
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Exact Gaussian Processes on a Million Data Points
Gaussian processes (GPs) are flexible models with state-of-the-art performance on many impactful applications. However, computational constraints with standard inference procedures have limited exact GPs to problems with fewer than about ten thousand training points, necessitating approximations for larger datasets. This paper develops a scalable approach for exact GPs that leverages multi-GPU parallelization and methods like linear conjugate gradients, accessing the kernel matrix only through matrix multiplication.

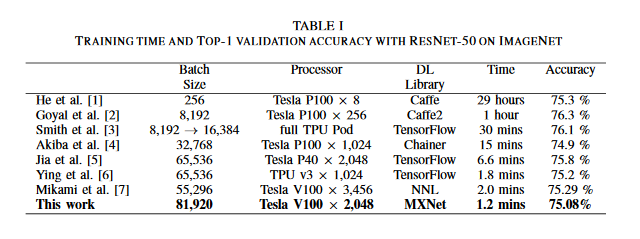
Yet Another Accelerated SGD: ResNet-50 Training on ImageNet in 74.7 seconds
There has been a strong demand for algorithms that can execute machine learning as faster as possible and the speed of deep learning has accelerated by 30 times only in the past two years. Distributed deep learning using the large mini-batch is a key technology to address the demand and is a great challenge as it is difficult to achieve high scalability on large clusters without compromising accuracy. This paper introduces optimization methods applied to this challenge. The authors achieved the training time of 74.7 seconds using 2,048 GPUs on ABCI cluster applying these methods. The training throughput is over 1.73 million images/sec and the top-1 validation accuracy is 75.08%.
Multimodal Emotion Classification

Most NLP and Computer Vision tasks are limited to scarcity of labelled data. In social media emotion classification and other related tasks, hashtags have been used as indicators to label data. With the rapid increase in emoji usage of social media, emojis are used as an additional feature for major social NLP tasks. However, this is less explored in case of multimedia posts on social media where posts are composed of both image and text. At the same time, w.e have seen a surge in the interest to incorporate domain knowledge to improve machine understanding of text. In this paper, we investigate whether domain knowledge for emoji can improve the accuracy of emotion classification task.

Generative Adversarial Networks: recent developments
In traditional generative modeling, good data representation is very often a base for a good machine learning model. It can be linked to good representations encoding more explanatory factors that are hidden in the original data. With the invention of Generative Adversarial Networks (GANs), a subclass of generative models that are able to learn representations in an unsupervised and semi-supervised fashion, we are now able to adversarially learn good mappings from a simple prior distribution to a target data distribution. This paper presents an overview of recent developments in GANs with a focus on learning latent space representations.
Multivariate time series is a very active topic in the research community and many machine learning tasks are being used in order to extract information from this type of data. However, in real-world problems data has missing values, which may difficult the application of machine learning techniques to extract information. This paper focuses on the task of imputation of time series. Many imputation methods for time series are based on regression methods. Unfortunately, these methods perform poorly when the variables are categorical. To address this case, the authors propose a new imputation method based on Expectation Maximization over dynamic Bayesian networks.

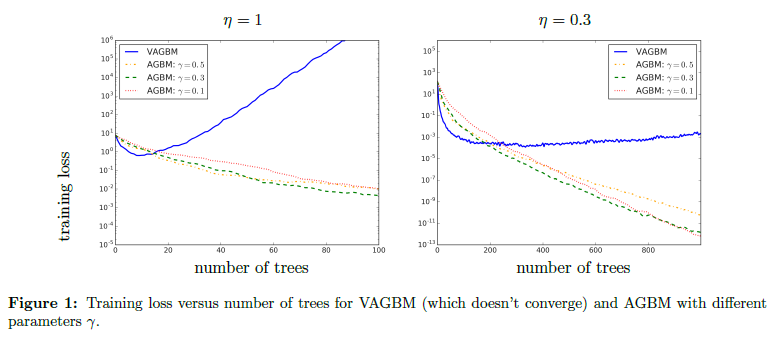
Accelerating Gradient Boosting Machine
Gradient Boosting Machine (GBM) is an extremely powerful supervised learning algorithm that is widely used in practice. GBM routinely features as a leading algorithm in machine learning competitions such as Kaggle and the KDDCup. This work proposes Accelerated Gradient Boosting Machine (AGBM) by incorporating Nesterov’s acceleration techniques into the design of GBM.
Solving the Black Box Problem: A General-Purpose Recipe for Explainable Artificial Intelligence
Many of the computing systems developed using machine learning are opaque: it is difficult to explain why they do what they do, or how they work. The Explainable AI research program aims to develop analytic techniques for rendering such systems transparent, but lacks a general understanding of what it actually takes to do so. The aim of this paper is to provide a general-purpose recipe for Explainable AI: A series of steps that should be taken to render an opaque computing system transparent.
Accelerating Minibatch Stochastic Gradient Descent using Typicality Sampling
Machine learning, especially deep neural networks, has been rapidly developed in fields including computer vision, speech recognition and reinforcement learning. Although Mini-batch SGD is one of the most popular stochastic optimization methods in training deep networks, it shows a slow convergence rate due to the large noise in gradient approximation. In this paper, we attempt to remedy this problem by building more efficient batch selection method based on typicality sampling, which reduces the error of gradient estimation in conventional Minibatch SGD.
Predicting Research Trends From Arxiv
Researchers perform trend detection on two data sets of Arxiv papers, derived from its machine learning (cs.LG) and natural language processing (cs.CL) categories. The approach is bottom-up: first rank papers by their normalized citation counts, then group top-ranked papers into different categories based on the tasks that they pursue and the methods they use. Then analyze these resulting topics. The paper describes that the dominating paradigm in cs.CL revolves around natural language generation problems and those in cs.LG revolve around reinforcement learning and adversarial principles. By extrapolation, it is predicted that these topics will remain lead problems/approaches in their fields in the short- and mid-term.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind