HPE highlights recent research that explores the performance of GPUs in scale-out and scale-up scenarios for deep learning training.

Comparisons can be made between the same number of GPUs in scale-up and scale-out configurations from 2 to 16 GPUs. (Photo: Shutterstock/Pasuwan)
As companies begin to move deep learning projects from the conceptual stage into a production environment to impact the business, it is reasonable to assume that models will become more complex, the quantity of data involved will grow even further, and that GPU clusters will begin to scale. Companies are using distributed GPU clusters to decrease training time with the Horovod training framework, which was developed by Uber.
The HPE white paper, “Accelerate performance for production AI,” examines the impact of storage on distributed scale-out and scale-up scenarios with common Deep Learning (DL) benchmarks. While the paper shows the storage throughput and bandwidth requirements for both scale-up and scale-out training, it also reveals performance for the same number of GPUs in a scale-up scenario, i.e. GPUs within a single server, versus a scale-out scenario, i.e. GPUs distributed across servers.
The benchmarks were run on 4 HPE Apollo 6500 Gen10 systems with 8 NVIDIA Tesla V100 SXM2 16GB GPUs. A Mellanox 100 Gb/s EDR InfiniBand network connected the servers themselves, as well as to WekaIO Matrix storage cluster of 8 HPE ProLiant DL360 Gen10 Servers with a total of 32 NVMe SSDs. Further information on the benchmark configuration can be found in the white paper.
A parallel data approach was used to distribute the training for a model across the servers. Each server completes its share of the training, and the results are shared between the servers to calculate an overall update to the model.
Consider the real-data results for ResNet50 with one to thirty two GPUs in permutations of 1, 2, or 4 nodes:
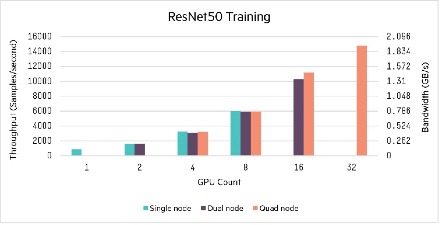
Comparisons can be made between the same number of GPUs in scale-up and scale-out configurations from 2 to 16 GPUs. The largest difference is with 16 GPUs, with an 8.5% difference in performance between 2 servers with 8 GPUs versus 4 servers with 4 GPUs each. The next greatest difference is one of 4.9% within the 4 GPU scenario between a single node with 4 GPUs and 2 nodes with 2 GPUs each. Overall, performance is very linear between scale-up and scale-out configurations for the same number of GPUs. Performance as the number of GPUs increase is fairly linear up to 8 GPUs, but then falls to around a 70% increase to 16 GPUs, still a meaningful improvement.
Workloads can be scheduled and strategies developed to minimize individual job times, or to maximize the overall number of jobs to be completed within a given time period.
These results imply that workloads can be managed effectively through scale-out allocation of GPUs. This provides flexibility in server allocation to match workload requirements. While further testing is required with larger numbers of GPUs, these benchmarks indicate that the increased performance from adding GPUs is fairly predictable, which means time to solution can also be managed to a reasonable extent. In other words, resources and time can be managed.
Workloads can be scheduled and strategies developed to minimize individual job times, or to maximize the overall number of jobs to be completed within a given time period. For instance, many different models could be tested initially with small data sets, then the system could be configured to aggregate resources to minimize throughput time for a particular model with larger production data sets. Or if there is a time deadline by which training must be completed, or if it simply takes too long to complete training, distributing the workload across many GPUs can be used to reduce training time. This flexibility allows GPU resources to be maximally utilized and provides high ROI since time to results can be minimized.
Read about the benchmarks and their results in the white paper: Accelerate performance for production AI (gated asset)
Learn more about NVIDIA Volta, the Tensor Core GPU architecture designed to bring AI to every industry: NVIDIA Volta
Learn more about HPC and AI storage here.



Speak Your Mind