
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Discovering Symbolic Models from Deep Learning with Inductive Biases

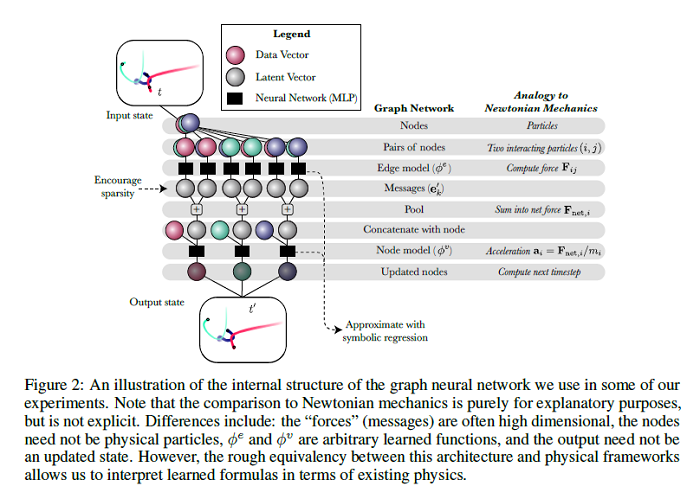
The authors of this paper develop a general approach to distill symbolic representations of a learned deep model by introducing strong inductive biases. The focus is on Graph Neural Networks (GNNs). The technique works as follows: we first encourage sparse latent representations when we train a GNN in a supervised setting, then we apply symbolic regression to components of the learned model to extract explicit physical relations. We find the correct known equations, including force laws and Hamiltonians, can be extracted from the neural network. We then apply our method to a non-trivial cosmology example-a detailed dark matter simulation-and discover a new analytic formula which can predict the concentration of dark matter from the mass distribution of nearby cosmic structures. The symbolic expressions extracted from the GNN using our technique also generalized to out-of-distribution data better than the GNN itself. The approach offers alternative directions for interpreting neural networks and discovering novel physical principles from the representations they learn.
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Machine learning research has advanced in multiple aspects, including model structures and learning methods. The effort to automate such research, known as AutoML, has also made significant progress. However, this progress has largely focused on the architecture of neural networks, where it has relied on sophisticated expert-designed layers as building blocks—or similarly restrictive search spaces. The goal of this paper is to show that AutoML can go further: it is possible today to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. This is demonstrated by introducing a novel framework that significantly reduces human bias through a generic search space. Despite the vastness of this space, evolutionary search can still discover two-layer neural networks trained by backpropagation. These simple neural networks can then be surpassed by evolving directly on tasks of interest, e.g. CIFAR-10 variants, where modern techniques emerge in the top algorithms, such as bilinear interactions, normalized gradients, and weight averaging. Moreover, evolution adapts algorithms to different task types: e.g., dropout-like techniques appear when little data is available.

Contrastive Generative Adversarial Networks
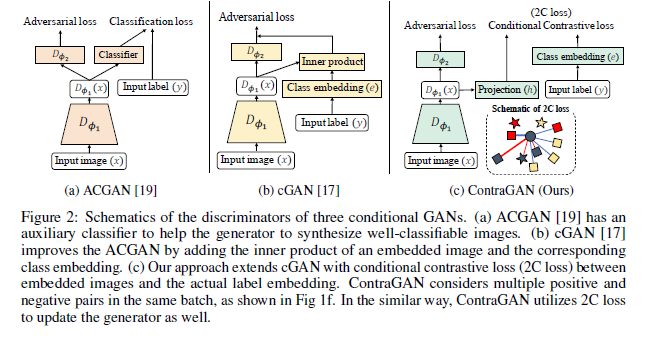
Conditional image synthesis is the task to generate high-fidelity diverse images using class label information. Although many studies have shown realistic results, there is room for improvement if the number of classes increases. This paper proposes a novel conditional contrastive loss to maximize a lower bound on mutual information between samples from the same class. The framework, called Contrastive Generative Adversarial Networks (ContraGAN), learns to synthesize images using class information and data-to-data relations of training examples. The discriminator in ContraGAN discriminates the authenticity of given samples and maximizes the mutual information between embeddings of real images from the same class. Simultaneously, the generator attempts to synthesize images to fool the discriminator and to maximize the mutual information of fake images from the same class prior. The experimental results show that ContraGAN is robust to network architecture selection and outperforms state-of-the-art-models by 3.7% and 11.2% on CIFAR10 and Tiny ImageNet datasets, respectively, without any data augmentation. The software package that can re-produce all experiments is available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
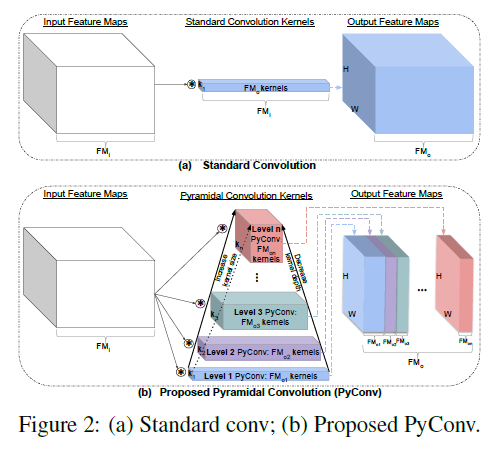
This work introduces pyramidal convolution (PyConv), which is capable of processing the input at multiple filter scales. PyConv contains a pyramid of kernels, where each level involves different types of filters with varying size and depth, which are able to capture different levels of details in the scene. On top of these improved recognition capabilities, PyConv is also efficient and, with our formulation, it does not increase the computational cost and parameters compared to standard convolution. Moreover, it is very flexible and extensible, providing a large space of potential network architectures for different applications. PyConv has the potential to impact nearly every computer vision task and this work presents different architectures based on PyConv for four main tasks on visual recognition: image classification, video action classification/recognition, object detection and semantic image segmentation/parsing. The approach shows significant improvements over all these core tasks in comparison with the baselines. For instance, on image recognition, our 50-layers network outperforms in terms of recognition performance on ImageNet dataset its counterpart baseline ResNet with 152 layers, while having 2.39 times less parameters, 2.52 times lower computational complexity and more than 3 times less layers. On image segmentation, the novel framework sets a new state-of-the-art on the challenging ADE20K benchmark for scene parsing. Code is available at: https://github.com/iduta/pyconv
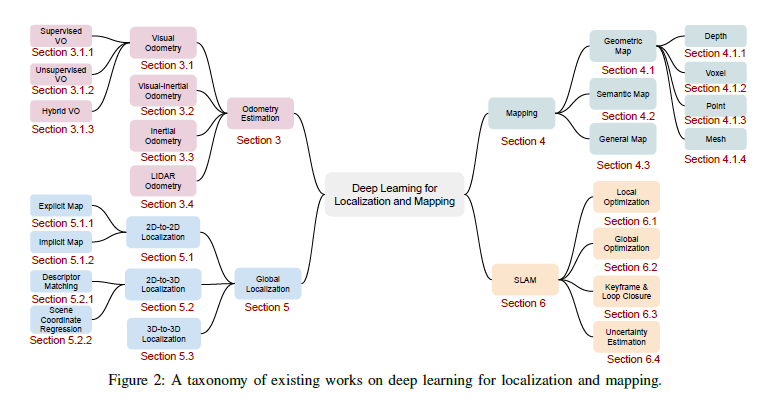
Deep learning based localization and mapping has recently attracted significant attention. Instead of creating hand-designed algorithms through exploitation of physical models or geometric theories, deep learning based solutions provide an alternative to solve the problem in a data-driven way. Benefiting from ever-increasing volumes of data and computational power, these methods are fast evolving into a new area that offers accurate and robust systems to track motion and estimate scenes and their structure for real-world applications. This papper provides a comprehensive survey, and propose a new taxonomy for localization and mapping using deep learning. Also discussed are the limitations of current models, and indicate possible future directions. A wide range of topics are covered, from learning odometry estimation, mapping, to global localization and simultaneous localization and mapping (SLAM). Revisited is the problem of perceiving self-motion and scene understanding with on-board sensors, and also shown is how to solve it by integrating these modules into a prospective spatial machine intelligence system (SMIS). The hope is that this work can connect emerging works from robotics, computer vision and machine learning communities, and serve as a guide for future researchers to apply deep learning to tackle localization and mapping problems. TensorFlow code associated with this paper can be found here: https://github.com/changhao-chen/deep-learning-localization-mapping
Rethinking the Truly Unsupervised Image-to-Image Translation
Every recent image-to-image translation model uses either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision at minimum. However, even the set-level supervision can be a serious bottleneck for data collection in practice. This paper tackles image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. It is proposed the truly unsupervised image-to-image translation method (TUNIT) that simultaneously learns to separate image domains via an information-theoretic approach and generate corresponding images using the estimated domain labels. Experimental results on various datasets show that the proposed method successfully separates domains and translates images across those domains. In addition, the model outperforms existing set-level supervised methods under a semi-supervised setting, where a subset of domain labels is provided. The source code is available at https://github.com/clovaai/tunit

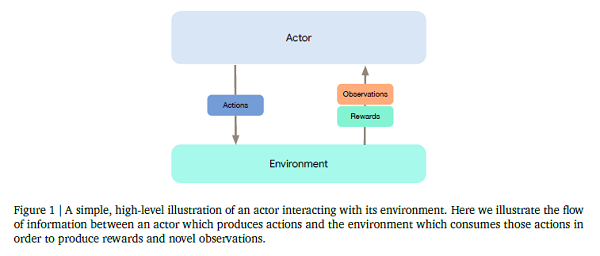
Acme: A Research Framework for Distributed Reinforcement Learning
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, this paper introduces Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end baseline implementations of various algorithms are being released, created using the framework. This work also introduces the major design decisions behind Acme and show how these are used to construct these baselines. Software associated with this research can be found here: https://github.com/deepmind/acme
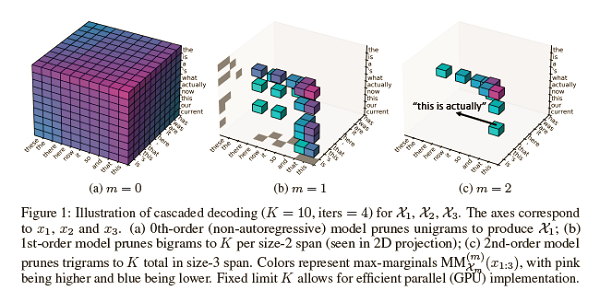
Cascaded Text Generation with Markov Transformers
The two dominant approaches to neural text generation are fully autoregressive models, using serial beam search decoding, and non-autoregressive models, using parallel decoding with no output dependencies. This work proposes an autoregressive model with sub-linear parallel time generation. Noting that conditional random fields with bounded context can be decoded in parallel, the paper proposes an efficient cascaded decoding approach for generating high-quality output. To parameterize this cascade, a Markov transformer is introduced, a variant of the popular fully autoregressive model that allows us to simultaneously decode with specific autoregressive context cutoffs. This approach requires only a small modification from standard autoregressive training, while showing competitive accuracy/speed tradeoff compared to existing methods on five machine translation datasets.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind