Sponsored Post
With the open source research code WARP3D for 3-D nonlinear analysis of solids, the importance of vectorization is gaining traction once again. Also on GitHub, , the research code focuses on such simulations to support the development of safety and life prediction methodologies for critical components found typically in energy production and related industries. The discipline emphasis (3-D nonlinear solids), open source, and manageable code size (1,400 routines) appeal to researchers in industry and academia. The appeal is based on a computational technique known as vectorization.
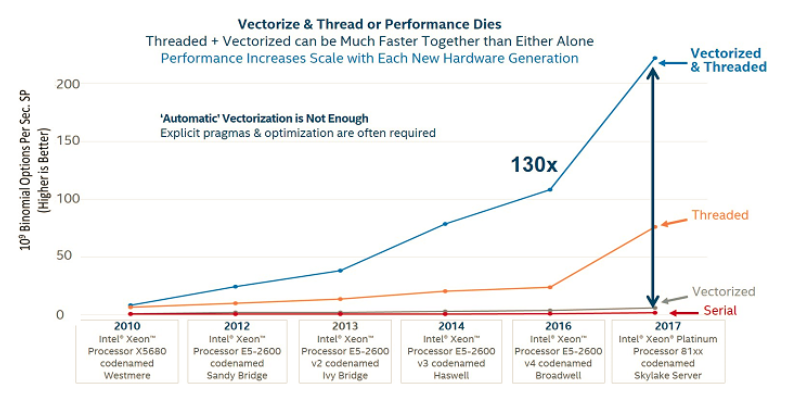
Once the mainstay of high-performance computing (HPC), vectorization has reemerged with new importance given the increasing width of SIMD (vector) registers on each processor core: four doubles with AVX2, eight with AXV-512. Increased vector lengths create opportunities to boost performance in certain classes of software (e.g., large-scale finite element analysis to simulate the nonlinear behavior of mechanical systems).
WARP3D reflects the current hierarchy of parallel computing: MPI to access multiple nodes in a cluster, threads via OpenMP on each node, and vectorization within each thread. Realistic simulations to predict complex behavior (e.g., the internal stresses created in welding a large component) require many hours of parallel computation on current computers. The pervasive matrix operations to achieve solutions map very well onto this hierarchy of parallel computing. Increased use of vectorization at the core level provides a direct multiplying effect on performance across concurrently executing threads and MPI ranks.
Vectorization as implemented in WARP3D was developed continuously over the last 20 years, and the code adopts many of the evolving features in Fortran. The contributors employ components of Intel® Parallel Studio XE, (Intel® Fortran Compiler, Intel® Math Kernel Library, and Intel® MPI Library) to build executables included with the open source distribution for Linux, Windows, and MacOS. WARP3D follows an implicit formulation of the nonlinear finite element method that necessitates solutions for very large, evolving sets of linear equations—the PARDISO and CPARDISO packages in Intel Math Kernel Library provide exceptional performance. Examples described here also illustrate the new Intel® Advisor 2017 with roofline analysis that enables more convenient and in-depth exploration of loop-level performance.
[clickToTweet tweet=”Vectorization offers potential speedups in codes with significant array-based computations” quote=”Vectorization offers potential speedups in codes with significant array-based computations”]
Vectorization offers potential speedups in codes with significant array-based computations—speedups that amplify the improved performance obtained through higher-level, parallel computations using threads and distributed execution on clusters. Key features for vectorization include tunable array sizes to reflect various processor cache and instruction capabilities and stride-1 accesses within inner loops.
The importance of vectorization to increase performance will continue to grow as hardware designers extend the number of vector registers to eight doubles (and hopefully more) on emerging processors to overcome plateauing clock rates and thread scalability.
Intel Advisor, especially the new roofline analysis capability, provides relevant performance information and recommendations implemented in a convenient GUI at a level suitable for code developers with differing levels of expertise.
Download your free 30-day trial of Intel® Parallel Studio XE 2018



Speak Your Mind