 In this special guest feature, Victor Amin, Data Scientist at SendGrid, advises that businesses implementing machine learning systems focus on data quality first and worry about algorithms later in order to ensure accuracy and reliability in production. After graduating cum laude from Princeton University, Victor earned a PhD studying applications of machine learning to quantum chemistry at Northwestern University. At SendGrid, Victor builds machine learning models to predict engagement and detect abuse in a mailstream that handles over a billion emails per day.
In this special guest feature, Victor Amin, Data Scientist at SendGrid, advises that businesses implementing machine learning systems focus on data quality first and worry about algorithms later in order to ensure accuracy and reliability in production. After graduating cum laude from Princeton University, Victor earned a PhD studying applications of machine learning to quantum chemistry at Northwestern University. At SendGrid, Victor builds machine learning models to predict engagement and detect abuse in a mailstream that handles over a billion emails per day.
It’s obvious that you need data before you can implement a machine learning system, but project planners often overlook questions regarding training set collection, cleaning, and maintenance. There are so many sources of big data in today’s business systems that it seems like getting enough of the right data ought to be easy! Besides, algorithms are sexy, and people prefer to focus their attention on selecting and tweaking the best one.
This is a grave mistake.
When machine learning systems fail in production, the root cause can often be traced to flaws in data collection and labeling. Focusing on data first (and worrying about your algorithm last) is the best way to ensure that your new machine learning system exhibits superior performance and doesn’t cause any unpleasant surprises.
The Training Set is Key
In the early days of machine learning, the Army applied artificial neural networks to detect tanks camouflaged in foliage. They got impressive results, and were even able to classify images that were not used to train the algorithm. Encouraged, the researchers collected a fresh set of images and classified them with the algorithm, but they were dismayed to find that the results were now no better than flipping a coin. Only then did they realize: all of the tank images in their original dataset were taken on a sunny day, and all of the tank-free images were taken on a cloudy one. The algorithm was working, but it wasn’t detecting tanks, it was detecting whether or not the sun was out!
The training set (the data your machine learning system learns from) is the most important part of any machine learning system. For best performance, your training set should be optimized for both size and quality.
Bigger is Better
In the era of big data, it seems like having a big enough training set shouldn’t be a problem for most organizations. However, your training set size isn’t limited by how much data you have in total, but rather how big your “source of truth” is. For example, if you’re classifying tank images, the question isn’t how many images you have in total, but how many images you can be certain have or don’t have a tank in them (perhaps because a human labeled them).
Size matters. The bigger the training set, the better the model. But less obviously, and more importantly, the difference between a fancy algorithm and a simple one decreases with more data.
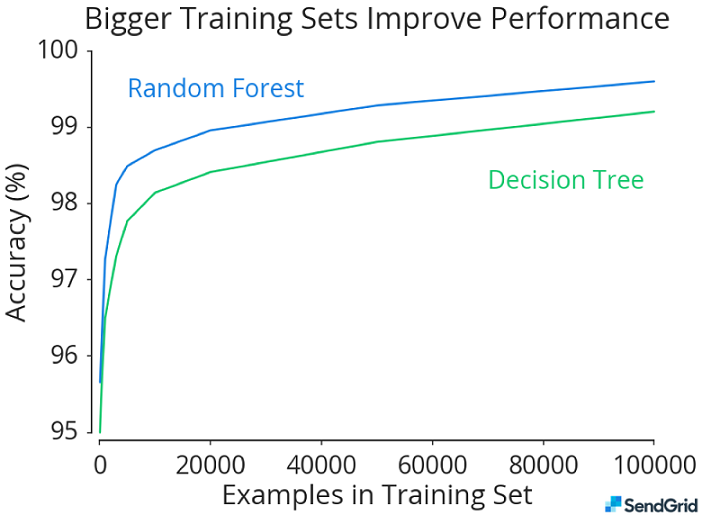
This chart shows that increasing the training set size improves performance for both Random Forest and Decision Tree algorithms on this problem. As the training set size increases, the performance gap between the algorithms shrinks.
If your time on a problem is limited (and when isn’t it?) it is generally more fruitful to try to get more data (embiggen your source of truth) than it is to tackle performance at the algorithm level.
Quality Matters
Even with the best algorithms and a huge training set, dirty data can tank your results. If your source of truth introduces errors into your labels, you will be surprised by them when your model hits production. This is why using the output of a machine learning classifier to supplement your training set is a big no-no: you will end up amplifying the errors of that classifier.
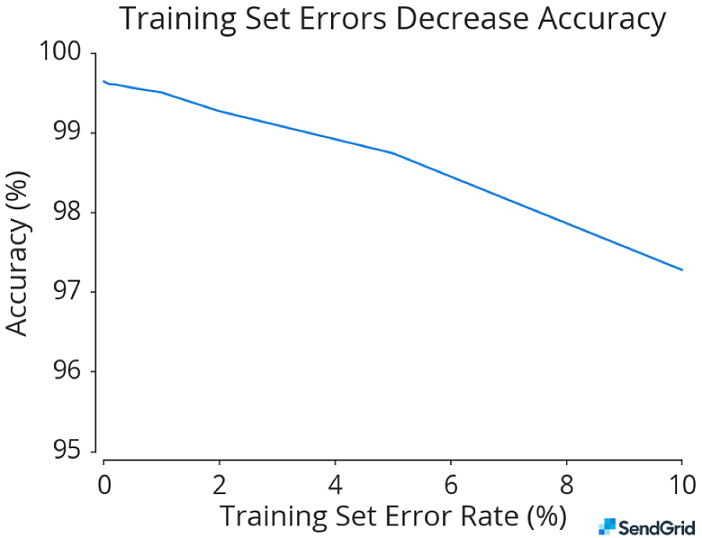
This chart is based on real data from a machine learning model in use at SendGrid. We artificially introduced errors into the training set to demonstrate the effect on accuracy. Even a modest amount of mislabeled data can tank performance.
Flaws in your data can be subtle, as the Army learned with their tank images. The more your training data looks like the data your machine learning system will handle in production, the less likely you will be to experience one of these flaws. If you want your system to be able to see a tank on a cloudy day, tanks on cloudy days had better be in your training set.
Focus on the Data First
Set the sexy algorithm questions aside. Your first step in planning a new machine learning system is to dial in a system for collecting, cleaning, and maintaining your training set.
Start by asking:
- How will we gather a large training set with accurate labels?
- How will we continue to expand the training set when the system is in production, to guard against rare events and changes in behavior?
Don’t rely on ad hoc, manual curation of training data. If you do, you will be slow to react when your production data change, and you won’t be taking full advantage of the data assets you have. Instead, build a system that samples production data, and have a mechanism for reliably labeling your sampled production data that isn’t your machine learning model. Build a source of truth that you can trust and that you can scale—at least to the degree you need to get a big (enough) training set.
Following this process, or something like it, will ensure that data quantity and quality are taken care of. You’ll end up with production systems that are accurate, robust, and aren’t hiding any surprises.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind