
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
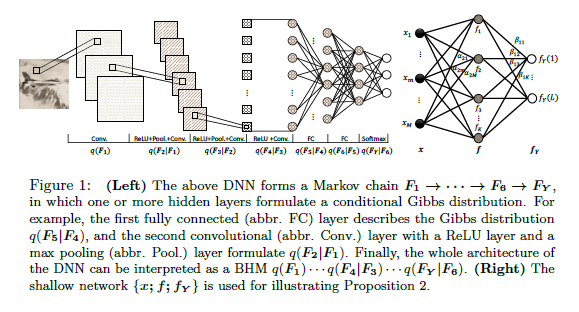
A Probabilistic Representation of Deep Learning
This paper introduces a novel probabilistic representation of deep learning, which provides an explicit explanation for the Deep Neural Networks (DNNs) in three aspects: (i) neurons define the energy of a Gibbs distribution; (ii) the hidden layers of DNNs formulate Gibbs distributions; and (iii) the whole architecture of DNNs can be interpreted as a Bayesian neural network. Based on the proposed probabilistic representation, we investigate two fundamental properties of deep learning: hierarchy and generalization.
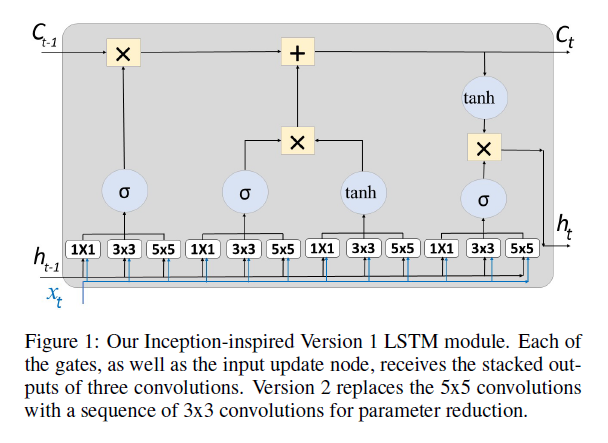
Inception-inspired LSTM for Next-frame Video Prediction
The problem of video frame prediction has received much interest due to its relevance to many computer vision applications such as autonomous vehicles or robotics. Supervised methods for video frame prediction rely on labeled data, which may not always be available. This paper provides a novel unsupervised deep-learning method called Inception-based LSTM for video frame prediction. The general idea of inception networks is to implement wider networks instead of deeper networks. This network design was shown to improve the performance of image classification.
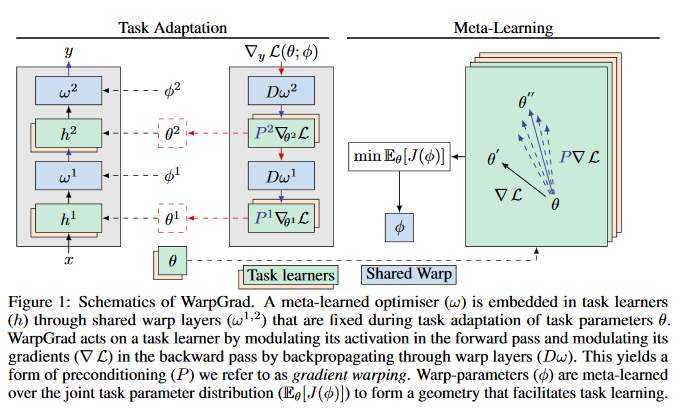
Meta-Learning with Warped Gradient Descent
A versatile and effective approach to meta-learning is to infer a gradient-based up-date rule directly from data that promotes rapid learning of new tasks from the same distribution. Current methods rely on backpropagating through the learning process, limiting their scope to few-shot learning. This paper introduces Warped Gradient Descent (WarpGrad), a family of modular optimisers that can scale to arbitrary adaptation processes. WarpGrad methods meta-learn to warp task loss surfaces across the joint task-parameter distribution to facilitate gradient descent, which is achieved by a reparametrisation of neural networks that interleaves warp layers in the architecture.
Systematic Analysis of Image Generation using GANs
Generative Adversarial Networks have been crucial in the developments made in unsupervised learning in recent times. Exemplars of image synthesis from text or other images, these networks have shown remarkable improvements over conventional methods in terms of performance. Trained on the adversarial training philosophy, these networks aim to estimate the potential distribution from the real data and then use this as input to generate the synthetic data. Based on this fundamental principle, several frameworks can be generated that are paragon implementations in several real-life applications such as art synthesis, generation of high resolution outputs and synthesis of images from human drawn sketches, to name a few. While theoretically GANs present better results and prove to be an improvement over conventional methods in many factors, the implementation of these frameworks for dedicated applications remains a challenge. This study explores and presents a taxonomy of these frameworks and their use in various image to image synthesis and text to image synthesis applications.

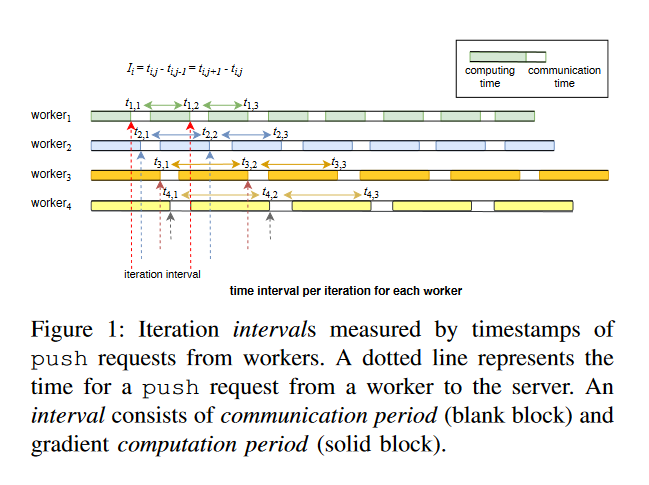
Dynamic Stale Synchronous Parallel Distributed Training for Deep Learning
Deep learning is a popular machine learning technique and has been applied to many real-world problems. However, training a deep neural network is very time-consuming, especially on big data. It has become difficult for a single machine to train a large model over large datasets. A popular solution is to distribute and parallelize the training process across multiple machines using the parameter server framework. In this paper, we present a distributed paradigm on the parameter server framework called Dynamic Stale Synchronous Parallel (DSSP) which improves the state-of-the-art Stale Synchronous Parallel (SSP) paradigm by dynamically determining the staleness threshold at the run time.
Discovering Reliable Correlations in Categorical Data
In many scientific tasks we are interested in discovering whether there exist any correlations in our data. This raises many questions, such as how to reliably and interpretably measure correlation between a multivariate set of attributes, how to do so without having to make assumptions on distribution of the data or the type of correlation, and, how to efficiently discover the top-most reliably correlated attribute sets from data. This paper answers these questions for discovery tasks in categorical data.

Smaller Models, Better Generalization
Reducing network complexity has been a major research focus in recent years with the advent of mobile technology. Convolutional Neural Networks that perform various vision tasks without memory overhaul is the need of the hour. This paper focuses on qualitative and quantitative analysis of reducing the network complexity using an upper bound on the Vapnik-Chervonenkis dimension, pruning, and quantization. The researchers observe a general trend in improvement of accuracies as the models are quantize. The paper proposes a novel loss function that helps in achieving considerable sparsity at comparable accuracies to that of dense models. The paper compares various regularizations prevalent in the literature and shows the superiority of the proposed method in achieving sparser models that generalize well.
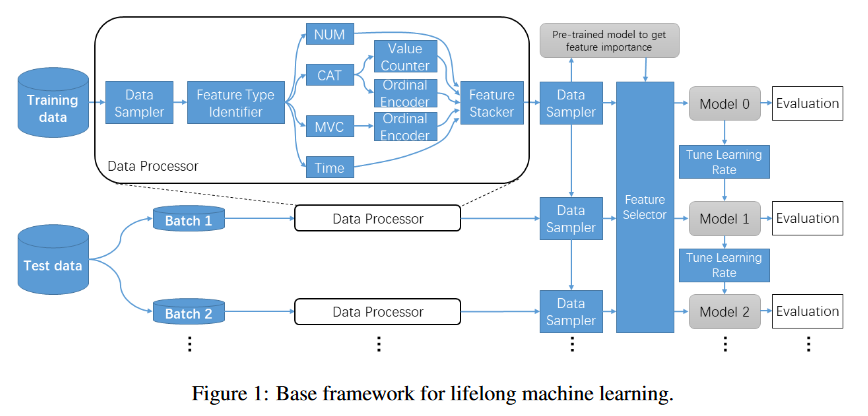
An Auto-ML Framework Based on GBDT for Lifelong Learning
Automatic Machine Learning (Auto-ML) has attracted more and more attention in recent years. This paper works to solve the problem of data drift, which means that the distribution of data will gradually change with the acquisition process, resulting in a worse performance of the auto-ML model. The researchers construct their model based on GBDT. Incremental learning and full learning are used to handle with drift problem. Experiments show that the proposed method performs well on the five data sets. This shows that the method can effectively solve the problem of data drift and has robust performance.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind