![]() StreamSets Inc., the company that delivers performance management for data flows, announced the latest release of StreamSets Data Collector, continuous ingest software that automatically addresses the insidious problem of data drift. The new release helps enterprises accelerate their time to insights by proactively managing the completeness, accuracy and consistency of their data as it flows from collection to consumption.
StreamSets Inc., the company that delivers performance management for data flows, announced the latest release of StreamSets Data Collector, continuous ingest software that automatically addresses the insidious problem of data drift. The new release helps enterprises accelerate their time to insights by proactively managing the completeness, accuracy and consistency of their data as it flows from collection to consumption.
Given the siloed, yet strategic nature of data, enterprises must develop a culture of data performance management,” said Girish Pancha, CEO, StreamSets, Inc. “Just as network operations and security operations matured from numerous siloed projects into centers of excellence, we believe it is time for data operations to make that same critical leap. StreamSets was founded to build the cornerstone infrastructure upon which enterprises can institute disciplined performance management for their data-in-motion.”
Data Drift Calls for a New Paradigm for Managing Data in Motion
Today, moving data reliably and with quality is blocked by the reality of data drift — the deluge of unpredictable, unannounced and unending mutations to data that occur at the source and blindside consuming applications. Data drift breaks ingest pipelines and causes undetected data loss and corrosion that pollutes data stores and downstream analysis. In a recent survey, StreamSets found that challenges with data drift were universal, with 96% of respondents experiencing data drift and nearly one-third citing it as a frequent occurrence.
Data drift cannot be addressed by the prevailing approach of custom coding with low-level frameworks such as Sqoop, Flume and Kafka. These approaches break in the face of unexpected schema change and cannot detect semantic changes since they cannot inspect data within the flow. This creates a chaotic environment that results in false or missed insights, loss of trust in the data, constant fire fighting and endless janitorial data cleansing.
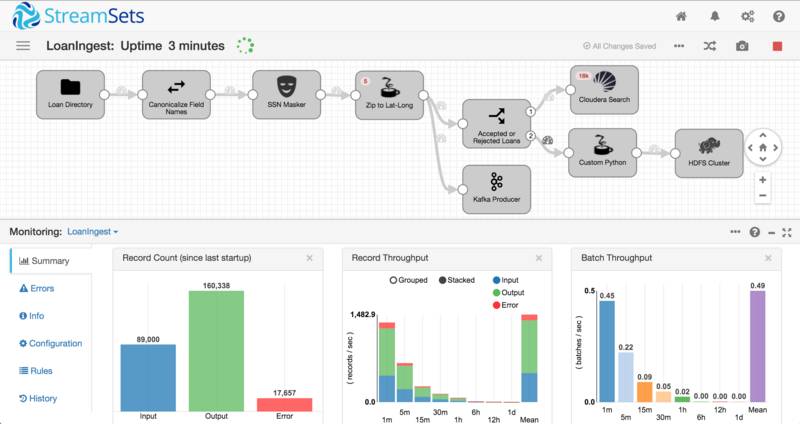
StreamSets Data Collector: Giving Enterprises Control, Efficiency and Agility
With its latest v1.2 release, StreamSets Data Collector automates data drift handling and now supports the Big 3 major Hadoop distributions from Cloudera, MapR and Hortonworks. This version also is certified with the MapR Converged Data Platform including extended support for MapR Streams. It also provides connectors for other popular big data technologies such as Elasticsearch, NoSQL databases such as MongoDB and Cassandra and transient stores such Apache Kafka, MapR Streams and JMS-compliant message queues.
StreamSets Data Collector gives enterprises the necessary control, efficiency and agility to effectively manage performance of their data flows.
- Data flow KPIs for real-time control: Uniquely, StreamSets Data Collector monitors, detects and acts on changes in data patterns alongside providing fine-grained metrics on data flow throughput, latency and error rates. Data drift-handling rules ensure that pipelines flow correctly even when schema changes. Threshold rules, alerts and plug-in processors combine to identify, filter, re-route and sanitize anomalies in-stream to ensure that data lands ready for consumption.
- Adaptable pipelines for efficiency: StreamSets Data Collector provides a visual (integrated development environment) IDE for the design and execution of intent-driven data flows with minimal schema specification and custom code. It is a highly flexible environment, handling both batch and streaming data, and deploying on edge nodes, natively in clusters and as part of an application stack.
- Containerized architecture for agility: Built for continuous operations, StreamSets Data Collector addresses the issues of constant infrastructure upgrades and data flow evolution head on. Each source, stage and destination in a pipeline is isolated, allowing you to maintain and modernize your data infrastructure while ensuring zero downtime.
The ability to ingest multiple streams of rapidly changing data and integrate it with historical batch data is already a problem for early adopters of big data processing technologies that will quickly become a mainstream problem for later adopters alike,” said Matt Aslett, research director, data platforms and analytics, 451 Research. “With StreamSets Data Collector, StreamSets has a differentiated offering that is designed specifically to address this problem.”
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind