
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Luck Matters: Understanding Training Dynamics of Deep ReLU Networks
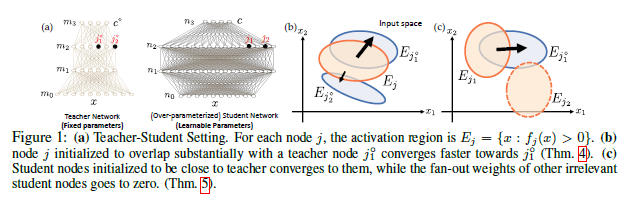
This paper analyzes the dynamics of training deep ReLU networks and their implications on generalization capability. Using a teacher-student setting, the researchers discovered a novel relationship between the gradient received by hidden student nodes and the activations of teacher nodes for deep ReLU networks. With this relationship and the assumption of small overlapping teacher node activations, it is proven that (1) student nodes whose weights are initialized to be close to teacher nodes converge to them at a faster rate, and (2) in over-parameterized regimes and 2-layer case, while a small set of lucky nodes do converge to the teacher nodes, the fan-out weights of other nodes converge to zero. This framework provides insight into multiple puzzling phenomena in deep learning like over-parameterization, implicit regularization, lottery tickets, etc.
Deep Convolutional Networks as shallow Gaussian Processes
This paper shows that the output of a (residual) convolutional neural network (CNN) with an appropriate prior over the weights and biases is a Gaussian process (GP) in the limit of infinitely many convolutional filters, extending similar results for dense networks. For a CNN, the equivalent kernel can be computed exactly and, unlike “deep kernels”, has very few parameters: only the hyperparameters of the original CNN. Further, the paper shows that this kernel has two properties that allow it to be computed efficiently; the cost of evaluating the kernel for a pair of images is similar to a single forward pass through the original CNN with only one filter per layer. The kernel equivalent to a 32-layer ResNet obtains 0.84% classification error on MNIST, a new record for GPs with a comparable number of parameters. The code for this paper can be found HERE.
Pre-training Graph Neural Networks
Many applications of machine learning in science and medicine, including molecular property and protein function prediction, can be cast as problems of predicting some properties of graphs, where having good graph representations is critical. However, two key challenges in these domains are (1) extreme scarcity of labeled data due to expensive lab experiments, and (2) needing to extrapolate to test graphs that are structurally different from those seen during training. This paper explores pre-training to address both of these challenges.
Speech2Face: Learning the Face Behind a Voice

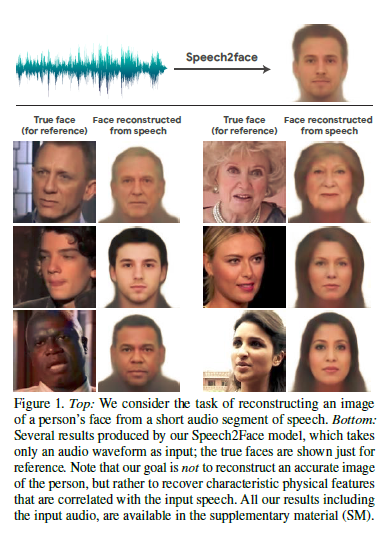
How much can we infer about a person’s looks from the way they speak? This paper studies the task of reconstructing a facial image of a person from a short audio recording of that person speaking. The researchers design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity.
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and this paper develops this approach further using a different compression technique. The reseachers achieve some surprising results on MNIST and show how to significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. The paper also introduces a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
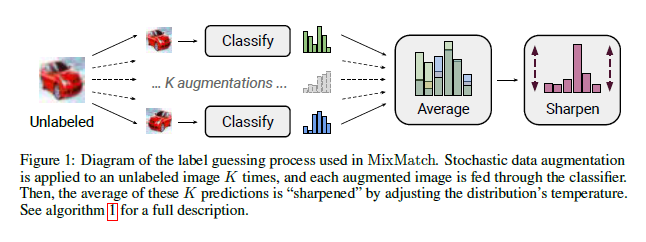
MixMatch: A Holistic Approach to Semi-Supervised Learning
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind