
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
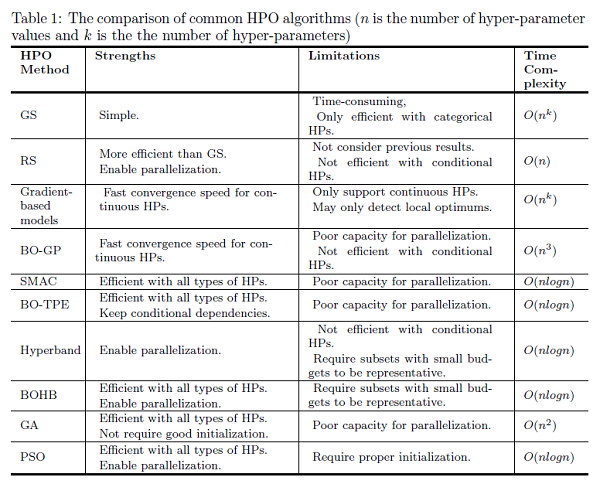
On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice

Machine learning algorithms have been used widely in various applications and areas. To fit a machine learning model into different problems, its hyper-parameters must be tuned. Selecting the best hyper-parameter configuration for machine learning models has a direct impact on the model’s performance. It often requires deep knowledge of machine learning algorithms and appropriate hyper-parameter optimization techniques. Although several automatic optimization techniques exist, they have different strengths and drawbacks when applied to different types of problems. In this paper, optimizing the hyper-parameters of common machine learning models is studied. Several state-of-the-art optimization techniques are introduced in terms of how to apply them to machine learning algorithms. Many available libraries and frameworks developed for hyper-parameter optimization problems are provided, and some open challenges of hyper-parameter optimization research are also discussed in this paper. Moreover, experiments are conducted on benchmark datasets to compare the performance of different optimization methods and provide practical examples of hyper-parameter optimization. This survey paper will help industrial users, data analysts, and researchers to better develop machine learning models by identifying the proper hyper-parameter configurations effectively.
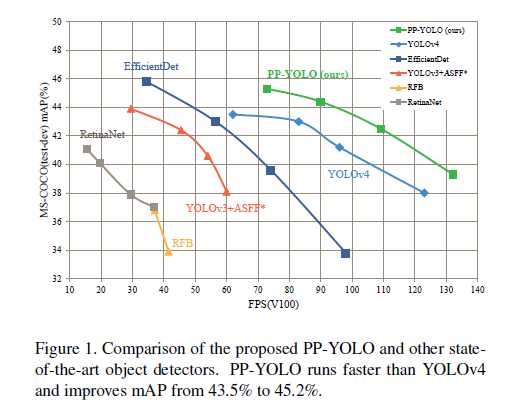
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, this paper describes the development of a new object detector based on YOLOv3. The Baidu, Inc. researchers mainly try to combine various existing tricks that do not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, the new technique is PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4. Source code associated with this paper can be found HERE.
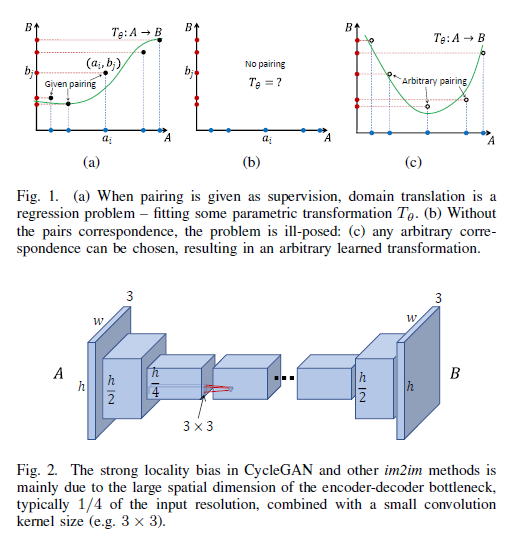
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but this paper shows that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. This paper introduces linear encoder-decoder architectures for unsupervised image to image translation. The paper shows that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, the paper shows a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.
Learning perturbation sets for robust machine learning
Although much progress has been made towards robust deep learning, a significant gap in robustness remains between real-world perturbations and more narrowly defined sets typically studied in adversarial defenses. This paper aims to bridge this gap by learning perturbation sets from data, in order to characterize real-world effects for robust training and evaluation. Specifically, the researchers use a conditional generator that defines the perturbation set over a constrained region of the latent space. The authors formulate desirable properties that measure the quality of a learned perturbation set, and theoretically prove that a conditional variational autoencoder naturally satisfies these criteria. Using this framework, the approach can generate a variety of perturbations at different complexities and scales, ranging from baseline digit transformations, through common image corruptions, to lighting variations. The quality of learned perturbation sets were measured both quantitatively and qualitatively, finding that the models are capable of producing a diverse set of meaningful perturbations beyond the limited data seen during training. Finally, the learned perturbation sets were leveraged to learn models which have improved generalization performance and are empirically and certifiably robust to adversarial image corruptions and adversarial lighting variations. All code and configuration files for reproducing the experiments as well as pretrained model weights can be found HERE.

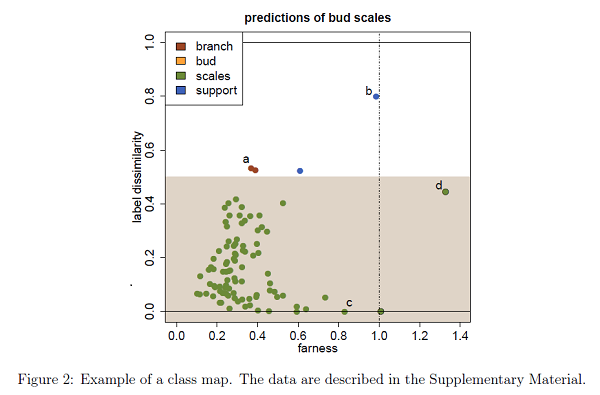
Visualizing classification results
Classification is a major tool of statistics and machine learning. A classification method first processes a training set of objects with given classes (labels), with the goal of afterward assigning new objects to one of these classes. When running the resulting prediction method on the training data or on test data, it can happen that an object is predicted to lie in a class that differs from its given label. This is sometimes called label bias, and raises the question whether the object was mislabeled.Our goal is to visualize aspects of the data classification to obtain insight. The proposed display reflects to what extent each object’s label is (dis)similar to its prediction, how far each object lies from the other objects in its class, and whether some objects lie far from all classes. The display is constructed for discriminant analysis, the k-nearest neighbor classifier, support vector machines, logistic regression, and majority voting. It is illustrated on several benchmark datasets containing images and texts.
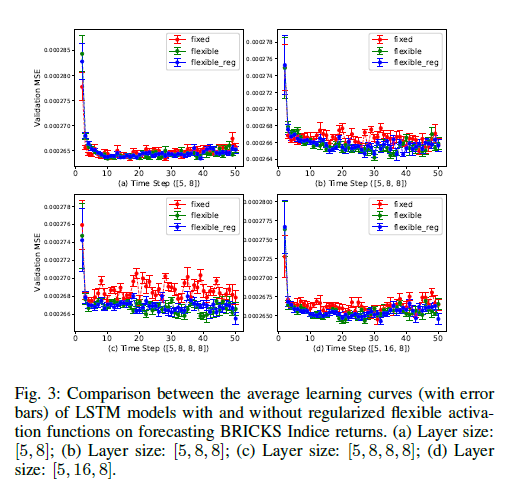
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. This study looks at three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions.
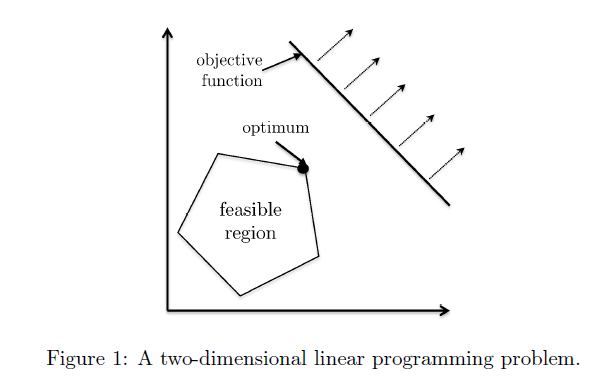
Beyond the Worst-Case Analysis of Algorithms (Introduction)
One of the primary goals of the mathematical analysis of algorithms is to provide guidance about which algorithm is the “best” for solving a given computational problem. Worst-case analysis summarizes the performance profile of an algorithm by its worst performance on any input of a given size, implicitly advocating for the algorithm with the best-possible worst-case performance. Strong worst-case guarantees are the holy grail of algorithm design, providing an application-agnostic certification of an algorithm’s robustly good performance. However, for many fundamental problems and performance measures, such guarantees are impossible and a more nuanced analysis approach is called for. This paper surveys several alternatives to worst-case analysis.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind