 In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Twin-GAN — Unpaired Cross-Domain Image Translation with Weight-Sharing GANs
This paper presents a framework for translating unlabeled images from one domain into analog images in another domain. It employs a progressively growing skip-connected encoder-generator structure and train it with a GAN loss for realistic output, a cycle consistency loss for maintaining same-domain translation identity, and a semantic consistency loss that encourages the network to keep the input semantic features in the output. The author from Google applies the framework on the task of translating face images, and show that it is capable of learning semantic mappings for face images with no supervised one-to-one image mapping.

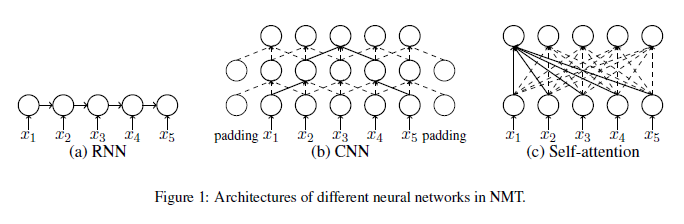
Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures
Recently, non-recurrent architectures (convolutional, self-attentional) have outperformed RNNs in neural machine translation. CNNs and self-attentional networks can connect distant words via shorter network paths than RNNs, and it has been speculated that this improves their ability to model long-range dependencies. However, this theoretical argument has not been tested empirically, nor have alternative explanations for their strong performance been explored in-depth. This paper hypothesizes that the strong performance of CNNs and self-attentional networks could also be due to their ability to extract semantic features from the source text, and the authors evaluate RNNs, CNNs and self-attention networks on two tasks: subject-verb agreement (where capturing long-range dependencies is required) and word sense disambiguation (where semantic feature extraction is required). Experimental results show that: 1) self-attentional networks and CNNs do not outperform RNNs in modeling subject-verb agreement over long distances; 2) self-attentional networks perform distinctly better than RNNs and CNNs on word sense disambiguation.
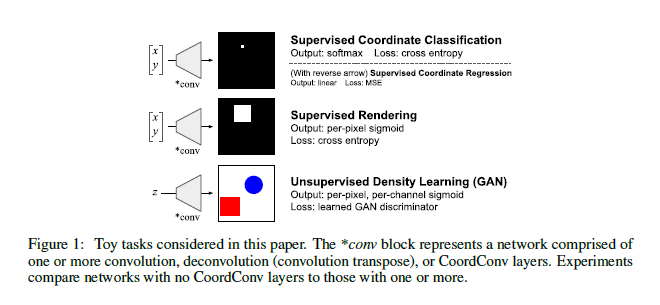
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
 Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. This paper shows a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, the authors from Uber show that they fail spectacularly. The paper demonstrates and carefully analyzes the failure first on a toy problem, at which point a simple fix becomes obvious. This solution is called CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels.
Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. This paper shows a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, the authors from Uber show that they fail spectacularly. The paper demonstrates and carefully analyzes the failure first on a toy problem, at which point a simple fix becomes obvious. This solution is called CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels.
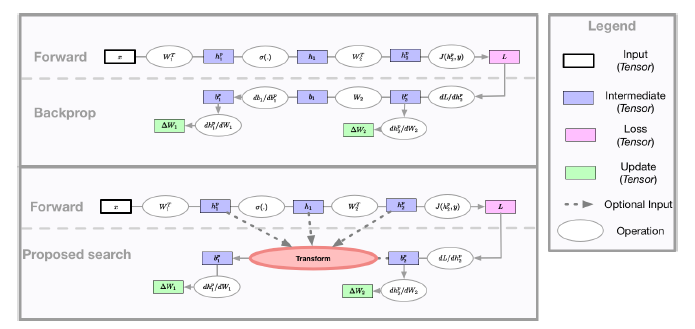
The back-propagation algorithm is the cornerstone of deep learning. Despite its importance, few variations of the algorithm have been attempted. This work presents an approach to discover new variations of the back-propagation equation. The authors from Google use a domain specific lan- guage to describe update equations as a list of primitive functions. An evolution-based method is used to discover new propagation rules that maximize the generalization per- formance after a few epochs of training. The research finds several update equations that can train faster with short training times than standard back-propagation, and perform similar as standard back-propagation at convergence.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind