop user to take advantage of Spark’s capabilities. There are three ways to deploy Spark
in a Hadoop cluster: standalone, YARN, and Spark in MapReduce (SIMR).
If you prefer the complete An Insider’s Guide to Apache Spark is available for download in PDF from the insideBIGDATA White Paper Library, courtesy of TIBCO. Click HERE to take in a webinar event recorded on November 17, 2015.



Speak Your Mind