In the previous article, we gained an understanding of the main Kafka components and how Kafka consumers work. Now, we’ll see how these contribute to the ability of Kafka to provide extreme scalability for streaming write and read workloads.
Kafka was designed for Big Data use cases, which need linear horizontal scalability for both message producers and consumers, and high reliability and durability. Partitions, replicas and brokers are the underlying mechanisms that provide the massive distributed concurrency to achieve this goal.
Write Scalability
Kafka was designed to cope with ingesting massive amounts of streaming data, with data persistence and replication also handled by design. This is critical for use cases where the message sources can’t afford to wait for the messages to be ingested by Kafka, and you can’t afford to lose any data due to failures.
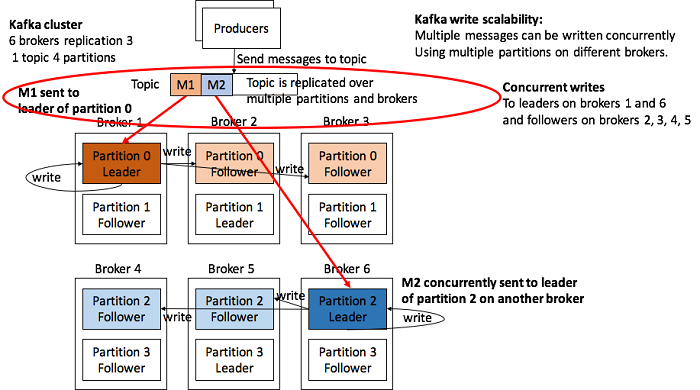
The following diagram will illustrate Kafka write scalability.
But first, for simplification, we assume there is a single topic, with lots of producers sending messages to the topic. How will Kafka keep up with this potentially massive write load, and ensure there are sufficient copies so that no data is lost even if some brokers fail?
The trick is to distribute the write load over multiple brokers. We assume our Kafka cluster has:
- Six brokers;
- A replication factor of three (each message is written to 3 brokers);
One topic and four partitions (the topic is split into four parts; each event is sent to a specific partition based on a hash
It works like this:
Message 1 (M1) is sent by a producer to the topic and the hash of the key determines that it will be sent to partition 0. The leader of partition 0 is on broker 1 which writes the message to the local log (persisted to disk), and also makes it available to the follower replicas on broker 2 and 3 who also write the message to their local logs. If another message (M2) is sent by a producer to the topic at the same time as M1, it can also be processed concurrently as follows. In this case the hash function determines that M2 should be sent to Partition 2, and it is sent to the leader of partition 2 which is on broker 6, where it is written locally, and also made available to the partition 2 followers (on brokers 4 and 5) who also write the message to their local logs.
Read Scalability
It’s all very well being able to get lots of data into Kafka. But what’s the use of that unless we can also get it out just as easily?
Fortunately, Kafka was also designed to make it easy to consume the data to (and interestingly we’ve already seen this happening in the write explanation above, as followers are just consumers which replicate the message from the partition leader).
How does read scalability work? If there are multiple consumers for a topic, Kafka must be able to keep up with multiple concurrent reads. Multiple partitions and brokers are again the key.
The following diagram shows multiple consumers reading messages from a single topic. Assuming that four messages (M1 to M4) have been previously written to the topic, and each message is in a different partition (Partitions 0 to 3), then consumers can read messages concurrently from the leaders of each partition. A consumer can read M1 from partition 0 leader on broker 1, another consumer can read M2 from partition 2 leader on broker 6, and so on. In practice, this means that Kafka is even more scalable for reads, and will supports large numbers of consumers reading both new messages and old messages, reading the same events, and reprocessing many events etc.
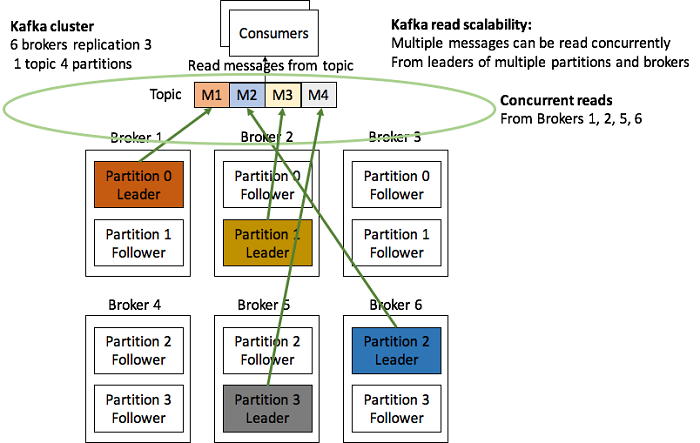
Note that a topic can only support as many consumers (in the same consumer group) as it has partitions, so it pays to create topics with more partitions than you initially need to allow for future load growth (but not too many more!). Also, the replication factor does not impact read concurrency.
Finally, it’s worth noting that Kafka supports write and read scalability at the same time. This means you can stream enormous amounts of data to Kafka and carry out close-to-real-time processing of the messages – including sending messages to other systems – for multiple different purposes concurrently. The applications are really only limited by your imagination.
About the Author
 Paul Brebner is Tech Evangelist at Instaclustr, which provides a managed service platform of open source technologies such as Apache Cassandra, Apache Spark, Elasticsearch and Apache Kafka.
Paul Brebner is Tech Evangelist at Instaclustr, which provides a managed service platform of open source technologies such as Apache Cassandra, Apache Spark, Elasticsearch and Apache Kafka.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind