
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
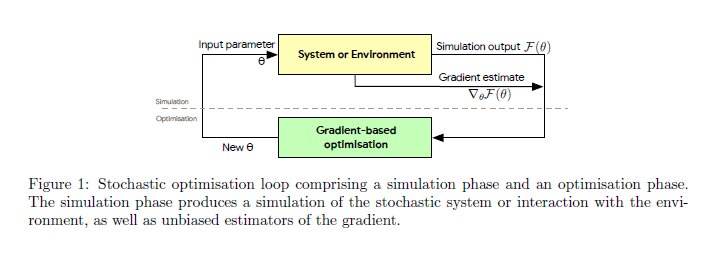
Monte Carlo Gradient Estimation in Machine Learning

This paper is a broad and accessible survey of the methods we have at our disposal for Monte Carlo gradient estimation in machine learning and across the statistical sciences: the problem of computing the gradient of an expectation of a function with respect to parameters defining the distribution that is integrated; the problem of sensitivity analysis. In machine learning research, this gradient problem lies at the core of many learning problems, in supervised, unsupervised and reinforcement learning. The Google researchers generally seek to rewrite such gradients in a form that allows for Monte Carlo estimation, allowing them to be easily and efficiently used and analyzed.
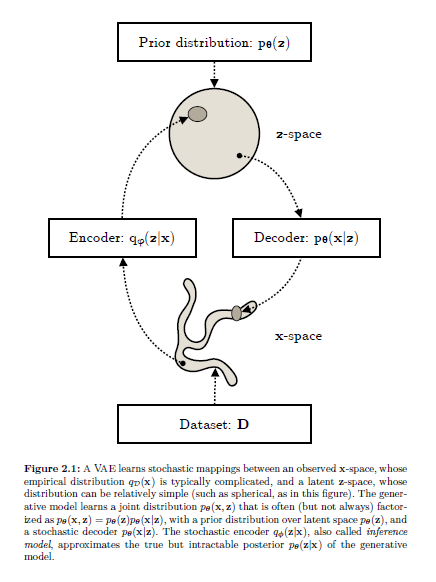
An Introduction to Variational Autoencoders
Variational autoencoders provide a principled framework for learning deep latent-variable models and corresponding inference models. This paper provides an introduction to variational autoencoders and some important extensions.
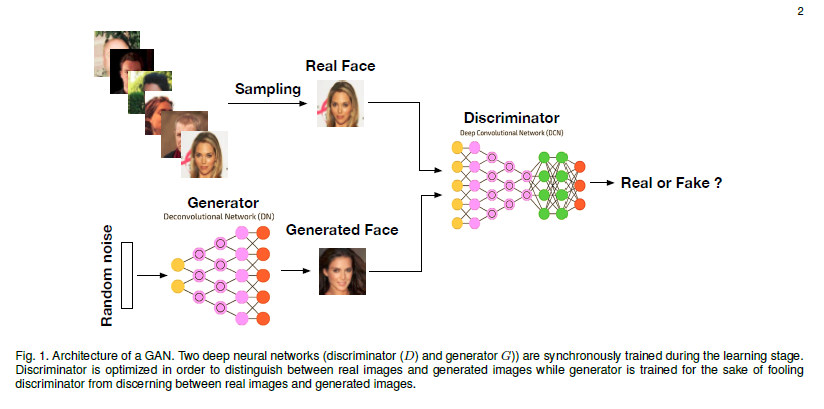
Generative Adversarial Networks: A Survey and Taxonomy
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in computer vision field, applying GANs over real-world problems still have three main challenges: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Considering numerous GAN-related research in the literature, this paper provides a study on the architecture-variants and loss-variants, which are proposed to handle these three challenges from two perspectives. The authors propose loss and architecture-variants for classifying most popular GANs, and discuss the potential improvements with focusing on these two aspects.
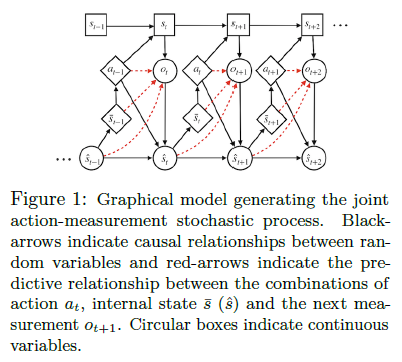
Learning Causal State Representations of Partially Observable Environments
Intelligent agents can cope with sensory-rich environments by learning task-agnostic state abstractions. This paper proposes mechanisms to approximate causal states, which optimally compress the joint history of actions and observations in partially-observable Markov decision processes. The proposed algorithm extracts causal state representations from RNNs that are trained to predict subsequent observations given the history. The authors demonstrate that these learned task-agnostic state abstractions can be used to efficiently learn policies for reinforcement learning problems with rich observation spaces.
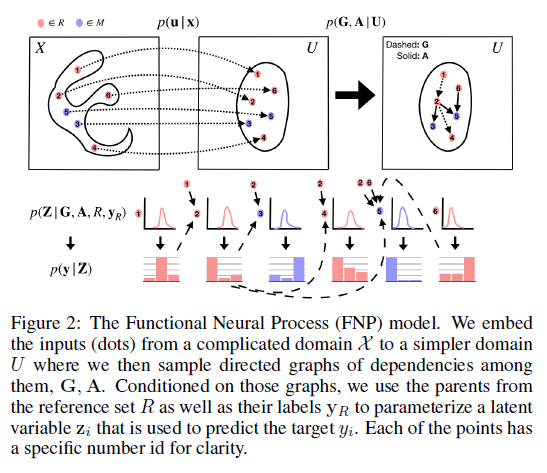
This paper presents a new family of exchangeable stochastic processes, the Functional Neural Processes (FNPs). FNPs model distributions over functions by learning a graph of dependencies on top of latent representations of the points in the given data set. In doing so, they define a Bayesian model without explicitly positing a prior distribution over latent global parameters; they instead adopt priors over the relational structure of the given data set, a task that is much simpler. The authors show how we can learn such models from data, demonstrate that they are scalable to large data sets through mini-batch optimization and describe how we can make predictions for new points via their posterior predictive distribution.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind