
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
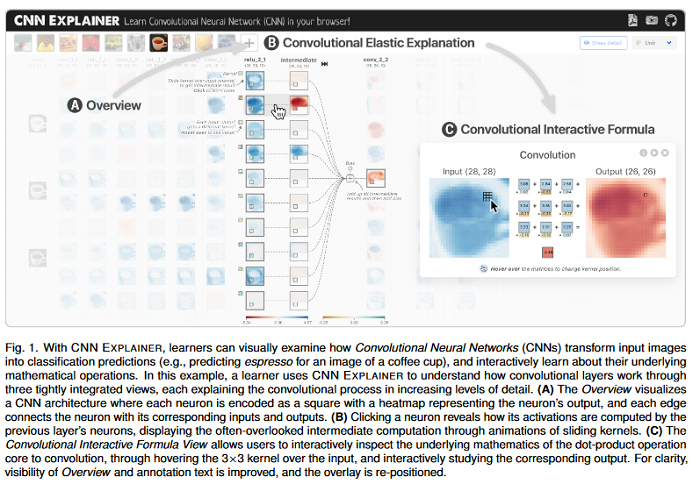
CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization

Deep learning’s great success motivates many practitioners and students to learn about this exciting technology. However, it is often challenging for beginners to take their first step due to the complexity of understanding and applying deep learning. This paper presents CNN Explainer, an interactive visualization tool designed for non-experts to learn and examine convolutional neural networks (CNNs), a foundational deep learning model architecture. The tool addresses key challenges that novices face while learning about CNNs, which are identified from interviews with instructors and a survey with past students. Users can interactively visualize and inspect the data transformation and flow of intermediate results in a CNN. CNN Explainer tightly integrates a model overview that summarizes a CNN’s structure, and on-demand, dynamic visual explanation views that help users understand the underlying components of CNNs. Through smooth transitions across levels of abstraction, the tool enables users to inspect the interplay between low-level operations (e.g., mathematical computations) and high-level outcomes (e.g., class predictions). Developed using modern web technologies, CNN Explainer runs locally in users’ web browsers without the need for installation or specialized hardware, broadening the public’s education access to modern deep learning techniques. The TensorFlow code associated with this paper can be found HERE.
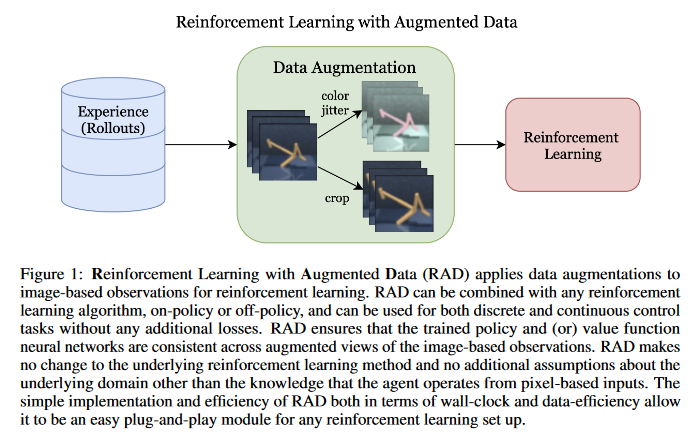
Reinforcement Learning with Augmented Data
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments. To this end, this paper presents RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. It is shown that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. It is found that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method. The PyTorch code associated with this paper can be found HERE.
TLDR: Extreme Summarization of Scientific Documents
This paper introduces TLDR generation for scientific papers, a new automatic summarization task with high source compression, requiring expert background knowledge and complex language understanding. To facilitate research on this task, the paper introduces SciTLDR, a data set of 3.9K TLDRs. Furthermore, the paper introduces a novel annotation protocol for scalably curating additional gold summaries by rewriting peer review comments. This protocol is used to augment the test set, yielding multiple gold TLDRs for evaluation, which is unlike most recent summarization data sets that assume only one valid gold summary. The paper presents a training strategy for adapting pre-trained language models that exploits similarities between TLDR generation and the related task of title generation, which outperforms strong extractive and abstractive summarization baselines. The GitHub repo associated with this paper can be found HERE.

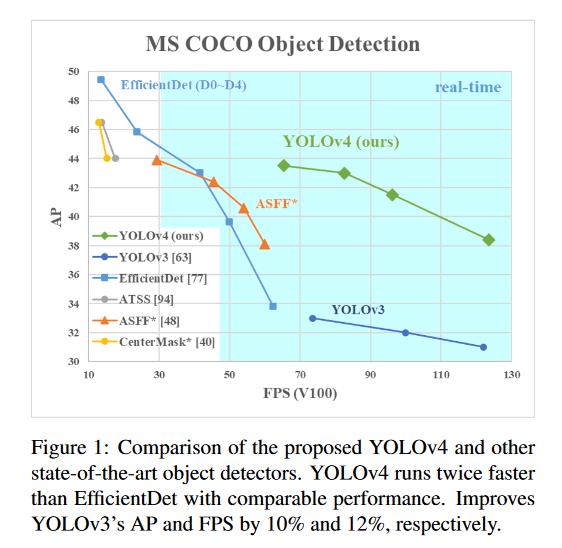
YOLOv4: Optimal Speed and Accuracy of Object Detection
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large data sets, and theoretical justification of the result, is required. Some features operate on certain models exclusively and for certain problems exclusively, or only for small-scale datasets; while some features, such as batch-normalization and residual-connections, are applicable to the majority of models, tasks, and data sets. This paper’s authors assume that such universal features include Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation. They use new features: WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, and CIoU loss, and combine some of them to achieve state-of-the-art results: 43.5% AP (65.7% AP50) for the MS COCO data set at a realtime speed of ~65 FPS on Tesla V100. The PyTorch code associate with this paper can be found HERE.
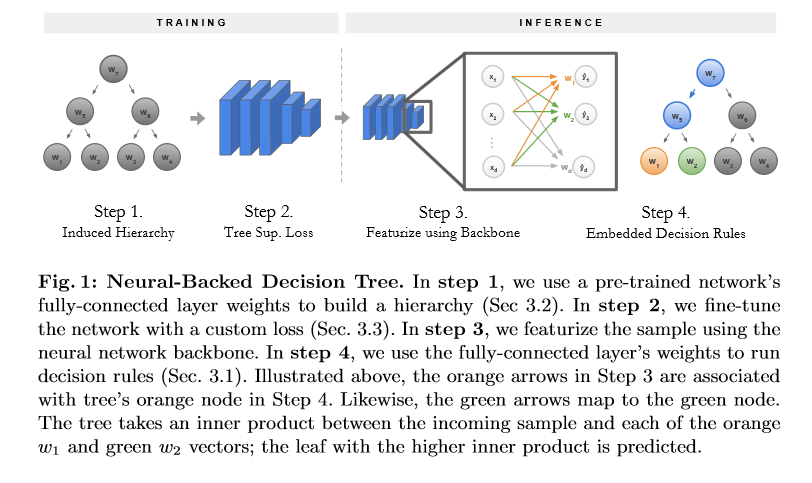
NBDT: Neural-Backed Decision Trees
Deep learning is being adopted in settings where accurate and justifiable predictions are required, ranging from finance to medical imaging. While there has been recent work providing post-hoc explanations for model predictions, there has been relatively little work exploring more directly interpretable models that can match state-of-the-art accuracy. Historically, decision trees have been the gold standard in balancing interpretability and accuracy. However, recent attempts to combine decision trees with deep learning have resulted in models that (1) achieve accuracies far lower than that of modern neural networks (e.g. ResNet) even on small datasets (e.g. MNIST), and (2) require significantly different architectures, forcing practitioners pick between accuracy and interpretability. This paper forgoes this dilemma by creating Neural-Backed Decision Trees (NBDTs) that (1) achieve neural network accuracy and (2) require no architectural changes to a neural network. NBDTs achieve accuracy within 1% of the base neural network on CIFAR10, CIFAR100, TinyImageNet, using recently state-of-the-art WideResNet; and within 2% of EfficientNet on ImageNet. This yields state-of-the-art explainable models on ImageNet, with NBDTs improving the baseline by ~14% to 75.30% top-1 accuracy. Furthermore, it is shown interpretability of the model’s decisions both qualitatively and quantitatively via a semi-automatic process. The PyTorch code associated with this paper can be found HERE.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind