It’s no secret that machine learning success is derived from the availability of labeled data in the form of a training set and test set that are used by the learning algorithm. The separation of the data into a training portion and a test portion is the way the algorithm learns. You split up the data containing known response variable values into two pieces. The training set is used to train the algorithm, and then you use the trained model on the test set to predict the response variable values that are already known. The final step is to compare the predicted responses against the actual (observed) responses to see how close they are. The difference is the test error metric. Depending on the test error, you can go back to refine the model and repeat the process until you’re satisfied with the accuracy.
Labels are the values of the response variables (what’s being predicted) that are used by the algorithm along with the feature variables (predictors). One consistent problem faced by data scientists is how to obtain labels for a given data set for use with machine learning. In this article we’ll see a variety of techniques used down in the trenches. To start things off, here is a nice summary infographic that outlines a number of data set labeling methods:
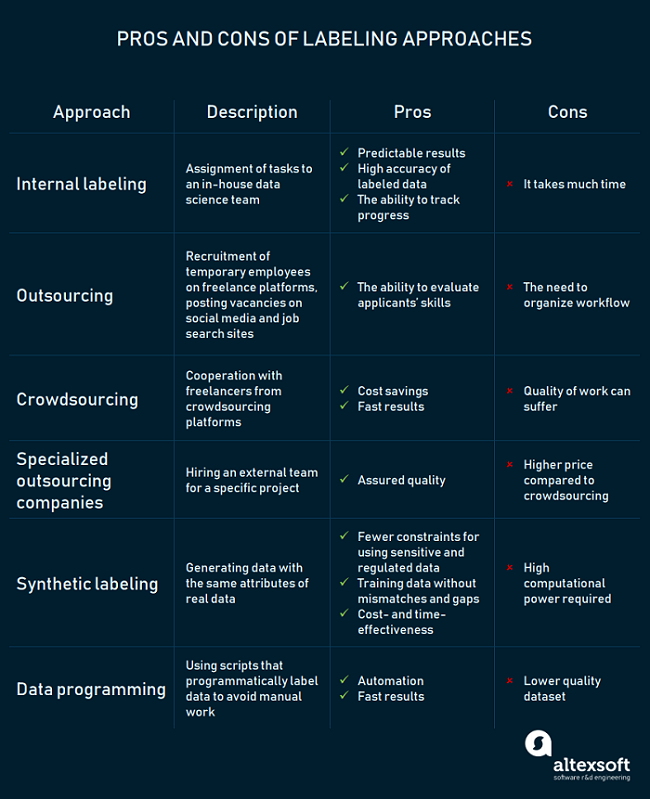
Source: https://www.altexsoft.com/blog/datascience/how-to-organize-data-labeling-for-machine-learning-approaches-and-tools/
Inherent Labels
If you’re lucky, the labels are provided and inherent in the data set you’re working with. The ubiquitous multivariate iris data set used as a demo for classification learning methods is a good example – it has 4 predictors, along with a response variable, with all values included. You can use the data as-is along with a classification algorithm to predict “species.” In the real world, you might have data sets, say for the real estate industry that contains a home sale prices, along with a number of predictor variables (e.g. square footage, year built, number of bedrooms, etc.). Another example is a customer profile data set for a SaaS company that includes a response variable indicating whether the customer churned or not, along with predictor variables defining the characteristics of the customer.
Or if you’re competing in a Kaggle challenge, you’re given a highly curated labeled data set to work with. Here, you get a number of predictive features, along with the response variable that goes along with them. All that is asked of the data scientists participating in the challenge is that they build a model using this data set.
The common theme here is that you don’t have to do any work to obtain the labels that are needed by your machine learning algorithm. Unfortunately, having labeled data sets is not always the case.
Domain Experts
One common method for filling in missing labels for a data set is to use domain experts for their knowledge of the problem being solved. This is potentially a very laborious task, and if you desire a sizeable amount of labeled data to train your algorithm, this method could take a very long time. But if your data set is not labeled, using a domain expert to fill in the blanks is usually the most effective and will lead to the best labels and as a result, the highest predictive accuracy.
Labelers must be extremely focused because each error or inaccuracy will negatively affect a data set’s quality and the overall performance of a predictive model.
Labeling Services
The average human being is typically a very good engine for classifying many classes of data. The infamous Zooniverse organization (for “People Powered Research”) has been using human volunteers for years to classify astronomical images of galaxies (spiral, elliptical, irregular) with their Galazy Zoo project. More recently, human classifiers can work on projects in many different subject domains: climate, biology, arts, history, language, medicine, and others.
Amazon has its Mechanical Turk service where you can ask piecework earners to classify your data sets for pennies per classification. Another similar service is clickworker. The caveat is such labelers are going to give you some noisy data and you need to figure out how to come up with reliable data to train your model based on all of these conflicting/disagreeing judgments that come from labelers. Each example from the data set is labeled multiple times by different labelers. You can simply choose the label that was chosen most frequently by all the labelers that looked at it. For example, if there were 10 labelers and six people picked one label and four people picked something else, you just use the statistical mode, the label that six people chose. The accuracy according to that metric is often acceptable.
There are also data set labeling services that have been around a while, such as Figure Eight and Alegion.
The start-up Labelbox offers a service to create and manage training data. Labelbox integrates with your ML pipeline by hosting or connecting to your training data (labeled and unlabeled). You can label data with internal and external teams simultaneously, review annotations collaboratively, keep track of activity and progress, catch bad labels in real time using a consensus system to automatically identify and correct inconsistent labels. You can even set up review workflows to correct labels and ensure accuracy of the training data.
Semi-supervised Learning
Another machine learning method specifically addresses the need for making predictions with unlabeled data sets. Semi-supervised learning (SSL) dates back to the 60’s but recently has gained increased importance due to so-called “big data” coming from diverse sources such as all corners of the internet, social media, text classification, and many others. These immense data sets are typically unlabeled.
The primary goal of SSL is to jointly classify these data in the presence of a small training sample. Specifically, a lot of unlabeled data together with a small quantity of labeled data is combined to classify each unlabeled examples. Several methods have been proposed to achieve this goal: self-training, co-training, transductive support vector machines, and graph-methods are a few of such methods.
 Contributed by Daniel D. Gutierrez, Managing Editor and Resident Data Scientist for insideBIGDATA. In addition to being a tech journalist, Daniel also is a consultant in data scientist, author, educator and sits on a number of advisory boards for various start-up companies.
Contributed by Daniel D. Gutierrez, Managing Editor and Resident Data Scientist for insideBIGDATA. In addition to being a tech journalist, Daniel also is a consultant in data scientist, author, educator and sits on a number of advisory boards for various start-up companies.
Sign up for the free insideBIGDATA newsletter.



I would like to know how I can cite your publication (for some scientific articles) or know if it has an article referring to this which can be quoted directly (other than page), could you tell me how?…
thanks, greetings