
In this special guest feature, Tobi Knaup, Co-founder and CTO of Mesosphere, believes that most enterprises will need to build and operate production AI systems in order to stay competitive with next-generation AI-driven products. Organizations should hire DataOps engineers to build, operate, and optimize these systems, and evangelize best practices among their data scientists. Prior to Mesosphere, Tobi managed operations and engineering at Airbnb during the company’s explosive growth years—during which he re-architected the site onto a modern service-oriented architecture, and led the SRE, search and trust & safety teams. After starting Mesosphere, he led development on Marathon, a popular open-source container-orchestration engine. He received his MS from the Technische Universität München (TUM), with a concentration on human computer interaction and security. When he was 15, Knaup co-founded Knaup Multimedia to provide a one-stop shop for web design, development and hosting services for small and medium businesses.
Artificial Intelligence (AI) is at the core of the biggest technological breakthroughs of our time. Many of the products we use every day are powered by it, like web search, e-commerce, smartphones, and virtual assistants. Maybe less visible to the average consumer, AI is also the key to solving some of humanity’s biggest problems. AI in driverless cars reduces traffic deaths, while in healthcare it accelerates drug discovery, detects diseases earlier, and contributes to ending child hunger.
Many of today’s use cases for AI deploy models in an online system, for example as part of a web application, a car, a mobile app, etc. Models within these systems need to be updated frequently to improve accuracy, respond to changes in the data, and take advantage of new modeling techniques, which are being developed at an ever-increasing pace.
This poses big challenges for organizations wanting to build production AI systems. Not only do they need to hire data scientists, from an extremely competitive and limited pool of talent, but they also need to learn how to manage online AI systems in production.
Because AI as a field is relatively young, and mainstream enterprises have only recently begun to run production AI systems, few best practices and tools exist. The result is that these systems are often built and managed in an ad hoc manner, which creates numerous avoidable issues, like poor model performance, lack of reproducibility and downtime.
Many projects fail because of operational and process flaws like not versioning model and feature functions, running different code in development and production, not using an automated deployment system, lack of monitoring etc. Moreover, most of the time spent on these systems doesn’t go into writing machine learning code, but ancillary operations tasks like machine resource management or maintaining serving infrastructure, which could be automated instead.
There is hope though. It turns out that a lot of the best practices for operating production software systems can also be applied to production AI systems. Over the last half century we have developed and refined the discipline of software engineering in order to accelerate the development and deployment of applications, defining best practices and using automation to reduce errors. This includes a general shift towards DevOps practices that align developer and business objectives and dramatically reduce time-to-delivery.
We argue that many of the principles and best practices that are used for managing software in production can also be applied to managing AI pipelines. Similar to how DevOps emerged as a new discipline and role, we increasingly see organizations creating a new type of role that combines data science and systems operations skills, that we call the DataOps engineer.
What is a DataOps Engineer?
A DataOps Engineer’s mission is to make sure Data Scientists can focus on model and feature engineering without having to worry about infrastructure. To deliver on this mission, they need expertise in data science as well as production systems operations. Their work breaks down into three main tasks:
Build –DataOps engineers build automation software to operate the systems for data storage, data science notebooks, distributed training, model repository, feature repository, continuous delivery, model serving, and monitoring.
Operate –DataOps engineers ensure that production AI systems are available, scalable, and performant. Training models requires huge amounts of data and compute and is therefore expensive and time consuming. DataOps engineers are experts in learning algorithms and infrastructure, and uniquely qualified to reduce model training time, often by a factor of 10 or more.
Evangelize –DataOps engineers evangelize best practices and tools among data science teams in order to improve productivity and avoid common mistakes.
Assembling the Pieces
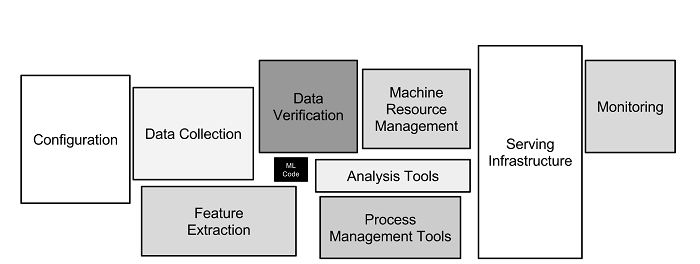
A typical production AI system consists of components from different vendors or open source projects, and organizations need to assemble a number of them in order to build an end-to-end system.
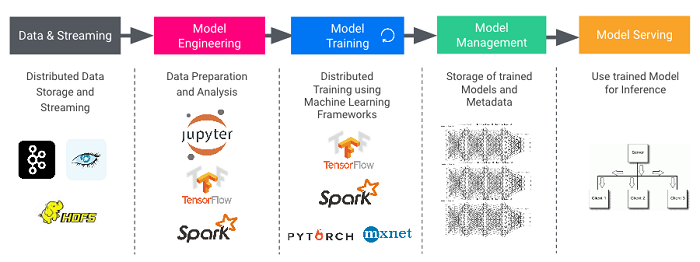
Assembling all these pieces into a reliable, enterprise-grade production system is a challenging task. More often than not there are siloed operations teams working on each piece, using their own statically partitioned set of machines. This is highly inefficient in terms of machine resource utilization and operations costs. Instead, DataOps engineers can leverage a platform like DC/OS, which allows them to choose all of the required components, such as data stores, data science notebooks, distributed training, continuous deployment, and source code management from a catalog, and run them on a shared pool of compute. This enforces operational consistency and policies across all components, ensures that best practices for security and change management are followed, and automates many operations tasks like install, upgrade, failure recovery, and elastic scaling.
Conclusion
Artificial Intelligence is set of tools that can be used to solve a wide range of problems in any industry. Most enterprises will need to build and operate production AI systems in order to stay competitive with next-generation AI-driven products. Organizations should hire DataOps engineers to build, operate, and optimize these systems, and evangelize best practices among their data scientists. DataOps engineers should use a platform like DC/OS to operate all the required components in a secure, consistent, and automated way on a single shared pool of machines.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind