
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
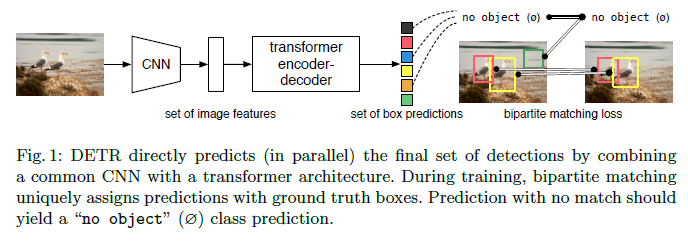
End-to-End Object Detection with Transformers
This paper presents a new method that views object detection as a direct set prediction problem. The approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. PyTorch training code and pretrained models are available at HERE.
BERTweet: A pre-trained language model for English Tweets
This paper presents BERTweet, the first public large-scale pre-trained language model for English Tweets. BERTweet is trained using the RoBERTa pre-training procedure (Liu et al., 2019), with the same model configuration as BERT-base (Devlin et al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al., 2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks: Part-of-speech tagging, Named-entity recognition and text classification. BERTweet is released to facilitate future research and downstream applications on Tweet data. PyTorch BERTweet code is available HERE.
Spoof Face Detection Via Semi-Supervised Adversarial Training
Face spoofing causes severe security threats in face recognition systems. Previous anti-spoofing works focused on supervised techniques, typically with either binary or auxiliary supervision. Most of them suffer from limited robustness and generalization, especially in the cross-dataset setting. This paper proposes a semi-supervised adversarial learning framework for spoof face detection, which largely relaxes the supervision condition. To capture the underlying structure of live faces data in latent representation space, the proposal it to train the live face data only, with a convolutional Encoder-Decoder network acting as a Generator. Meanwhile, a second convolutional network is added serving as a Discriminator. The generator and discriminator are trained by competing with each other while collaborating to understand the underlying concept in the normal class(live faces). Since the spoof face detection is video based (i.e., temporal information), the optical flow maps are converted from consecutive video frames as input. The approach is free of the spoof faces, thus being robust and general to different types of spoof, even unknown spoof.

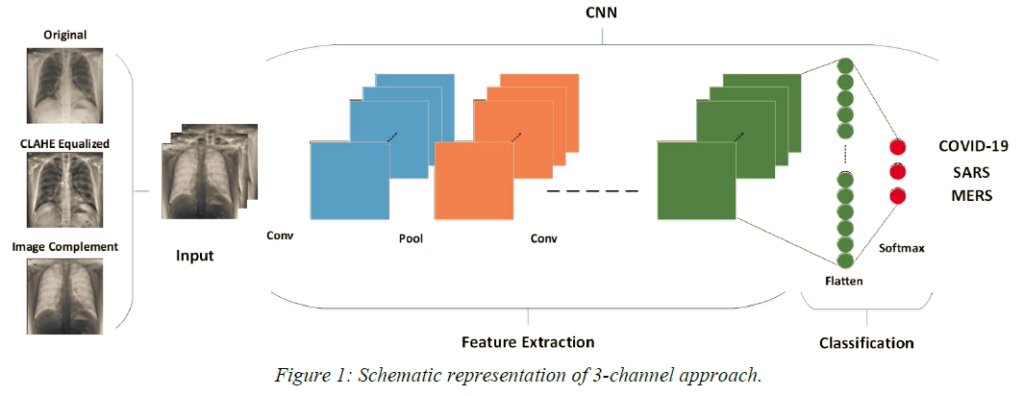
Coronavirus: Comparing COVID-19, SARS and MERS in the eyes of AI
Novel Coronavirus disease (COVID-19) is an extremely contagious and quickly spreading Coronavirus disease. Severe Acute Respiratory Syndrome (SARS)-CoV, Middle East Respiratory Syndrome (MERS)-CoV outbreak in 2002 and 2011 and current COVID-19 pandemic all from the same family of Coronavirus. The fatality rate due to SARS and MERS were higher than COVID-19 however, the spread of those were limited to few countries while COVID-19 affected more than two-hundred countries of the world. This paper uses deep machine learning algorithms along with innovative image pre-processing techniques to distinguish COVID-19 images from SARS and MERS images. Several deep learning algorithms were trained, and tested and four outperforming algorithms were reported: SqueezeNet, ResNet18, Inceptionv3 and DenseNet201.
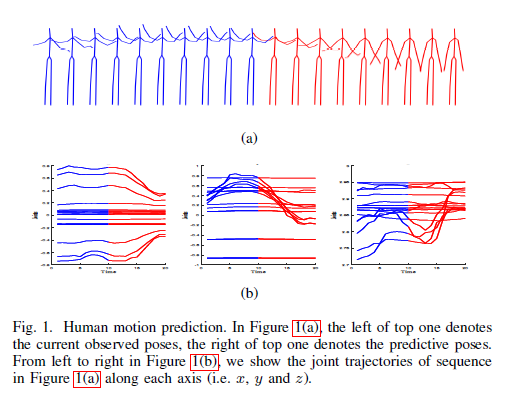
AGVNet: Attention Guided Velocity Learning for 3D Human Motion Prediction
Human motion prediction plays a vital role in human-robot interaction with various applications such as family service robot. Most of the existing works did not explicitly model velocities of skeletal motion that carried rich motion dynamics, which is critical to predict future poses. This paper proposes a novel feedforward network, AGVNet (Attention Guided Velocity Learning Network), to predict future poses, which explicitly models the velocities at both Encoder and Decoder. Specifically, a novel two-stream Encoder is proposed to encode the skeletal motion in both velocity space and position space. Then, a new feedforward Decoder is presented to predict future velocities instead of position poses, which enables the network to predict multiple future velocities recursively like RNN based Decoder. Finally, a novel loss, ATPL (Attention Temporal Prediction Loss), is designed to pay more attention to the early predictions, which can efficiently guide the recursive model to achieve more accurate predictions. Extensive experiments show the method achieves state-of-the-art performance on two benchmark datasets (i.e. Human3.6M and 3DPW) for human motion prediction.

One of the most significant challenges in statistical signal processing and machine learning is how to obtain a generative model that can produce samples of large-scale data distribution, such as images and speeches. Generative Adversarial Network (GAN) is an effective method to address this problem. The GANs provide an appropriate way to learn deep representations without widespread use of labeled training data. This approach has attracted the attention of many researchers in computer vision since it can generate a large amount of data without precise modeling of the probability density function (PDF). In GANs, the generative model is estimated via a competitive process where the generator and discriminator networks are trained simultaneously. The generator learns to generate plausible data, and the discriminator learns to distinguish fake data created by the generator from real data samples. Given the rapid growth of GANs over the last few years and their application in various fields, it is necessary to investigate these networks accurately. This paper, after introducing the main concepts and the theory of GAN, compares two new deep generative models, and the evaluation metrics utilized in the literature and challenges of GANs are also explained. Moreover, the most remarkable GAN architectures are categorized and discussed. Finally, the essential applications in computer vision are examined.

Recently, a groundswell of research has identified the use of counterfactual explanations as a potentially significant solution to the Explainable AI (XAI) problem. It is argued that (a) technically, these counterfactual cases can be generated by permuting problem-features until a class change is found, (b) psychologically, they are much more causally informative than factual explanations, (c) legally, they are GDPR-compliant. However, there are issues around the finding of good counterfactuals using current techniques (e.g. sparsity and plausibility). This paper shows that many commonly-used datasets appear to have few good counterfactuals for explanation purposes. So, it is proposed a new case based approach for generating counterfactuals using novel ideas about the counterfactual potential and explanatory coverage of a case-base. The new technique reuses patterns of good counterfactuals, present in a case-base, to generate analogous counterfactuals that can explain new problems and their solutions. Several experiments show how this technique can improve the counterfactual potential and explanatory coverage of case-bases that were previously found wanting.

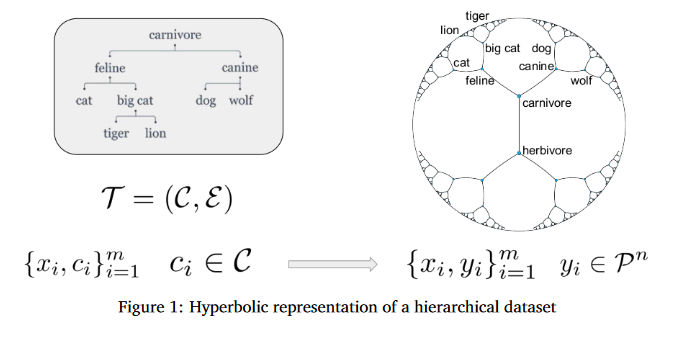
Hyperbolic Manifold Regression
Geometric representation learning has recently shown great promise in several machine learning settings, ranging from relational learning to language processing and generative models. This paper considers the problem of performing manifold-valued regression onto an hyperbolic space as an intermediate component for a number of relevant machine learning applications. In particular, by formulating the problem of predicting nodes of a tree as a manifold regression task in the hyperbolic space, a novel perspective is proposed on two challenging tasks: 1) hierarchical classification via label embeddings and 2) taxonomy extension of hyperbolic representations. To address the regression problem the researchers consider previous methods as well as proposing two novel approaches that are computationally more advantageous: a parametric deep learning model that is informed by the geodesics of the target space and a non-parametric kernel-method for which we also prove excess risk bounds. Our experiments show that the strategy of leveraging the hyperbolic geometry is promising. In particular, in the taxonomy expansion setting, the work finds that the hyperbolic-based estimators significantly outperform methods performing regression in the ambient Euclidean space.
Comparing BERT against traditional machine learning text classification
The BERT model has arisen as a popular state-of-the-art machine learning model in the recent years that is able to cope with multiple NLP tasks such as supervised text classification without human supervision. Its flexibility to cope with any type of corpus delivering great results has make this approach very popular not only in academia but also in the industry. Although, there are lots of different approaches that have been used throughout the years with success. This paper first presents BERT and includes a little review on classical NLP approaches. Then, the researchers empirically test with a suite of experiments dealing different scenarios the behaviour of BERT against the traditional TF-IDF vocabulary fed to machine learning algorithms. The purpose of this work is to add empirical evidence to support or refuse the use of BERT as a default on NLP tasks. Experiments show the superiority of BERT and its independence of features of the NLP problem such as the language of the text adding empirical evidence to use BERT as a default technique to be used in NLP problems.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind