When working in healthcare, a lot of the relevant information for making accurate predictions and recommendations is only available in free-text clinical notes. Much of this data is trapped in free-text documents in unstructured form. This data is needed in order to make healthcare decisions. Hence, it is important to be able to extract data in the best possible way such that the information obtained can be analyzed and used.
State-of-the-art NLP algorithms can extract clinical data from text using deep learning techniques such as healthcare-specific word embeddings, named entity recognition models, and entity resolution models. Such Algorithms use trained models to find relevant words in a body of text. Named entity recognition models work by searching for specific names and grouping these into pre-defined categories. Entity resolution refers to finding records – such an diagnosis, procedure or drug codes – that refer to the same entity and resolving these into one record.
Machine learning can make patterns evident but only if the data used is clean, normalized and complete. Natural language processing (NLP) is a critical part of obtaining data from specialist documents and clinical notes.
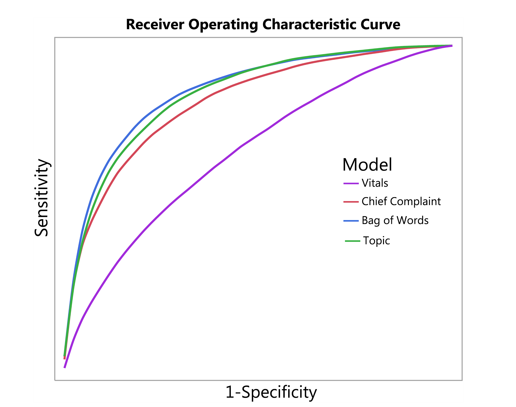
Example of an ROC (AUC) curve (from Horng et al., 2017)
NLP is therefore very important for healthcare, and has two common AI-in-healthcare use cases:
Patient risk prediction: Creating an automated trigger for sepsis clinical decision support at emergency department triage using machine learning
This study demonstrates the advantage of extracting free text data and vital sign data to identify those patients suspected of having a life-threatening infection. The study used NLP to extract data from the clinical text.
The researchers found that the AUC increased from 0.67 (without using NLP) to 0.86 when using NLP. The AUC (ROC value) is the area under the curve and is used in classification analysis to evaluate how well a model performs. Basically, the higher the AUC value (the closer the value to 1 is), the better the model’s accuracy is considered. The study thus concluded that the use of NLP on free text records was advantageous and actually improved the ability to identify and predict infections in patients in the ER, as indicated by the increased AUC value.
Patient risk prediction is important because this underlies decision-making processes. The value of predictive tests is that it enables decisions to be made regarding whether or not a particular treatment option is likely to be useful if pursued. In fact, a total of 97% of predictive rules used in an evaluation of 29 studies where NLP was used, were found to be clinically sensible (Read more…). Patient risk prediction models are valuable and may assist doctor’s prediction abilities. This was found to be the case for the study on sepsis as indicated by the increase in the AUC value. There are other cases where doctors’ prediction ability is poor. For instance, oncologists have been found to have only 20% accuracy when predicting the survival of terminally ill patients (Read more…).
Cohort building: Opportunities and challenges in leveraging electronic health record data in oncology
The increased use of digital information and electronic health records (EHRs) is bringing ‘Big Data’ to the healthcare industry. The data is easy to access and extract if it is in a structured format. This is not the case for unstructured data which are not entered in a specific coded format. This means that EHRs are limited because data elements are either absent or are in the form of free text.
A study on non-small cell lung cancer (NSCLS) demonstrated the use of structured and unstructured data. Using both types of data, 8324 patients were identified as having NSCLC. Of the 8324, only 2472 were also found in the cohort formed by structured data only. In addition, 1090 patients would also be included if only structured data was used. The 1090 patients were thought to be unlikely to match the parameters of the study. Hence, the 2472 patients were the true cohort of concern that was used for the analysis. This highlights the importance of using both structured and unstructured data in an analysis.
Cohort building (to bring together data on a group of patients to form groups or cohorts) is important because the subsequent data analysis relies on correct cohort identification being made. Cohorts will be determined based on the research question being asked, thus if the incorrect cohorts are identified then the analysis will produce spurious results. Building and identifying cohorts have been found to be important in identifying disease risk and recruiting patients for clinical trials.
Another example aside from the NSCLS study where cohort identification is important was a study on sleep disorder patients (Read more…). In this example, cohort identification and building led to a greater than 80% accuracy of terminology parsing in an NLP study on sleep disorder patients. This study showed that NLP is a very useful tool to use for unstructured data.
One needs to have a strong healthcare-specific NLP library as part of their healthcare data science toolset, such as an NLP library that implements state of the art research to use to solve these exact problems. Therefore it is apparent that NLP is a very useful and important tool for use in AI in dealing with unstructured data.
About the Author
 Luke Potgieter is a technical editor and advisor with a formal education background in the sciences. He is the author of several introductory computing courses, health guides, pre-med materials, and has published content on numerous award-winning blogs. As a Tech Advisor for John Snow Labs, Luke has found a passion for data science.
Luke Potgieter is a technical editor and advisor with a formal education background in the sciences. He is the author of several introductory computing courses, health guides, pre-med materials, and has published content on numerous award-winning blogs. As a Tech Advisor for John Snow Labs, Luke has found a passion for data science.
Sign up for the free insideBIGDATA newsletter.



sir how to identify the sensitive information in medical document in python