Sponsored Post
Machine learning and its younger sibling deep learning are continuing their acceleration in terms of increasing the value of enterprise data assets across a variety of problem domains. A recent talk by Dr. Amitai Armon, Chief Data-Scientist of Intel’s Advanced Analytics department, at the O’reilly Artificial Intelligence conference, New-York, September 27 2016, focused on the usage of Intel’s new server processors for various machine learning tasks as well as considerations in choosing and matching processors for specific machine learning tasks.
Intel formed a machine learning task force with a mission to determine how the company can advance the machine learning domain. The vast majority of machine learning code today runs on Intel servers but the company wanted to do even better for the present and the future use cases.
We need to understand the needs for these domains and prepare processors for those needs,” said Dr. Amitai Armon. “This is not a simple challenge because in machine learning you have many algorithms, many data types and the field is constantly evolving. The algorithms that are most popular today are not the ones that were most popular four or five years ago. And in four or five years from now, the most popular algorithms will be different. So how can we be ready for the future?”
The main thing the task force did was developing a benchmark that aimed to represent the machine learning domain that included potential changes that might happen to the domain. Of course no one can predict the future, so the team looked into the past. They examined around 80 algorithms from the past several decades and tried to examine the compute characteristics. They found out that even though the algorithms have changed, the small set of compute building blocks used tended to remain the same over time. Their approach was to cover those building blocks. The benchmark represents all the compute building blocks required in the past, and hopefully will cover the needs in the future as well. They were ready for a variety of possibilities.
There are three main types of compute tasks that play main roles in machine learning:
- Dense Linear Algebra – CNN, RNN, SVM, k-Means, GMM, ALS, Logistic Regression, PCA
- Sparse Linear Algebra – Sparse k-Means, Sparse SVM, Sparse PCA, Sparse Logistic Regression
- Data Dependent Compute – Apriori, Decision Tree, Random Forest, Adaboost, XGBoost, LDA
Another thing we observed is that compute is not the whole story,” said Dr. Amitai Armon. “The hardware bottleneck of machine learning algorithms is often not the compute but rather the memory bandwidth. You have enough compute power but you don’t have enough bandwidth accessing the memory to get the data to the processor. In our analysis, these two types of bottlenecks have roughly equal importance. Of course the importance depended on the algorithm, the data size, model size and so on. A third thing we observed was that deep learning open-source could be dramatically optimized for Intel hardware. We used in our analysis optimized deep learning code that ran very fast, we observed an order of magnitude faster than the open-source code that everyone uses, libraries like Caffe and others.”
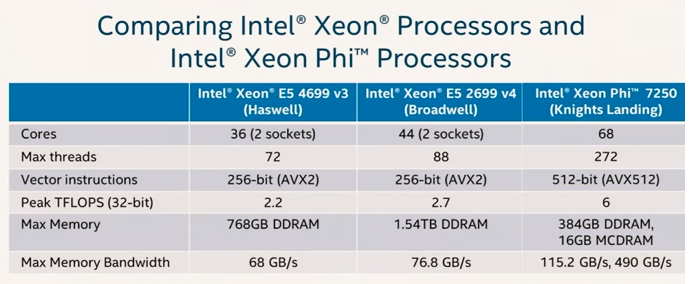
How this help in selecting the right processor for the right task? How do we know what to compare out of the many specifications for processors. In the figure below, we see a comparison of three generations of Xeon processors which represent the high-end of each processor family. For example the v4 has more cores than the v3. The v4 has more threads which means you can parallelize more data. Both have vector instructions which means you can apply an operation to a vector of numbers. Notice that peak TFLOPS (teraflops, or trillion floating point operations per second), max memory, and memory bandwidth all increased from the v3 to the v4.
Now consider Xeon Phi. This processor allows for more parallelization – more cores, many more threads, the vector instructions can operate on vectors of twice the size, peak TFLOPS is much higher, and highly increased memory bandwidth – all important for training neural networks.
How Does This Influence Data Scientists?
Just having better hardware is not enough to have influence on data scientists. We must have software that leverages the improved features of the hardware. Intel is optimizing the analytics software, the low-level libraries for the new processors, focused on deep learning.
[clickToTweet tweet=”Intel is optimizing the analytics software, the low-level libraries for the new processors, focused on deep learning.” quote=”Intel is optimizing the analytics software, the low-level libraries for the new processors, focused on deep learning.”]
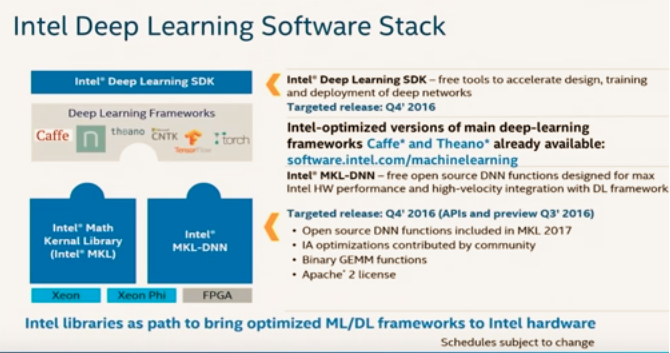
MKL is a free library of mathematical primitives (including linear algebra, vector math, random number generators, statistics, and many more) that is summarized in the figure below. MKL is optimized for Intel architecture including the Xeon Phi.

Deep Learning Software Stack
Data scientists don’t always write software which uses MKL. They often use higher level libraries. This is why Intel also is optimizing other open source libraries that data scientists are using. The figure below shows the software stack for deep learning. You can see at the bottom MKL is optimized for Xeon and Xeon Phi. It also will be optimized for FPGA. Also shown is open source MKL-DNN which helps with deep neural networks.
The deep learning frameworks are listed as well: Caffe, Theano, CNTK, and Torch. Intel is optimizing for these frameworks to make sure they get the best performance.
Also referenced is the Intel Deep Learning SDK which is another free product that is a tool allowing you to install necessary Intel optimized libraries quickly. The tool includes wizards that help you build neural networks easily without lots of prior knowledge.
Benchmark Performance for Training and Inference
Essentially Intel is optimizing hardware and also software. What are the results? In the figure below we see a benchmark for training a deep learning network AlexNet with different Xeon processors. The performance of open source is not very impressive. Using KML got a 6x speedup. After MKL was optimized, there was another 2x, and after Xeon Phi optimization there was yet another 2x. All in all, that’s a 24x speedup. For inference the speedup is even higher, 31x.

Traditional Machine Learning
Intel is also developing another free library called Data Analytics Acceleration Library (DAAL). This library has many machine learning primitives. DAAL is being optimized for the new Xeon Phi.
Current recommendations are to use Xeon Phi on deep learning, specifically training deep learning networks. For other types of machine learning, including deep learning inference, the preference is to use Xeon. The road map for future use of Xeon Phi for deep learning is impressive for improved efficiency, optimized for scale-out, enhanced variable precision, and flexible, high capacity memory.
There’s also an effort to build accelerators for deep learning. New Intel-optimized versions of Caffe and Theano already enable efficient training and inference on the new Intel Xeon and Xeon Phi. Scale-out support enables further speedup. Plus, innovative accelerators based on either FPGA or the Nervana engine will further enhance performance in the future.
Summary
Machine learning consists of diverse and fast evolving algorithms, using several main compute building blocks and requiring high memory bandwidth. Intel Xeon Phi offers enhanced performance for dense linear algebra, most notably for deep learning training. Intel has optimized the deep-learning software stack for both Intel Xeon and Intel Xeon Phi, including enable efficient scale-out on multiple nodes.



Speak Your Mind