You have the data. How do you make sense of it?
The Internet of Things (IoT) is no longer a fancy marketing term thrown in to close a critical deal – it’s all around us. In the digital age, everyone has smart, connected machines, which are happily and continuously reeling in their data – by the truckload. In fact, according to Forbes, the global IoT market is estimated to hit US$457 billion by 2020.
The question is, what do you do with all this data? Granted, every self-respecting, agile and competitive organization in today’s day and age has already realized the importance of gathering their data. They also know that they need to analyze said data to identify abnormalities, or what we call anomalies. Which is great. But how do you go about selecting the anomaly detection technique that works best for you? Let’s first take a step back and run through each of them to get a better understanding.
It’s not what you do, but how you do it
There are broadly three techniques adopted today for detecting anomalies – supervised, semi-supervised and unsupervised.
Supervised anomaly detection:This technique hinges on the prior labeling of data as “normal” or “anomalous”. The algorithm is trained using existing current or historical data, and is then deployed to predict outcomes on new data. Though this technique finds application in fraud detection in the banking/ fintech space, it can only be applied to predict known anomalies such as previously identified fraud/ misappropriations.
Semi-supervised anomaly detection:This technique is inherently tricky. The algorithm in this case only has a set of “normal” data points for reference – any data points that are outside this reference range are classified as anomalous. The downside of this technique is that it has the tendency to flag “false positives”, or anomalies that aren’t actually anomalies. Thus, it ends up being counter-productive – in that you could end up wasting considerable time, effort and resources.
Unsupervised anomaly detection (also called automated anomaly detection): In this technique, which is entirely automated, anomalies can be identified from unlabelled data by assuming a majority of the data points to be normal. Deviating instances that are statistically significant (classified as a “2* standard deviation” or “3* standard deviation”) on either side of the established normal are regarded as anomalies. The more powerful the algorithm, the higher the accuracy of the anomaly detection. This method may be used for detecting anomalies in time series data, and also to predict and flag future anomalies.
What you need is an algorithm powerful enough to analyze raw data
While each of the above techniques obviously has advantages as well as disadvantages, it’s only unsupervised anomaly detection that is feasible in the case of raw, unlabelled time series data – which is what you get from just about any online asset in a modern-day digitised company. Anomaly detection in time series data has a variety of applications across industries – from identifying abnormalities in ECG data to finding glitches in aircraft sensor data.
What’s more, you normally only know 20% of the anomalies that you can expect. The remaining 80% are new/ unpredictable. Unsupervised anomaly detection is the only technique that’s capable of identifying these hidden signals or anomalies – and flagging them early enough to fix them before they occur.
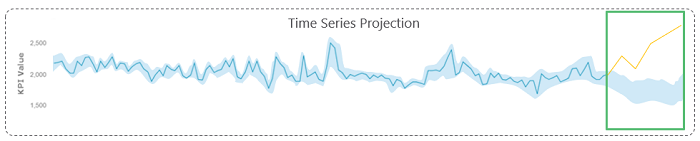
Let’s take a closer look at how this happens.
Anomaly detection for time series data with deep learning – identifying the “unknown unknowns”
One of the most effective ways of detecting anomalies in time series data is via deep learning. This technique involves the following steps:
- Apply deep learning architecture to time series data: First, recurrent neural networks are applied to a series of input and output sets to establish the normal and accordingly predict the time series. This process is repeated until the predictions achieve a high level of accuracy. However, the models need to be updated regularly to accommodate changing trends and ensure accuracy and relevance. Long short-term memory (LSTM) neural networks are great at remembering seasonal and other trends.
- Predict the next values from the latest available explanatory variables: Once the model has been trained, it can predict the next series based on real-time explanatory variables.
- Predict the upper and lower limits based on the standard deviation calculated for the latest predicted values: Once the values are predicted, the algorithm creates upper and lower limits at a specified confidence level. For instance, a 95% confidence level means that limits need to be at a “1.96 * standard deviation with respect to the mean on both sides” for a normal distribution.
- Identify and score anomalies: Whenever an actual perceived value falls beyond the predicted normal range, anomalies are marked – and scored based on their magnitude of deviation. A simple scoring methodology could be:
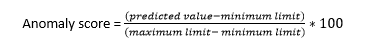
Anomaly scores help users filter out anomalies that are less than a set threshold value (say 40), and also to prioritise them so that they can focus on more serious anomalies first and then move on to less serious ones. In case of critical metrics that involve huge expenses, the threshold value can be set to zero so that the tiniest of anomalies with the lowest of scores can be scrutinised for relevant action.
Anomaly detection in industrial data is by no means a simple process given the scale at which it needs to happen, and also the highly dynamic nature of business in today’s world. However, it’s still imperative to get it right, as no digital business can hope to stay relevant and competitive in an increasingly tough economy without the power of meaningful data analytics to back its growth.
About the Author
 Pratap Dangeti is the Principal Data Scientist at Subex. He has close to 9 years of experience in the field of analytics across the domains like banking, IT, credit & risk, manufacturing, hi-tech, utilities and telecom. His technical expertise includes Statistical Modelling, Machine Learning, Big Data, Deep Learning, NLP, and artificial intelligence. As a hobbyist, he has written 2 books in the field of Machine Learning & NLP.
Pratap Dangeti is the Principal Data Scientist at Subex. He has close to 9 years of experience in the field of analytics across the domains like banking, IT, credit & risk, manufacturing, hi-tech, utilities and telecom. His technical expertise includes Statistical Modelling, Machine Learning, Big Data, Deep Learning, NLP, and artificial intelligence. As a hobbyist, he has written 2 books in the field of Machine Learning & NLP.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind