How machine learning affects social media content?
The impact on artificial intelligence on tech platforms
What was once seen as fiction in scientific movies has become a reality and has gained popularity across various sectors. Your smartphones, mobile applications, vehicles, and many other daily consumer items use AI to build essential parts of their business or product around machine learning (ML). Even more so, becoming more integrated into many aspects of social media AI is far from replacing human touch in social media. It is increasing both the quantity and quality of online interactions between businesses and their customers.
The use of such algorithms in social content projects and about principles of team formation has become even more crucial in their development.
A bit of the backstory
A short intro: FunCorp, develops and operates UGC services for different geo and audience niches, our pool of projects includes mobile apps iFunny, iDaPrikol, America’s Best Pics, and Videos , KEKE Germany and WHLSM with a total monthly audience of more than 12 million users and a total install base close to 100 million.
We made our way from temporary feeds, where the content was displayed simply in the order it was uploaded, to complete personalization, with a short stop for collaborative filtering while not having a user social graph to form the initial feed and interests.
We started to think about it about six to seven years ago, but at that time we didn’t know where it would lead to and whether we were doing it in the right way or not. The global objective was to show the users the content they would like to see and to minimize or completely remove the content they didn’t like or were indifferent to. First, we supposed it would influence users’ return, and later we got confirmation of this hypothesis.
Of the nine years of our company’s existence, there have been several approaches to this task. In the beginning, we tried an obvious way to sort the feed by the number of smiles (analog of likes) – Smile rate.
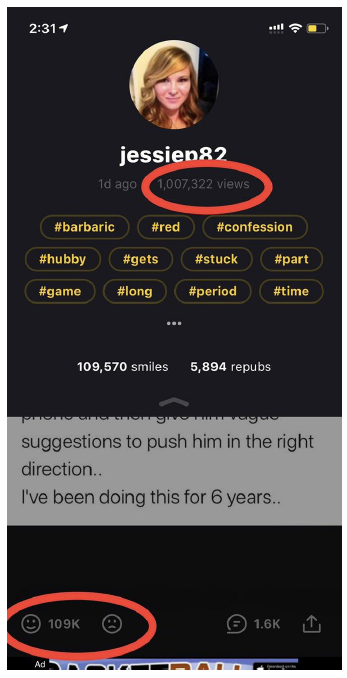
It was better than sorting in chronological order, but at the same time, it led to the effect of “ the patient’s average temperature in a hospital” : everyone enjoys rare humor, and there will always be those who are not interested in (and sometimes annoyed by) topics popular today. Most importantly, humor is a very subjective thing, and memes have always been famous for being satirical and on-the-edge, so it is necessary to clearly understand which user reacts to which particular content with indignation, boredom and laughter, and in the end the funnier is the feed – the higher is the retention rate and lifetime of the user. In fact, by 2016-2017, this rule had spread to absolutely all content projects. This was the key to the success of many of them. Ease of use and relevance are two main success factors of a content project.
The next step arises logically from the first one.
In this experiment, we started trying to take into account the interests of different micro-communities: fans of anime, sport, memes with cats and dogs, lovers of dank memes, and many others. For this purpose, we began to form several thematic featured feeds and offered users to select topics of interest by using tags and text recognized in pictures. It became better in some aspects, but the social network effect was lost: there was less involved in the content. And on the way to segmented feeds, a lot of really top trend memes were lost. Users saw the specific content, but the trendiness was missing.
Further, it was decided to use the principle of collaborative filtering in trend issues. This principle is useful when the product does not have enough personal data of the user, and this point is the company’s principled position. We do not care who you are; we only care what you like. For this purpose, product analytics and actions performed by the user inside the product, are enough.
Collaborative filtering works the following way: it takes a history of positive ratings of the content by the user, there are other users with similar scores, then what these users liked earlier is recommended to this user (with similar ratings).
Task specifics
About 85% of the content shared on social media today is in the form of memes. Memes are quite specific content. Let us look at some of the task specifics that are needed:
- It is entirely subject to rapidly changing trends. The material and the form that were on the top and made 80% of the audience smile a week ago, can only be exasperated by being outdated and shown for the second time.
- It is a very non-linear and situational interpretation of the meaning of a meme. In the news gathering, the lead can be well-known surnames, topics, which quite consistently hit a particular user. In the selection of movies, the point can be the cast, genre, and much more. Yes, all these can be the lead for the collection of personal memes. But how disappointing it will be to miss a real masterpiece of humor, which sarcastically uses images or vocabulary that does not lie in semantic content!
- Finally, there is a considerable amount of dynamically generated content. On iFunny, users create hundreds of thousands of posts every day. All this content needs to be analyzed and evaluated as quickly as possible. In the case of a personalized recommendation system, it is necessary not only to find “diamonds,” but also to predict the rating of content by various representatives of society.
What do these specifics mean for a machine learning model development? Of all, the model must be continuously trained in the latest data. At the beginning of the dive into the recommendation system development, it is not entirely clear whether we are talking about tens of minutes or a couple of hours. But both mean that there has to be continuous retraining of the model and even better real- time training on consistent data flow. These are not the most manageable tasks for searching for a suitable model architecture and selecting its hyper- parameters: those that would guarantee that in two-three weeks, metrics will not start to degrade inevitably.
Another difficulty is the necessity to follow the A/B-test protocol. We never implement anything without first checking with a part of users, comparing the results with the control group, and we recommend everyone develop the product this way.
After much reflection, it was decided to start MVP with the following characteristics: we use only information about the user interaction with the content, the model is trained in real-time right on the server equipped with ample memory space, allowing you to store the entire history of the interaction of the users from the test group for a quite long time. We decided to limit the training time to 15-20 minutes to maintain the novelty effect and have time to use the latest data from users visiting the application at once in a time of content releases.
The Model
First, we started to work with the most excellent collaborative filtering with matrix decomposition and training on ALS (alternating least squares) or SGD (stochastic gradient descent). But soon we thought: why not start with the most straightforward neural network right away? With a simple single- layer net and only one linear embedding-layer. Without adding hidden layers so as not to bury ourselves in weeks of choosing its hyperparameters. A little beyond MVP? Maybe. But to train such a net is hardly more complicated than a more classical architecture if there is equipment with a good GPU (had to pay for it).
Initially, it was clear that there are only two scenarios: either the development will give a significant result in the product metrics, then it will be necessary to dig further in the parameters of users and content, in training on new material and new users, in deep neural networks, or personalized ranking of content will not bring a significant increase and testing can be stopped. If the first scenario occurs, all of the above will be reworked to the starting embedding layer.
We decided to choose the Neural Factorization Machine . Its operation principle is as follows: each user and each content is encoded by vectors of fixed identical length – embeddings, which are further trained on a set of known interactions between user and material.
In the training set, there were all the facts of content views by users.
- For positive feedback on content other than smiles/likes, it was also decided to consider clicking on the “share” or “save” buttons and writing a comment.
- If there is an interaction, it is marked as “1”.
- If, after viewing the user has not left positive feedback, the communication is scored “0”.
Thus, even in the absence of a precise rating scale, the Explicit Model (a model with an explicit rating from the user) is used instead of an Implicit one, which would only take decisive actions.
We tried the Implicit Mode l as well, but it didn’t start working right away, so we focused on the Explicit Model. Perhaps, for the Implicit Model, one should use more tricky, than simple binary cross-entropy, ranking loss functions.
The difference between Neural Matrix Factorization and the standard Neural Collaborative Filtering is in the so-called Bi-Interaction pooling layer, instead of the usual fully-connected layer, which would connect embedding vectors of the user and content. The Bi-Interaction layer converts a set of embedding vectors (there are only two vectors in iFunny – of the user and material) into a single vector by multiplying them element by element.
As a result of such training, the embedding of the users, who have used the smile feature the same, become close to each other. This is a convenient mathematical description of users, which can be used in many other tasks. However, this is a different story.
Therefore, the user starts watching the content in the feed. Each time the user views, smiles, shares, etc., the client sends statistics to our analytics repository. In the process, we select the events that interest us and send them to the ML server where they are stored in memory.
Every 15 minutes, on the server, there starts recalculation of the model. After each recalculation, the statistics, coming from the user, is taken into account in recommendations.
The client asks for the next page of the feed. It is then formed in a standard way. In the process, the content list is sent to the ML service. It sorts this content for the user, according to the recalculated model.
As a result, the users see the pictures and videos that the model thinks they will prefer.
Testing new models
The work with servers and data is done manually. For each new model, you need to have a server where you can then copy data needed for work (for example, from ClickHouse) or model.
Data on events in the “ Featured” feed (the main content feed of our products) starts being sent to the service alongside with the data transmission to control servers. Then via the A/B experiment, their return recommendations are from the new facility. In the event of any issues, one can turn off the operation and return to the control recommendations.
Results
The ML Content Rate service is the result of a large number of minor improvements and adjustments.
For starters, registered users were included in the training. Initially, there were questions about them because a priori they could not make actions with the content (smile, share, repost, comment) – the most frequent feedback after viewing the content. But soon, it became clear that these concerns were in vain and were blocking a critical growth point. Many experiments and training data selection are included with the configuration: this consists of a large part of the audience or expands the time interval of the considered interactions. During these experiments, it became clear that the amount of data plays a significant role in product metrics and the time of the model update. Often the increase in the quality of ranking sank in an extra 10-20 minutes to recalculate the model, which led to the rejection from novelties.
Many, even the smallest improvements have had results: they have either improved the quality of training or accelerated the training process or saved the storage space. For example, there was a problem that interactions did not fit into the storage space – we had to optimize them. Besides, the code was modified, and it became possible to include, for example, more interactions for recalculation. It also led to better stability of the service.
Now we are working on making effective use of known user and content parameters, on making an incremental, fast retrainable model, and also, there appear new hypotheses for future improvements. And we hire qualified specialists ready to help us to cope faster with the development of new ideas.
Each positive result leads to an increasing number of new hypotheses and tasks, which require the growth and strengthening of the machine learning team – we are working in this direction.
Out of all outcomes that are the most important are business results. Since the inception of the company’s existence, we have been focusing on the technological side, and we never wanted to deal with the semantic charge of content. Although indeed, everyone loves memes. After the implementation of ML and AI, it has allowed us not to have to pay constant attention to the content and its specifics. Therefore there appeared a window of opportunity to get to new audience niches and new countries, which was impossible a few years ago.
About the Author

Denis Litvinov is Co-founder and CIO of FunCorp, a mobile entertainment app development company. Denis brings an extensive amount of experience in tech product management, tech company management and development of user generated content platforms with AI and ML content feed aggregation, including the social media space with more than 4M daily active users at the moment. Throughout his career, Denis made several startups in social media games industry and has served as Head of Business Development, Eastern European market at Alibaba Mobile Business Group, a multinational technology company specializing in e-commerce, retail, Internet, and technology. Denis is a founding partner at FunCorp. He holds a bachelor’s degree in logistics and commerce from Saint Petersburg State University of Economics and Finance.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind