
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
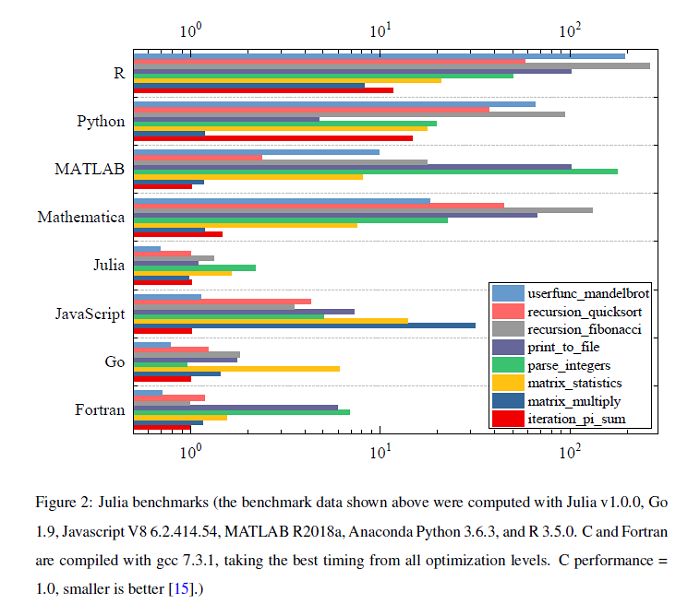
Julia Language in Machine Learning: Algorithms, Applications, and Open Issues

Machine learning is driving development across many fields in science and engineering. A simple and efficient programming language could accelerate applications of machine learning in various fields. Currently, the programming languages most commonly used to develop machine learning algorithms include Python, MATLAB, and C/C ++. However, none of these languages well balance both efficiency and simplicity. The Julia language is a fast, easy-to-use, and open-source programming language that was originally designed for high-performance computing, which can well balance the efficiency and simplicity. This paper summarizes the related research work and developments in the application of the Julia language in machine learning. It first surveys the popular machine learning algorithms that are developed in the Julia language. Then, it investigates applications of the machine learning algorithms implemented with the Julia language. Finally, it discusses the open issues and the potential future directions that arise in the use of the Julia language in machine learning.
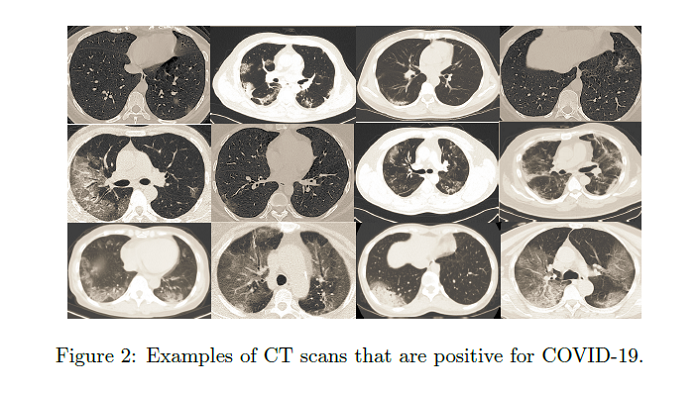
COVID-CT-Dataset: A CT Scan Dataset about COVID-19
CT scans are promising in providing accurate, fast, and cheap screening and testing of COVID-19. This paper builds a publicly available COVID-CT data set, containing 275 CT scans that are positive for COVID-19, to foster the research and development of deep learning methods which predict whether a person is affected with COVID-19 by analyzing his/her CTs. The authors train a deep convolutional neural network (CNN) on this data set and achieve an F1 of 0.85 which is a promising performance but yet to be further improved. The data and PyTorch code for this paper can be found HERE.
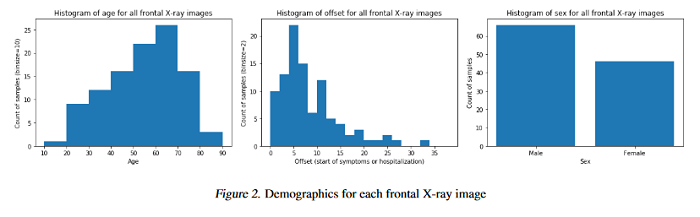
COVID-19 Image Data Collection
This paper describes the initial COVID-19 open image data collection. It was created by assembling medical images from websites and publications and currently contains 123 frontal view X-rays. The GitHub site associated with this paper can be found HERE.
Masked Face Recognition Dataset and Application
In order to effectively prevent the spread of COVID-19 virus, almost everyone wears a mask during coronavirus epidemic. This almost makes conventional facial recognition technology ineffective in many cases, such as community access control, face access control, facial attendance, facial security checks at train stations, etc. Therefore, it is very urgent to improve the recognition performance of the existing face recognition technology on the masked faces. Most current advanced face recognition approaches are designed based on deep learning, which depend on a large number of face samples. However, at present, there are no publicly available masked face recognition datasets. To this end, this paper proposes three types of masked face datasets, including Masked Face Detection Dataset (MFDD), Real-world Masked Face Recognition Dataset (RMFRD) and Simulated Masked Face Recognition Dataset (SMFRD). The GitHub site associated with this paper can be found HERE.

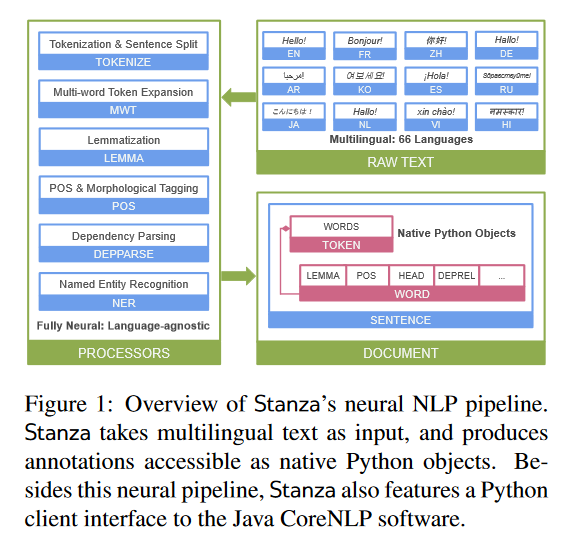
Stanza: A Python Natural Language Processing Toolkit for Many Human Languages
This paper introduces Stanza, an open-source Python natural language processing toolkit supporting 66 human languages. Compared to existing widely used toolkits, Stanza features a language-agnostic fully neural pipeline for text analysis, including tokenization, multi-word token expansion, lemmatization, part-of-speech and morphological feature tagging, dependency parsing, and named entity recognition. The Authors have trained Stanza on a total of 112 datasets, including the Universal Dependencies treebanks and other multilingual corpora, and show that the same neural architecture generalizes well and achieves competitive performance on all languages tested. Additionally, Stanza includes a native Python interface to the widely used Java Stanford CoreNLP software, which further extends its functionalities to cover other tasks such as coreference resolution and relation extraction. The PyTorch source code, documentation, and pretrained models for 66 languages are available HERE.
TensorFlow Quantum: A Software Framework for Quantum Machine Learning
This paper introduces TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data. This framework offers high-level abstractions for the design and training of both discriminative and generative quantum models under TensorFlow and supports high-performance quantum circuit simulators. The paper provides an overview of the software architecture and building blocks through several examples and review the theory of hybrid quantum-classical neural networks. The TFQ functionalities are illustrated via several basic applications including supervised learning for quantum classification, quantum control, and quantum approximate optimization. Moreover, the authors demonstrate how one can apply TFQ to tackle advanced quantum learning tasks including meta-learning, Hamiltonian learning, and sampling thermal states. The authors hope this framework provides the necessary tools for the quantum computing and machine learning research communities to explore models of both natural and artificial quantum systems, and ultimately discover new quantum algorithms which could potentially yield a quantum advantage.

What is the State of Neural Network Pruning?
Neural network pruning—the task of reducing the size of a network by removing parameters—has been the subject of a great deal of work in recent years. This paper provides a meta-analysis of the literature, including an overview of approaches to pruning and consistent findings in the literature. After aggregating results across 81 papers and pruning hundreds of models in controlled conditions, the clearest finding is that the community suffers from a lack of standardized benchmarks and metrics. This deficiency is substantial enough that it is hard to compare pruning techniques to one another or determine how much progress the field has made over the past three decades. To address this situation, the authors identify issues with current practices, suggest concrete remedies, and introduce ShrinkBench, an open-source framework to facilitate standardized evaluations of pruning methods. ShrinkBench is used to compare various pruning techniques and show that its comprehensive evaluation can prevent common pitfalls when comparing pruning methods. The PyTorch code for this paper is available HERE.

Sign up for the free insideBIGDATA newsletter.



Such a great post with valuable content