
In this special guest feature, Scott Stephenson, CEO of Deepgram, dives into the evolution of ASR, popular use cases, current limitations, and a few predictions for how the technology will continue to evolve in the enterprise. Scott is a dark matter physicist turned deep learning entrepreneur. He earned a PhD in particle physics from University of Michigan where his research involved building a lab two miles underground to detect dark matter. Scott left his physics post-doc research position to found Deepgram.
The advent of Siri, Alexa and Google Home has made automatic speech recognition (ASR) increasingly popular. After all, ASR is the driving force behind a wide array of modern technologies. If you have a smartphone, for example, then you have ASR right at your fingertips. However, ASR is so much more than Siri or Alexa and has burgeoning potential across the enterprise. To help you visualize the bigger picture from a business perspective, I’ll dive into the evolution of ASR, popular use cases, current limitations and a few predictions for how the technology will continue to evolve in the enterprise.
The Evolution of ASR
For starters, ASR is a technology used to automatically process audio data (e.g., phone calls, online meetings, voice searches on your phone, podcasts, etc.) into a format computers can understand. Speech-to-text (STT) is a synonym for ASR. Similar to STT, the output of ASR is readable text, which is a crucial first step to figuring out what information is hiding in voice recordings. For example, easily identifying questions or concerns that come up in sales conversations can enable your sales team to make adjustments or better anticipate those concerns.
The ASR you interact with today, most commonly in the form of Siri or Alexa, has come a long way since its humble beginnings in the 1950s and 1960s, when researchers made hand-wired systems that could only recognize individual words—not sentences or phrases. N-gram models were widely used in natural language processing at this time, with phonemes and sequences of phonemes modeled such that each n-gram was composed of n words. In the 1970s, funding from the Advanced Research Projects Agency (ARPA) helped a team from Carnegie Mellon University create technology that produced transcripts from context-specific speech, such as voice-controlled versions of chess games.
In the 1990s, Nuance built on this approach by developing Dragon, software that could transcribe single speakers who spoke clearly in low-noise environments. This product and its n-gram (uni, bi or tri-gram language) model usage were revolutionary at the time and are still used today, however they are too costly, time-consuming, and insufficient to carry out AI-driven analytics that digitally minded enterprises require.
Then, in the 2010s, Nuance, Google and Amazon made ASR work with multiple speakers in noisy environments by replacing parts of their speech recognition technology with neural networks. This hybrid approach was a big step for general purpose transcription—for example transcribing audio based on common vocabulary found on sites like Wikipedia—but still isn’t accurate or fast enough to recognize enterprise-specific voice data sets.
The newest approach, end-to-end deep learning, allows enterprises to quickly train the ASR to accurately and efficiently recognize dialects, accents and multiple languages. Unlike its predecessors, it does not use n-gram models to convert sounds to text. Instead, the transcription engine is made up entirely of neural networks. To customize these models, you feed it labeled data, enabling the neural network to learn to recognize that data more effectively moving forward. End-to-end deep learning ASR eliminates customization problems—enabling engineers to stop hard coding changes into models—and instead use that time to analyze text and build sentiment models to gain more valuable insights from their voice data.
Popular Business Use Cases
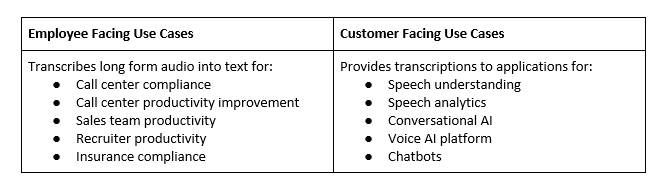
For enterprises considering an end-to-end deep learning ASR approach, there are many diverse use cases that help illustrate its impact. For example, call centers and companies with large call volumes leverage ASR to automatically find meaningful information hiding in their thousands of hours of call recordings, helping them get inside customers’ minds. Insurance companies use ASR to stay compliant with government and industry regulations by recording calls and providing meeting summaries, saving millions of dollars in the long run. Sales enablement platforms also use ASR to track trends and deliver insights into sales calls for coaching purposes—helping sales teams close more deals. In case it’s helpful to visualize, below is a chart to demonstrate a few key internal and external use cases.
How Enterprises can Utilize ASR:
Current Limitations of ASR
While ASR has come a long way since its inception, the technology isn’t perfect. Diminished accuracy is one of its current limitations. Just as you can’t jump into any conversation in the world and immediately understand what’s being discussed, general ASR models can struggle with picking up accents, industry specific terms and languages. After all, enterprise audio data typically involves multiple speakers who have varying vocal attributes and a tendency to speak over one another, which can reduce accuracy as a result.
The limited ability of an ASR model to form and recall memories is another major limitation. If a human is transcribing audio data and doesn’t understand a specific term the first time around, he or she can gain additional knowledge later in the call that will allow them to go back and update the first reference. An ASR system, on the other hand, can’t store memories or make these connections to the same degree. Say a tri-gram ASR model is analyzing one word in particular. It can retain the previous two words that were said (hence the three in tri-gram), but will drop all three words from memory once its evaluation is complete. This presents an accuracy challenge in long-form audio. With 150 words said per minute, on average, even a 15-second clip of an audio file can include 40 spoken words, which can lead to various missed context clues on the ASR model’s part.
Lastly, most ASR models are also not computationally efficient. Using ASR technology is resource-intensive—it takes up memory, uses resources from other areas, and will drain your battery (if you’re a consumer) and your budget (if you’re an enterprise) if you’re not careful. New 100% deep learning-based methods are changing this in a big way.
Looking Ahead to New and Improved ASR Models
Speech is an important problem to solve—more than a single feature, it is a strategic asset that will power the next wave of applications and give call center, retail and tech industries access to an untapped and valuable resource. ASR that is selected intelligently, can create highly accurate transcripts and open the door to insights that lead to lower costs, higher revenue and improve overall business performance.
Looking ahead to the next few years, I predict that ASR will evolve in a few ways. Larger ASR models will become more strong and effective. Smaller ASR models, such as one in an edge device like a smartphone, will be refined to take up less memory while maintaining a high level of accuracy. I believe that speech recognition will also continue to evolve in terms of accuracy and understanding, powering more definite and insightful insights overall. To evoke Oprah’s “you get a car” meme, there used to only be one available speech recognition model, but now there can be millions that get you and your business.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind