
In this special guest feature, Rob Farber from TechEnablement writes that modernized code can deliver significant speedups on machine learning applications.

Rob Farber, Founder, TechEnablement.com
Benchmarks, customer experiences, and the technical literature have shown that code modernization can greatly increase application performance on both Intel Xeon and Intel Xeon Phi processors. Colfax Research recently published a study showing that image tagging performance using the open source NeuralTalk2 software can be improved 28x on Intel Xeon processors and by over 55x on the latest Intel Xeon Phi processors (specifically an Intel Xeon Phi processor 7210). For the study, Colfax Research focused on modernizing the C-language Torch middleware while only one line was changed in the high-level Lua scripts.
NeuralTalk2
NeuralTalk2 uses machine learning algorithms to analyze real-life photographs of complex scenes and produce a correct textual description of the objects in the scene and relationships between them (e.g., “a cat is sitting on a couch”, “woman is holding a cell phone in her hand”, “a horse-drawn carriage is moving through a field”, etc.) Captioned examples are show in the figure below.

Figure 1: NeuralTalk2 examples (Source: https://github.com/karpathy/neuraltalk2)
The application uses a VGG (Visual Geometry Group) Convolutional net (VGG-net) and a Long Short-Term Memory (LSTM) recurrent neural network composed of standard input, forget, and output gates. As a result, these same optimizations to the Torch middleware should benefit other machine learning and image classification applications. The same code modernization techniques have been used to greatly accelerate other applications on both Intel Xeon and Intel Xeon Phi processors. A number are discussed in detail in the book, Intel Xeon Phi Processor High Performance Programming: Knights Landing Edition 2nd Edition edited by Jim Jeffers and James Reinders.
The Colfax Research Effort and Results
The Colfax Research team examined the effect of a number of different optimizations. The impact of these optimizations are shown in Figure 2.
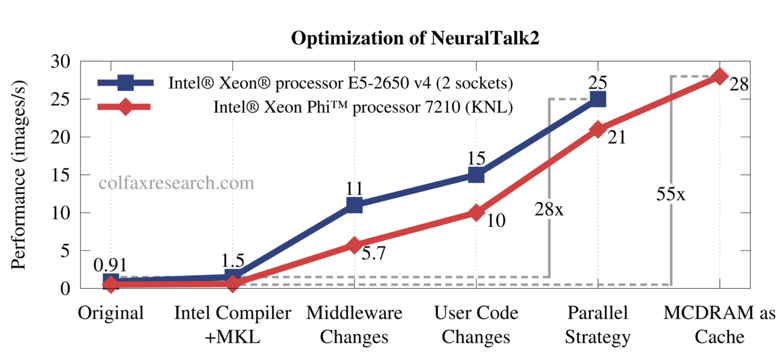
Figure 2: Significant performance gains through code modernization (Source: Colfax Research)
Intel Compiler + MKL (Intel Math Kernel Library)
The first obvious step was to rebuild the open source Torch code using the Intel compiler and Intel MKL library. According to Figure 2, this resulted in a roughly 1.5x speedup on the Intel Xeon processor.
Modernizing the code
Code modernization efforts shown as Middleware Changes, User Code Changes, and Parallel Strategy in Figure 2 delivered the bulk of the performance improvements:
- Improved various layers of VGG net with batch GEMMs, loop collapse, vectorization and thread parallelism.
- Improved the LSTM network by vectorizing loops in the sigmoid and tanh functions and using optimized GEMM in the fully-connected layer. Single-precision performance was improved by calling the appropriate precision function.
Many code modernization efforts use the same techniques
Ryo Asai (Researcher, Colfax Research) reaffirmed the results shown in Figure 2 that the bulk of the Intel Xeon and Intel Xeon Phi performance improvements occurred as a result of code modernization efforts that focused on: (a) increasing parallelism, (b) efficiently utilizing the vector units, and (c) making use of high-bandwidth Intel Xeon Phi processor memory.
![Figure 3: The importance of using both parallelism and vectorization (Image courtesy Intel [1])](http://insidebigdata.com/wp-content/uploads/2016/09/3.png)
Figure 3: The importance of using both parallelism and vectorization (Image courtesy Intel [1])
The Colfax Research team utilized both the data parallel and task parallel nature of the Intel processors to maximize performance. Data parallelism distributes data across all the cores which is then processed in parallel. In contrast, task parallelism distributes tasks in parallel across all the cores. Each of the tasks (which may differ between cores) are then executed in parallel. Some of the tasks may also utilize parallelism internally, which exemplifies one form of nested parallelism. For example, the team distributed batches of DGEMM matrix operations across the cores. This allowed multiple images to be forwarded through the network in parallel. These smaller parallel tasks were handled by the Intel MKL library in groups of 64. On a general note, load balancing can be a challenge with task parallelism as some tasks may finish faster than others (sometimes significantly faster) which can leave some cores underutilized unless the programming team takes appropriate action to “balance the load” across all the cores. In the NeuralTalk2 case, the amount of work was constant per DGEMM so there were no load balancing issues.
Asai noted that simply adding the appropriate OpenMP pragma (a language construct that helps the compiler process a code block to do things like generating a parallel region of code) was all that was required to parallelize some loops. In particular, the “omp simd” pragma was used to help some data parallel loops parallelize. Some sections of code were more complicated and required rewriting the code to make it amenable to parallelization. In particular, the team found that a complicated “for loop” structure had to be rewritten so the compiler could auto-vectorize the loop. Nested loops also presented a problem as the parallelism of the innermost (sometime called the lowest level) loop was not sufficient to fully utilize the available cores on either the Intel Xeon or Intel Xeon Phi processor. The Colfax Research team specifically removed nested loops and by restructuring the code and/or collapsing the nested loops to increase the amount of parallelization.
As shown in Figure 3, increasing the parallelism through multi-threading is only part of the performance optimization story as the instruction level parallelism of the per-core vector processors must also be utilized to achieve the highest-levels of performance. For example, the new Intel Xeon Phi processors have two AVX-512 vector units per core. Fully utilizing these vector units can increase single-precision floating-point performance by 8x per vector unit, or 16x when utilizing both Intel Xeon Phi per core vector units [1], or 4x and 8x respectively when using 64-bit double-precision data types. One can understand the tremendous performance improvement that can be achieved on these processors by multiplying the vector speedups by the up to 72 cores on those processors. Basically, code modernization efforts strive to convert the code to run as far into the lower right hand quadrant of Figure 3 as possible (e.g. high parallelism coupled with high vectorization).
The Colfax Research team also performed several other performance optimizations:
- Incorporated algorithmic changes in the code of NeuralTalk2 in an architecture-oblivious way (e.g., replaced array sorting with top-k search algorithm contained in the Torch middleware that efficiently finds the top k elements in an array). Asai noted this accounted for the one-line change to the Lua source as it was deemed acceptable to call a more efficient sort function that already existed in the Torch middleware.
- Improved the parallel strategy for increased throughput by running several multi-threaded instances of NeuralTalk2 including pinning the processes to the respective processor cores. Essentially this is another way to increase parallelism.
- Took advantage of the high-bandwidth memory (HBM) based on the MCDRAM technology by using it in the cache mode.
The latter point – taking advantage of the 16GB of MCDRAM memory that is available on some of the new Intel Xeon Phi processor products – provided a nearly 25% increase in image tagging performance. Multi-Channel DRAM (MCDRAM) provides nearly 4x more memory bandwidth than conventional DDR4 memory [2]. This additional bandwidth can greatly accelerate memory bandwidth limited applications. Asai noted that on average their system (an Intel Xeon Phi processor 7210) delivered up to 82 GB/s for DDR4 bandwidth while the MCDRAM delivered around 450 GB/s. (He did say that the MCDRAM bandwidth fluctuated a little bit because the data was read so quickly). Thus the Colfax Research team saw that the MCDRAM delivered more than 5x bandwidth performance compared to the DDR4 memory.
The Intel Xeon Phi MCDRAM can be configured in several different ways as shown below. One of the easiest ways that requires no programmer intervention or code modifications is to boot the processor in cache mode, where the hardware keeps the most frequently used pages in the fastest memory.
![Figure 4: Intel Xeon Phi MCDRAM memory modes (Source: hotchips [3])](http://insidebigdata.com/wp-content/uploads/2016/09/4.png)
Figure 4: Intel Xeon Phi MCDRAM memory modes (Source: hotchips [3])
Code modernization greatly improves deep learning performance on CPUs
The code modernization benefits observed by Colfax Research on NeuralTalk2 are consistent with findings of other groups examining the CPU code efficiency of open source machine learning packages. For example, a Kyoto University Graduate School of Medicine research team determined that the performance of the open source Theano C++ multi-core code could be significantly improved. Theano is a Python library that lets researchers transparently run deep learning models on both CPUs and GPUs. It does so by generating C++ code from the Python script for the destination architecture.
Kyoto worked with Intel to optimize the Theano library. The following figure shows that a CPU optimized version of the Theano library (middle two bars) running on a dual-socket Intel Xeon E5-2699v3 chipset runs a large Deep Belief Network (DBN) up to 8.78x faster than the original open source CPU code (leftmost double bars). The rightmost double bars show that this v3 Haswell uArch processor set beats an NIVDIA K40 by as much as 1.72x [4]. The two bars in each group represent the performance of different neural network architecture sizes. Succinctly, the big story behind this figure is the performance increase over the original open source code (over 8x) that made an Intel Xeon CPU competitive against a GPU. The expectation is that the new Intel Xeon Phi processor will deliver even greater performance gains.

Figure 5: Original vs optimized performance on an Intel Xeon and performance of the optimized CPU code relative to a GPU. (Higher is better) (Source: Intel Corporation)
The Kyoto University Graduate School of Medicine is applying various machine learning and deep learning algorithms such as DBNs to problems in life sciences including drug discovery, medicine, and health care.
Accounting for the minor 2x difference in speedup between the Intel Xeon and Intel Xeon Phi Processors
Asai explained that the Colfax Research effort focused on optimizing only the Torch middleware. This meant the Colfax Research team had to ignore one section of the Lua scripts that limits the parallelization when running on the greater number of cores of an Intel Xeon Phi processor. However there is sufficient parallelization to use the lower core count of the Intel Xeon chipset. More specifically, the Xeon Phi processor greatly outperforms Xeon processor on the VGG-net, but the dual Xeon processors catch up during the calculation of the LSTM. This is why Colfax Research reports only a 2x difference between the reported Intel Xeon Phi and the Intel Xeon speedups (or a roughly 10% difference in number of images tagged per second). The Colfax team uploaded their changes to https://github.com/ColfaxResearch/neuraltalk2 so others can reproduce their work and, should they wish, modify the Lua scripts to realize the full Intel Xeon Phi processor performance capability.
Summary: Common themes for code modernization
The techniques that provided the bulk of the performance improvements (e.g. increasing parallelism, efficiently utilizing vectorization, making use of faster MCDRAM performance) for the Colfax Research team have also delivered significant performance improvements on both Intel Xeon and Intel Xeon Phi processors for a number of other code modernization projects as well. Each of the chapters in the previously mentioned, Intel Xeon Phi Processor High Performance Programming: Knights Landing Edition 2nd Edition book provides detailed code analysis, benchmarks, and working code examples spanning a wide variety of application areas to help developers achieve success in their own code modernization projects. Developers should also checkout the extensive technical material and training around Code Modernization at the Intel Developer Zone: https://software.intel.com/modern-code. In addition, see how to apply Machine Learning algorithms to achieve faster training of deep neural networks https://software.intel.com/machine-learning. Information about Colfax Research can be found at colfaxresearch.com.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at info@techenablement.com.
[1] https://software.intel.com/en-us/blogs/2013/avx-512-instructions
[3] Slide 10 of 10 of http://www.hotchips.org/wp-content/uploads/hc_archives/hc27/HC27.25-Tuesday-Epub/HC27.25.70-Processors-Epub/HC27.25.710-Knights-Landing-Sodani-Intel.pdf
[4] Comparison based on the processors available at the time of the Kyoto benchmark.
Sign up for our insideBIGDATA Newsletter



Speak Your Mind