
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Democratizing Production-Scale Distributed Deep Learning
The interest and demand for training deep neural networks have been experiencing rapid growth, spanning a wide range of applications in both academia and industry. However, training them distributed and at scale remains difficult due to the complex ecosystem of tools and hardware involved. One consequence is that the responsibility of orchestrating these complex components is often left to one-off scripts and glue code customized for specific problems. To address these restrictions, this paper introduces Alchemist – an internal service built at Apple from the ground up for easy, fast, and scalable distributed training.
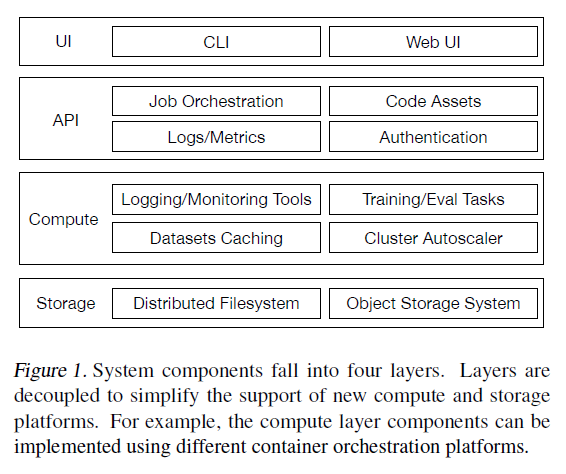
 This paper discusses deep reinforcement learning in an overview style with six core elements, six important mechanisms, and twelve applications, focusing on contemporary work, and in historical contexts. The author starts with background of artificial intelligence, machine learning, deep learning, and reinforcement learning (RL), with resources. Next, the discuss turns to RL core elements, including value function, policy, reward, model, exploration vs. exploitation, and representation. Then important mechanisms for RL, including attention and memory, unsupervised learning, hierarchical RL, multi-agent RL, relational RL, and learning to learn.
This paper discusses deep reinforcement learning in an overview style with six core elements, six important mechanisms, and twelve applications, focusing on contemporary work, and in historical contexts. The author starts with background of artificial intelligence, machine learning, deep learning, and reinforcement learning (RL), with resources. Next, the discuss turns to RL core elements, including value function, policy, reward, model, exploration vs. exploitation, and representation. Then important mechanisms for RL, including attention and memory, unsupervised learning, hierarchical RL, multi-agent RL, relational RL, and learning to learn.
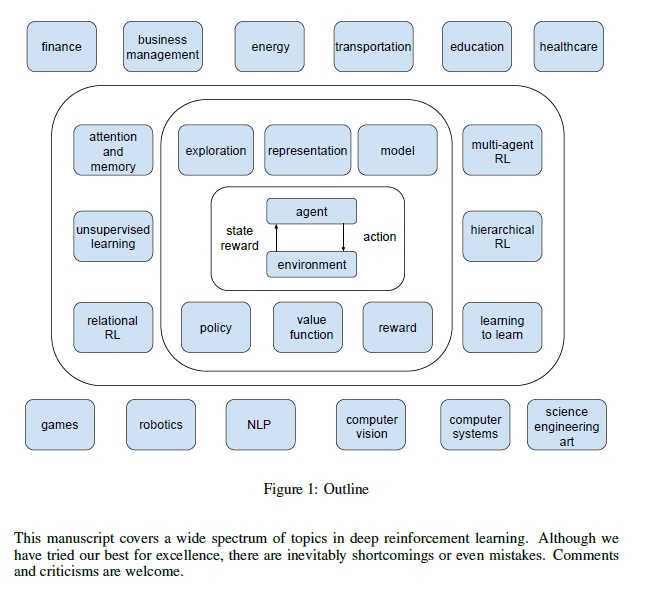
Visualizing the Loss Landscape of Neural Nets
Neural network training relies on our ability to find “good” minimizers of highly non-convex loss functions. It is well-known that certain network architecture designs (e.g., skip connections) produce loss functions that train easier, and well-chosen training parameters (batch size, learning rate, optimizer) produce minimizers that generalize better. However, the reasons for these differences, and their effects on the underlying loss landscape, are not well understood. This paper explores the structure of neural loss functions, and the effect of loss landscapes on generalization, using a range of visualization methods.
code2vec: Learning Distributed Representations of Code
This paper presents a neural model for representing snippets of code as continuous distributed vectors (“code embeddings”). The main idea is to represent a code snippet as a single fixed-length code vector, which can be used to predict semantic properties of the snippet. This is performed by decomposing code to a collection of paths in its abstract syntax tree, and learning the atomic representation of each path simultaneously with learning how to aggregate a set of them. The authors demonstrate the effectiveness of our approach by using it to predict a method’s name from the vector representation of its body. The authors evaluate their approach by training a model on a data set of 14M methods. The paper shows that code vectors trained on this data set can predict method names from files that were completely unobserved during training. A GitHub repo for the paper can be found HERE.

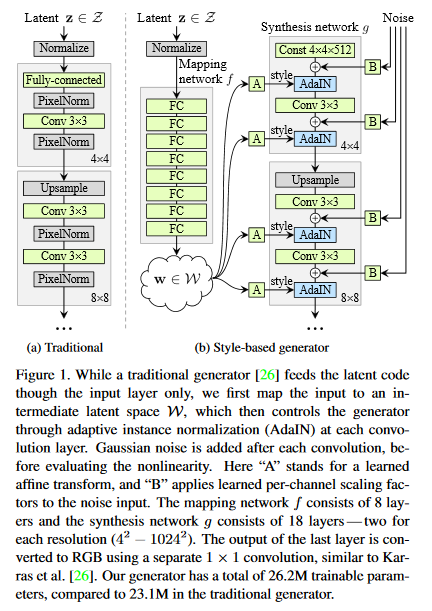
A Style-Based Generator Architecture for Generative Adversarial Networks
This paper from NVIDIA researchers proposes an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation.
Sign up for the free insideBIGDATA newsletter.



Excelent article! This tech will change reality itself