Language and names are funny things. In an industry developing precise, highly-engineered data management and analytical software, we still often struggle to find words to describe the actual software. We use analogies and metaphors to explain capabilities which are different from existing approaches. Take for instance the “data lake” concept.
451 Research just published a new research titled, “Beyond the data lake: The rise of managed self-service and the data bazaar.” In it, Matt Aslett describes a bit of the history of the data lake concept and how it has evolved from a bit of a dumping ground or swamp for any and all data to a self-service “data bazaar” which is much more agile and collaborative of an environment where you can find a variety of data “products.”
Is the Data Lake Different from a Data Warehouse?
In a word, “yes.” Cynics will say that the data lake is just a new marketing term to sell a need breed of technology to recreate what was already achievable in the data warehouse. But the onslaught of big data pushed data warehouses to their limits in flexibility for the end user analysts.
My personal view from 15 years in the BI and data warehousing industry is that we have, in fact, evolved. We have evolved both in terms of business requirements and technical capabilities to serve those needs. To me, data warehouses provide a highly normalized and pre-meditated data environment where you can (usually) trust the data and results to be 100% accurate.
But that precision comes at a cost – both time and money. As business users want to look at new data to explore and discover new insights, the process can be cumbersome and expensive. I’ve talked with companies that take 6 months and $1 million of cost to add a new view or new dimensions to their data warehouse and roll it out to the business. That is completely unacceptable in the agile and on-demand world in which we live.
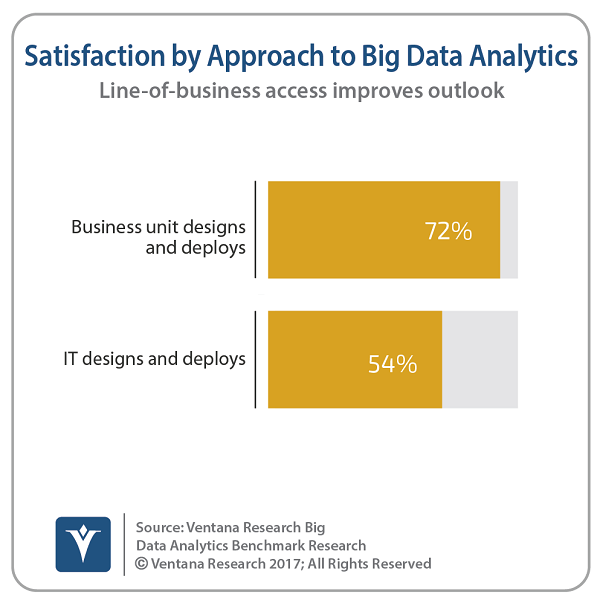
In fact, recent stats from Ventana Research show that many organizations have become too reliant on IT for big data analytics. Nearly two-thirds (61%) of the organizations participating in Ventana’s benchmark research said they either rely on IT or require the assistance of IT to create big data analytics. Only one-quarter (24%) make direct access by line-of-business employees the primary way they provide big data analytics. Those organizations that do provide that direct access have the highest rates of satisfaction – 72 percent compared with 54 percent when IT resources are required.
The need for schema-on-write in a RDBMS-based data warehouse is replaced with “schema-on-read” flexibility which also comes at a cost in terms of the performance and lack of data definitions, at times. Speed is of the essence to a marketer trying to get a general sense of consumer sentiment and general trends in interest for a product. Performing data visualization and BI across multiple digital touchpoints for a customer needs to happen quickly and on a complete set of data to get deeper insights immediately. A data lake is perfect for this use case. The CFO wants an exact science and guaranteed precision in the results and the way revenue is recognized and calculated. Here, pre-defined schemas, data transformation and quality are essential and likely already exist within a data warehouse or other RDBMS-based system. The point is that the data lake is not meant to replace existing systems which work well, but to enable the business with new insights quickly across new, multi-structured data sources.
Data Lakes Promise Deeper Insights – But Have Fallen Short for Business Analysts
Data lakes, as they are commonly defined, provide more flexibility both in terms of how data is stored (i.e., it’s typically a file system or object store like Amazon S3 instead of an RDBMS), as well as the processing engines and techniques available on the data (i.e., procedural languages via Apache Spark, R, and others, as well as declarative, SQL-based approaches with SQL-on-Hadoop projects such as Apache Hive, Apache Impala, and Apache Drill).
As Ventana points out in recent research,
Unfortunately, that’s not the way line-of-business users want to analyze data, which creates a challenge for many organizations.”
Another research firm, Gartner, in their report “Chief Data Officers Must Address Three Critical Requirements to Derive Value From Data Lakes”, says,
The purpose of a data lake is to present an unrefined view of data to only the most highly skilled analysts, to help them explore their data refinement and analysis techniques independent of any of the system-of-record compromises that may exist in a traditional analytic data store (such as a data mart or data warehouse).”
But if you’re only going to give data scientists and “the most highly skilled analysts” access to the data lake, you’re missing out on a HUGE asset to the organization! It’s no wonder Gartner predicts in that same data lake report that, “through 2018, 90% of deployed data lakes will become useless because they are overwhelmed with information assets captured for uncertain use cases”.
What’s missing? The business analyst or “power user” who can bridge the gap between the use cases and needs of the business, and the richness of big data now available to them. Most business users want GUI-based BI tools to access, analyze, and share information – speeding and easing the flow of insights.
But, can existing BI tools stand up to big data? Ventana goes on to say,
Our research shows that Business Intelligence (BI) tools are used by three-quarters of organizations to perform big data analytics, but using them is not always easy and not always effective. Most BI tools were not designed to deal with big data technologies or the volumes of data involved. Nor were these big data technologies designed for the interactive analytical queries that users demand. As a result, many organizations find their data lakes going unused or underutilized.”
So, in summary, 75% of companies are trying to use BI tools to get value from data lakes whether they’re in Hadoop or S3/cloud storage, but they’re not working well enough. Is that why Hadoop and data lakes are getting a bad rap? The promise of Hadoop and big data may be in a “trough of disillusionment,” but as industry observer Andrew Brust points out, “…the less you hear about Hadoop, the more popular it’s likely becoming. As a back-end workhorse for huge volumes of data, it’s the way to go.”
I agree 100%. Any disillusionment with Hadoop or data lakes is not because the data platform isn’t working. Scale, speed, and security have all been fixed. It’s a lack of self-service access for business end users measured on those same dimensions – scale, speed, security… and of course, ease of use.
Better Choices for BI on Data Lakes
So, what are the answers to unlocking the value of big data with BI to end users? BI tools are being reinvented to work natively with big data platforms and the results are leading to more and better choices for companies to create value from their data lakes.
About the Author
 Steve Wooledge is Vice President of Marketing at Arcadia Data, the provider of the first native visual analytics software for big data. Steve is responsible for Arcadia Data’s overall go-to-market strategy. He is a 15-year veteran of enterprise software in both large public companies and early-stage start-ups and has a passion for bringing innovative technology to market. Previously, Steve was with MapR Technologies where he ran all product, solution, and digital marketing for their converged data platform. He previously held senior management positions in marketing at Teradata, Aster Data (acquired by Teradata), Interwoven (acquired by HP), and Business Objects (acquired by SAP), as well as sales and engineering roles at Business Objects, Covalex, and Dow Chemical.
Steve Wooledge is Vice President of Marketing at Arcadia Data, the provider of the first native visual analytics software for big data. Steve is responsible for Arcadia Data’s overall go-to-market strategy. He is a 15-year veteran of enterprise software in both large public companies and early-stage start-ups and has a passion for bringing innovative technology to market. Previously, Steve was with MapR Technologies where he ran all product, solution, and digital marketing for their converged data platform. He previously held senior management positions in marketing at Teradata, Aster Data (acquired by Teradata), Interwoven (acquired by HP), and Business Objects (acquired by SAP), as well as sales and engineering roles at Business Objects, Covalex, and Dow Chemical.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind