Examining Advances in Graph Exploration using Elasticsearch
Remember the famous ad from Sun Microsystems – “The Network is the Computer”? This same sentiment is increasingly being applied to data, but instead of cables connecting many machines, we are uncovering and unlocking relationships in our data. The majority of data that is created every day contains relationships. Some of these relationships are explicit, like following someone on twitter, or foreign keys in relational databases. In other cases, the links are less overt, less structured, and have historically been harder to work with. However, new technologies are unlocking this new type of data, and opening the door to entirely new use-cases.
Advances in search and data analysis have given us incredible powers to explore new relationships in even the largest of datasets. However, many commentators have come to realize that “Big Data” analysis is often limited by the imagination of the user, i.e. their ability/creativity to envision what relationships exist and understand which ones are important.
Graph analysis adds a new superpower, by highlighting undiscovered relationships in the data. Graph makes it easy to answer complex questions and address use-cases such as behavioral analysis, fraud, cyber security, drug discovery, personalized medicine, and to build personalized recommendations based on continuous real-time data.
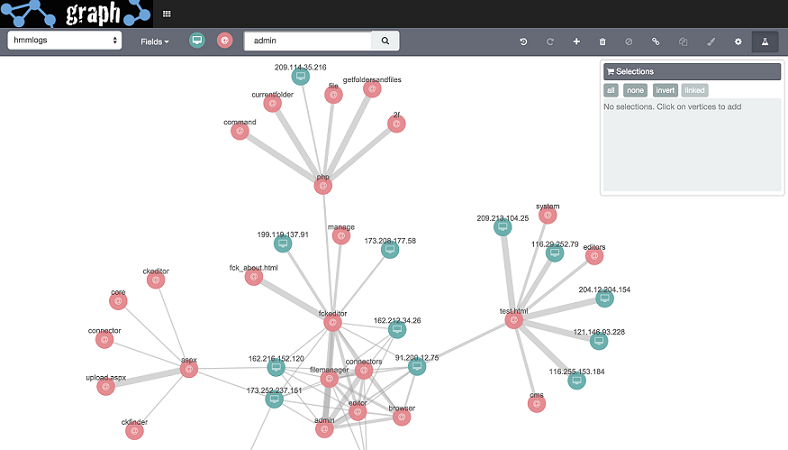
How it Works
Exploring and understanding the relationships in your data starts by identifying them. All data has some underlying structure, and it is this structure that lays the foundation for relationship exploration. With modern document-stores, it’s easy to store and query structured documents. These documents may represent information about a user, like their complete purchase history or their music preferences, or it they may represent observations or events in the real world, like a tweet, or individual purchases.
With traditional data analysis, we would look at these data and try to summarize and understand the properties of the aggregated data: What product did we sell the most? Who are our top customers? Which band is most popular? As we learn the answers, we may slice and dice the data further, asking more specific questions like: What was our top product in each category, in each region? What music is most popular with people under 30 in France? Even 5 years ago, these were difficult questions to ask of large amounts of data, but today, if those are the only questions you ask, you are missing a big opportunity.
Rather than summarize whole documents, imagine if you could visualize your data in powerful new ways to see relationships based on how documents or properties relate to each other. This is what graph delivers allowing you to see patterns that you never knew existed. Then, imagine you could ask a different type of question based on the new relationships you discovered …
Questions like, ”What other artists are most like Mozart?” Or even, ”What other products are most often purchased with diapers?” Or, perhaps, “What similarities are there between individual entities in the Panama Papers?”
The Mozart question provides the perfect example of why relevance, which is one of the biggest challenges within graph analysis, is so important. In a music recommendation engine based on the preference data of thousands or millions of users, you run the risk of simply returning the most popular bands, regardless of whether they are meaningful. You wouldn’t want to recommend the Beatles – who are universally popular, for good reason – to someone looking for music similar to Mozart.
The frequency of these so called “hyper-connected entities” within most people’s playlists, means that they would show up as being similar to even the most obscure, niche music genres. Likewise, analysis of grocery shopping, would show milk under “What products were most frequently bought together with…” simply because of the number of people who pick up a carton every time the visit the supermarket.
By combining graph analysis with search techniques, relevance can be used to bringing back the important results, and avoid frequent connections. Meaningful importance can be calculated by correlating the significance of each relationship in comparison to global averages.
This idea of using relevance in graph exploration has opened the door to asking more complex, and valuable questions. If you have log data from your web server, you have information about the IP address of incoming requests, and the URLs they were requesting. Could you use this information to detect attackers? If you know one attack vector (requests for /admin) could you use this information to find bad actors and other attack vectors? With music preference data, you can now build a personalized recommendation system that suggests the most relevant bands, given your demographics and likes.
While graph databases and search engines have been around for some time, in some ways, intelligent graph exploration is a new frontier in data analysis and understanding. Businesses who use their data more effectively outperform those who don’t, and early adopters of this technology are likely to have a leg-up on the competition. When you combine search relevance with graph exploration, you will be able to help your company respond more quickly to changes in customer behavior, market conditions, and solve some of the most complex use cases where the answers to those problems lie in the relationships in the data.
 Contributed by: Steve Kearns, Senior Director of Product Management at Elastic. Steve is responsible for the product team behind Elasticsearch, Shield, Watcher, Marvel, Graph, and Reporting. Prior to Elastic, he worked at DataGravity, Basis Technology, and BBN Technologies, in engineering and product management, where he designed and deployed search and analytics technologies to solve hard problems for some of the world’s most successful companies and agencies.
Contributed by: Steve Kearns, Senior Director of Product Management at Elastic. Steve is responsible for the product team behind Elasticsearch, Shield, Watcher, Marvel, Graph, and Reporting. Prior to Elastic, he worked at DataGravity, Basis Technology, and BBN Technologies, in engineering and product management, where he designed and deployed search and analytics technologies to solve hard problems for some of the world’s most successful companies and agencies.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind