 When we discuss about artificial intelligence (AI), how are machines learning? What kinds of projects feed into greater understanding? For our friends over at IBM, one surprising answer is movies. To build smarter AI systems, IBM researchers are using movie plots and neural networks to explore new ways of enhancing the language understanding capabilities of AI models.
When we discuss about artificial intelligence (AI), how are machines learning? What kinds of projects feed into greater understanding? For our friends over at IBM, one surprising answer is movies. To build smarter AI systems, IBM researchers are using movie plots and neural networks to explore new ways of enhancing the language understanding capabilities of AI models.
IBM will present key findings from two papers on these topics at the Association for Computational Linguistics (ACL) annual meeting this week in Melbourne, Australia.
In the first paper, scientists found a surprising side effect of the movie business – movies can teach machines what humans view as common sense. This research focuses on IBM’s DuoRC dataset (see below for a sample of the movies this project looked at), which contains 186,089 unique question-and-answer pairs based on 7,680 pairs of movie plots. Each movie plot pair reflects two different summaries of the same movie – one from Wikipedia and the other from IMDb – written by two different authors. This approach minimizes overlapping vocabulary and ensures different levels of plot detail in the pairs. This forces the AI models to perform complex reasoning to answer questions about each movie while demonstrating an effective new technique for improving the reading comprehension of AI systems.
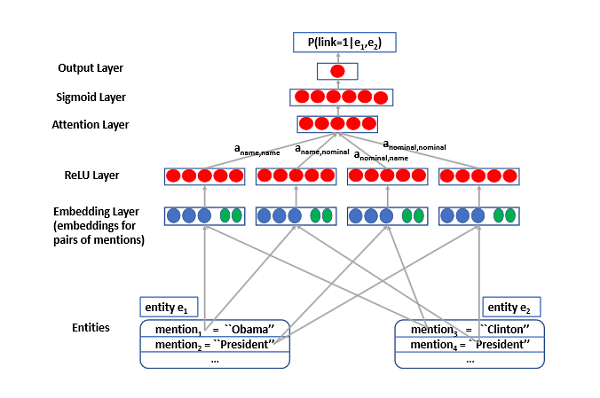
The second paper addresses how neural networks can improve the speed and accuracy of the AI algorithms behind search engines and question-answering systems. When teaching a machine to read text, AI models typically use two basic techniques – “co-reference resolution,” which finds all expressions that refer to the same entity in a document, and “entity linking,” which resolves any ambiguous names of entities in a text using a knowledge base like Wikipedia (e.g., to help the AI system understand if it needs to talk about “Bush” the rock band or “George W. Bush” the former U.S. president to answer a question). The IBM’s team innovation is that the model is trained in one language and can be applied to another without the need for new training data making it possible for cross-lingual applications.
**IBM’s DuoRC dataset has about 8,000 movies. Here are some sample titles:
The Shawshank Redemption (1994)
The Godfather (1972)
The Dark Knight (2008)
12 Angry Men (1957)
Schindler’s List (1993)
The Lord of the Rings: The Return of the King (2003)
Pulp Fiction (1994)
The Good, the Bad and the Ugly (1966)
Fight Club (1999)
Forrest Gump (1994)
Star Wars: Episode V – The Empire Strikes Back (1980)
Inception (2010)
One Flew Over the Cuckoo’s Nest (1975)
The Matrix (1999)
City of God (2002)
Se7en (1995)
The Silence of the Lambs (1991)
The Usual Suspects (1995)
Saving Private Ryan (1998)
Léon: The Professional (1994)
The Green Mile (1999)
Interstellar (2014)
American History X (1998)
Psycho (1960)
The Intouchables (2011)
The Pianist (2002)
The Departed (2006)
Terminator 2 (1991)
Back to the Future (1985)
Raiders of the Lost Ark (1981)
Rear Window (1954)
Gladiator (2000)
The Lion King (1994)
The Prestige (2006)
Memento (2000)
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind