 In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
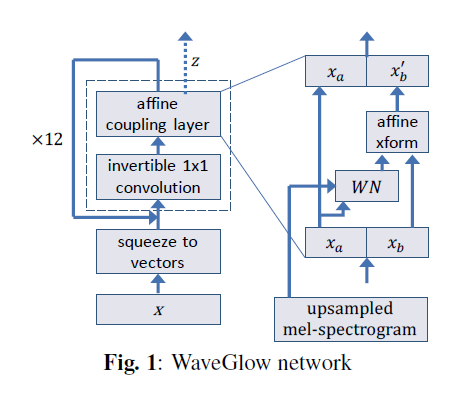
WaveGlow: A Flow-based Generative Network for Speech Synthesis
 This paper proposes WaveGlow: a flow-based network capable of generating high quality speech from mel-spectrograms. WaveGlow combines insights from Glow and WaveNet in order to provide fast, efficient and high-quality audio synthesis, without the need for auto-regression. WaveGlow is implemented using only a single network, trained using only a single cost function: maximizing the likelihood of the training data, which makes the training procedure simple and stable. The authors, all from NVIDIA, provide a PyTorch implementation that produces audio samples at a rate of more than 500 kHz on an NVIDIA V100 GPU. Mean Opinion Scores show that it delivers audio quality as good as the best publicly available WaveNet implementation. WaveGlow code is available on GitHub.
This paper proposes WaveGlow: a flow-based network capable of generating high quality speech from mel-spectrograms. WaveGlow combines insights from Glow and WaveNet in order to provide fast, efficient and high-quality audio synthesis, without the need for auto-regression. WaveGlow is implemented using only a single network, trained using only a single cost function: maximizing the likelihood of the training data, which makes the training procedure simple and stable. The authors, all from NVIDIA, provide a PyTorch implementation that produces audio samples at a rate of more than 500 kHz on an NVIDIA V100 GPU. Mean Opinion Scores show that it delivers audio quality as good as the best publicly available WaveNet implementation. WaveGlow code is available on GitHub.
 Reversible Recurrent Neural Networks
Reversible Recurrent Neural Networks
Recurrent neural networks (RNNs) provide state-of-the-art performance in processing sequential data but are memory intensive to train, limiting the flexibility of RNN models which can be trained. Reversible RNNs—RNNs for which the hidden-to-hidden transition can be reversed—offer a path to reduce the memory requirements of training, as hidden states need not be stored and instead can be recomputed during backpropagation. This paper firsts show that perfectly reversible RNNs, which require no storage of the hidden activations, are fundamentally limited because they cannot forget information from their hidden state. The paper then provides a scheme for storing a small number of bits in order to allow perfect reversal with forgetting. The author’s method achieves comparable performance to traditional models while reducing the activation memory cost by a factor of 10–15.
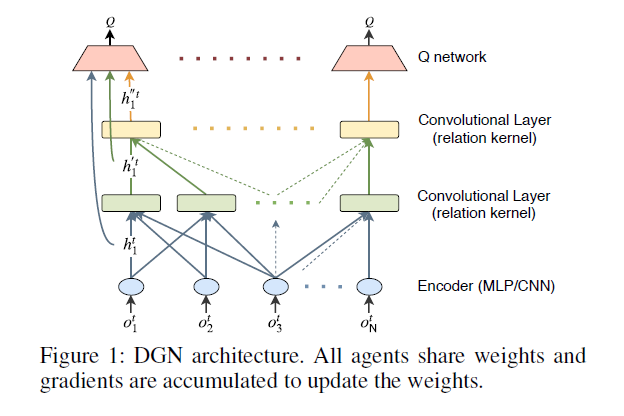
Graph Convolutional Reinforcement Learning for Multi-Agent Cooperation
Learning to cooperate is crucially important in multi-agent reinforcement learning. The key is to take the influence of other agents into consideration when performing distributed decision making. However, multi-agent environment is highly dynamic, which makes it hard to learn abstract representations of influences between agents by only low-order features that existing methods exploit. This paper proposes a graph convolutional model for multi-agent cooperation. The graph convolution architecture adapts to the dynamics of the underlying graph of the multi-agent environment, where the influence among agents is captured by their abstract relation representations. The code for this paper is available on GitHub.
On the Margin Theory of Feedforward Neural Networks
Past works have shown that, somewhat surprisingly, over-parametrization can help generalization in neural networks. Towards explaining this phenomenon, this paper adopts a margin-based perspective. This paper establishes: 1) for multi-layer feedforward relu networks, the global minimizer of a weakly-regularized cross-entropy loss has the maximum normalized margin among all networks, 2) as a result, increasing the over-parametrization improves the normalized margin and generalization error bounds for two-layer networks. In particular, an infinite-size neural network enjoys the best generalization guarantees.

SFV: Reinforcement Learning of Physical Skills from Videos
Data-driven character animation based on motion capture can produce highly naturalistic behaviors and, when combined with physics simulation, can provide for natural procedural responses to physical perturbations, environmental changes, and morphological discrepancies. Motion capture remains the most popular source of motion data, but collecting mocap data typically requires heavily instrumented environments and actors. This paper proposes a method that enables physically simulated characters to learn skills from videos (SFV). The approach, based on deep pose estimation and deep reinforcement learning, allows data-driven animation to leverage the abundance of publicly available video clips from the web, such as those from YouTube.

Exascale Deep Learning for Climate Analytics
In this paper, the authors extract pixel-level masks of extreme weather patterns using variants of Tiramisu and DeepLabv3+ neural networks. They describe improvements to the software frameworks, input pipeline, and the network training algorithms necessary to efficiently scale deep learning on the Piz Daint and Summit systems.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind