 I recently caught up with Ryan W.J. Waite, Senior Vice President of Products at Cray, Inc., to discuss the announcement of the company’s new supercomputing analytics platform Urika GX – 3x faster than prior generations – in direct response to commercial customer demand. Cray’s new platform fuses supercomputing and Big Data analytics to address the needs of customers that are turning to supercomputers to tackle commercial analytics issues across cyber security, banking, finance and pharmaceuticals. These customers are dealing with massive data sets and competitive pressure to analyze and find insights in their data. This announcement marks a new direction for Cray in working with commercial customers not typically associated with supercomputing. Before joining Cray in 2014, Ryan was the general manager of the Data Services group at Amazon Web Services, where he oversaw five big-data services, including product management, engineering and operations. While at AWS, he directed the Amazon Kinesis, AWS Fraud Detection, AWS Data Warehouse, AWS Metering and Tag Metadata teams. Before that, Ryan spent 20 years at Microsoft where he was most recently the general manager for its high performance computing team.
I recently caught up with Ryan W.J. Waite, Senior Vice President of Products at Cray, Inc., to discuss the announcement of the company’s new supercomputing analytics platform Urika GX – 3x faster than prior generations – in direct response to commercial customer demand. Cray’s new platform fuses supercomputing and Big Data analytics to address the needs of customers that are turning to supercomputers to tackle commercial analytics issues across cyber security, banking, finance and pharmaceuticals. These customers are dealing with massive data sets and competitive pressure to analyze and find insights in their data. This announcement marks a new direction for Cray in working with commercial customers not typically associated with supercomputing. Before joining Cray in 2014, Ryan was the general manager of the Data Services group at Amazon Web Services, where he oversaw five big-data services, including product management, engineering and operations. While at AWS, he directed the Amazon Kinesis, AWS Fraud Detection, AWS Data Warehouse, AWS Metering and Tag Metadata teams. Before that, Ryan spent 20 years at Microsoft where he was most recently the general manager for its high performance computing team.
Daniel D. Gutierrez – Managing Editor, insideBIGDATA

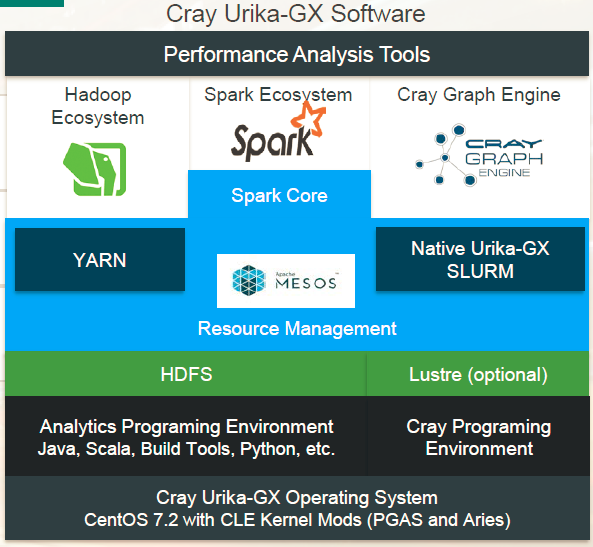
Cray Urika-GX System
insideBIGDATA: How would you characterize the new Urika GX?
Ryan Waite: Urika-GX is a new version of our Urika line of products which is an agile analytics platform that combines our supercomputing technologies with open enterprise-ready frameworks. This kind of platform will not only support the versatility our customers require in the big data space, especially data scientists who are constantly looking at the latest tools that will help them do their job, but it’s also easy to set up and easy for IT administrators to keep up to date.
insideBIGDATA: For readers not familiar with Cray, can you give us a short run-down on the company’s history with respect to analytics?
Ryan Waite: Sure, a couple of things I can highlight here – Cray has been building systems that have been used in the analytics environment for a long time. We were building systems in the 80s that were used in financial services for complex analytics. One of our largest customers is in the analytics space and in partnership with those customers we built some interesting technologies including some graph analytics technologies that were part of the Urika-GD Graph Discovery Appliance. We won some awards for that product. Not only were these products useful for folks doing complex analytics, but they were also used for people you might not normally think about – like there was a major league baseball team that bought one of the Urika-GD systems and they were using it for processing a significant amount of data they were collecting. The original system was for pitcher/batter lineup analysis, but they went on after that to start using it to see if they could predict pitcher injuries. A baseball pitcher is a multi-million dollar resource and if you can predict when they’re going to be injured, you can pull them out of rotation before that injury occurs. There have been a number of customers that have been trying out these technologies in the past, and as we move forward, we’re taking all that learning and pushing it into the new Urika-GX.
insideBIGDATA: What kind of customers did you build the Urika GX for?
Ryan Waite: We built Urika-GX for two types of customers. The first being the data science community, application developers, statisticians, data engineers that are constantly trying to find out what’s the best way to get the kind of insight they need. What I love about this community, and I’ve worked in this community in the past, is there is so much innovation going on in this space. There’s such a desire to experiment with the latest and greatest tools and see if they’ll provide new types of insights. At Cray, when we work with these customers, we wanted to support the customer’s quest to try out the latest and most interesting infrastructure for solving problems.
The other type of customer we focused on is the IT organization, the folks that have to get these systems up and running and keep them running. One of the things we heard from one large organization was that with some of the big data solutions being purchased, they come with a recipe and the burden of installing the operating system, or installing systems management software, installing Hadoop, installing Spark, etc. is really left to that system administrator to figure out. In addition, they have to figure out all the interoperability issues between a particular version of Hadoop and a particular version of Spark, Kafka, Storm, whatever the tools being used. That’s a pretty heavy burden, it can sometimes take months for these organizations to stand up a big data solution and it often results in a lot of frustration that can lead to failure for these types of projects.
insideBIGDATA: Can you give me an idea of some of the problems you were trying to solve with the Urika GX?
Ryan Waite: One problem we heard about was the “Franken-cluster” problem where you have one cluster that’s being used for ETL and another cluster that’s used for Spark and another used for Pig or Hive or whatever you’re running in your infrastructure. That kind of Franken-cluster approach means that one or two clusters are getting good utilization and the rest of your clusters might be getting low utilization and that effectively turns into waste. So it would be great if there was one kind of infrastructure that could run a variety of workloads on that same system. In my previous job, we were running machine learning models to identify fraud and it was so interesting to see the different types of tools people used – sometimes we’d use R, sometimes we’d use Matlab.
People know Cray as a company that provides high performance, especially at huge scale, but the most important thing we found in talking to customers is their ability to be agile in the way that they solve big data problems. That’s the first thing we focused on with this product. Customers told us they wanted to run multiple analytics workloads concurrently on the same box. We’ve pre-integrated Hadoop, Spark, the graph technology that’s part of Spark, as well as our own Cray Graph Engine. The way we share the system among those different workloads is by integrating Mesos into the platform. So we’re able to use Mesos to dynamically re-purpose the system so that part of it can be dedicated to Spark, and the next day maybe an even larger part to Spark, the next day reduce the number of nodes dedicated to Spark and use Kafka or whatever your favorite set of tools are. So that ability to dynamically re-purpose really helps out customers to feel like they made a great investment and they’re getting good utilization out of the infrastructure they purchased.
We also wanted to make sure the frameworks we were using were open and standards based. We even embraced OpenStack as a management framework for Cray systems, and it will be true for all Cray systems in the future. The first product we’ll be shipping that uses OpenStack is Urika GX. We’ve also made sure that this system fits into a standard data center. Our Cray XC series of supercomputers; it is sort of an unusual looking box designed for super high efficiency. The Urika GX, on the other hand, is a standard 19 inch rack and is designed to fit in any enterprise data center. Supporting that enterprise customer has been a key focus with this product. And then in terms of configurations, with our previous products some customer said they really liked them but they were starting small, they were just starting to do big data work and big for them meant 16 servers and so our small configuration is a 16 server configuration and our large configuration is a full rack at 48 nodes. Customers can buy more and more racks to get bigger and bigger.
We also support Lustre as a file system option. The majority of our customers are going to use HDFS that will be plugged into a traditional NAS box on the back-end. We have one customer that’s pushing real hard in the machine learning space and they were not able to get enough data into the system using traditional file servers so they’re looking at Lustre to “feed the beast” for training that machine learning algorithm.
insideBIGDATA: Can you give us a peek under the hood of the Urika GX?
Ryan Waite: Yes, like I said before, under the hood of the Urika GX is a standard 19 inch rack. We’ve pre-integrated and validated and installed all software on the system so it’s ready to go right away. One of the unique pieces of this system is the Aries interconnect, a core component that makes the XC a supercomputer and we’ve taken that network and put it into the Urika GX. One of the big technologies that can take advantage of that is the Cray graph engine, it’s the way we’re able to do such large distributed graph processing. It supports over 1,700 cores per system, 22 TB of RAM and we support both SSDs and hard drives on the system. More and more of our customers are looking at Spark and embracing the in-memory computing model, so large RAM and SSDs are important to these customers. We have other customers that need to process bigger data and hard drives model a more traditional Hadoop solution that works better for them. So as we built the hardware for Urika GX we were very mindful about the workloads our customers are trying to run and our ability to support that variety of workloads.
insideBIGDATA: How does the Urika GX stack up with benchmark results?
Ryan Waite: In terms of benchmarks, we can use GraphX that’s built into Spark with Jim Gray’s famous Pagerank benchmark using a data set of Twitter data running on a leading cloud provider’s high-performance compute instances (since a lot of our customers think that the cloud is the way they can evaluate big data solutions). We were twice as fast on the load and partition part of that benchmark and 4x faster on the actual benchmark part. One of the reasons for these results is because we have a very fast interconnect, so the shuffle operations in that benchmark just fly. We have these instances that are closely located to each other, and the locality issues you run into when you’re running in the cloud aren’t going to affect the Urika GX.
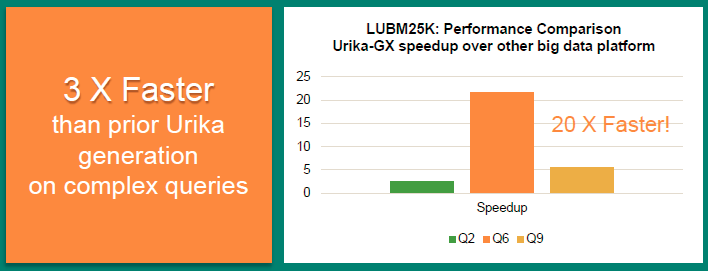
Our customers don’t just want to run big batch workloads, but they’re getting into these scenarios where they need to be more iterative or interactive in the way they were looking at their data. We wanted to make sure we supported that workload. One of the technologies that we provide that’s unique at Cray is the Cray Graph engine. This is the Graph technology at the core of the Urika-GD graph discovery appliance (that MLB purchased). The Urika-GD system was a purpose-built appliance for graph analytics. We’ve taken that technology and brought it into this general purpose platform for big data processing. And moving off the custom hardware we had with the GD, to the standard hardware we’re using in the GX, we were able to get a performance improvement of about 3x across a number of different benchmarks such as the LUBM25K benchmark which includes a number of different queries – queries 2, 6 and 9 which are enormously complicated queries where graph processing engines tend to have the greatest benefit. Even in the large 25K data set we’re seeing a huge speedup over our previous product Urika-GD. For query 6 it’s actually 20x faster. A lot of this is due to really embracing the Aries supercomputing interconnect and being able to use it as its backbone. For other workloads, like Spark workloads, they’re just going to see a really fast TCP/IP network.
insideBIGDATA: Circling back to your earlier comments, can you clarify your concept of “agile analytics?”
Ryan Waite: Right, this agile analytics platform is core to our strategy in building the Urika GX. We wanted to make sure our customers had the convenience of a pre-installed and pre-configured appliance with the flexibility to install any packages that they want on that system and not to feel they’re getting locked into a proprietary solution. By using a supercomputing approach we can provide unmatched performance for processing not just traditional Spark workloads but also workloads that are unique like the graph analytics workloads. We support a variety of workloads like Spark, Hadoop, graph and more. We have one customer that’s using Kafka as part of their framework so Kafka is running on the Urika GX as well as Spark and the Cray graph engine.
insideBIGDATA: How important are machine learning and deep learning to Cray’s strategy?
Ryan Waite: We’re very serious about the machine learning side of things including deep learning. First, Urika GX is great at running machine learning workloads especially if you’re using Spark ML. For customers who have embraced the GPU driven model for deep learning, we have the CS-Storm product which is one of the densest GPU offerings available on the market. CS-Storm supports up to 8 GPUs running at a full 300 watts per GPU. We did extra work on the hardware side to really beef up the signal integrity. That means fewer errors and better performance. We have customers looking at that system as a machine learning platform.
insideBIGDATA: Do you have any other compelling case studies you can tell us about?
Ryan Waite: One of our customers has about 5,000 network access points and 10s of thousands of devices plugged into the network. They’re a public company in the medical research sector and they have a lot of customers that come on site and become part of their network. They’re very anxious about network security and what they done is: they poll net flow logs, firewall logs, active directory logs and other types of logs in through a Kafka infrastructure, hand it off to Spark for some feature extraction along with typical ETL style massaging of the data and then they push the data into a Cray graph engine. What’s unique about graph technologies is you can use them to look for anomalies in your data set. So the customer is able to crawl through the network logs and identify unusual behavior and follow-up on that behavior to determine whether it is malicious or just unusual.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind