
A Technical Article Series for Data Architects
This multi-part article series is intended for data architects and anyone else interested in learning how to design modern real-time data analytics solutions. It explores key principles and implications of event streaming and streaming analytics, and concludes that the biggest opportunity to derive meaningful value from data – and gain continuous intelligence about the state of things – lies in the ability to analyze, learn and predict from real-time events in concert with contextual, static and dynamic data. This article series places continuous intelligence in an architectural context, with reference to established technologies and use cases in place today.
Part 6: Developing Continuous Intelligence Applications with Swim
In this article series we have focused on the needs of the application layer as it strives to deliver continuous intelligence from streamed events and contextual data. We have glossed over several issues of critical importance that relate to distribution, scalability, load balancing, security, persistence and availability of the runtime infrastructure that supports continuous intelligence. These are crucial issues and must be comprehensively addressed for any use case that is predicated on the continuous availability of insights. Suffice it to say that Swim comprehensively addresses application layer needs to succeed, and that this necessitates the distinction between two layers of resource management within the Swim application itself, namely the application tier and infrastructure tier. The latter relates solely to the infrastructure needed to deploy and run the application, lights out, while ensuring that it is resilient, scalable, secure and delivers valuable continuous intelligence to all its users.
Swim makes it easy to develop applications that statefully process streaming data on-the-fly, using an “analyze, act, and then store” architecture; thus, Swim applications are able to drive operational decisions that demand high resolution, contextual computation (see figure 7).
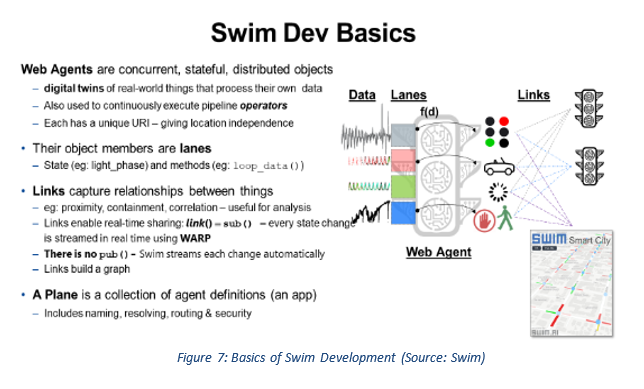
Getting started with Swim is easy:
- Developers focus only on the object model for their application, using (Swim extensions for) Java, and JavaScript for real-time browser-based UIs. Arriving events are used to build and scale the running application graph of concurrent Web Agents that compute as data flows.
- Swim manages resources for the application. It auto-scales application runtime infrastructure (including clusters of in-memory Swim instances interconnected by a p2p mesh of WebSockets) based on event rates and computational complexity to ensure that all Web Agents meet their real-time processing needs.
- Swim is easy to integrate into the DevOps application lifecycle: Developers use Java extensions that are deployed in user mode in containers on Linux, for example using Kubernetes. Hybrid and multi-cloud deployments are straightforward.
- Once deployed, applications run lights-out, securely and efficiently delivering granular insights and responses without complex operational overhead.
- The Swim platform delivers unimaginable performance for real-time analysis, and granular intelligence leveraging in-memory stateful processing and powerful real-time stream analysis.
Swim applications benefit from stateful, concurrent computation by Web Agents that may be distributed over many runtime instances covering many availability zones or even hybrid enterprise/cloud resources. At the application layer, computation occurs as data flows over the graph of Web Agents. When a Web Agent links to another Web Agent that runs in the same instance, they share state at the speed of memory. When Web Agents are linked across instances, they are at most ½ RTT out of sync with each other, which is many times faster than any RESTful service. Swim thus offers several orders of magnitude performance improvement over other stream processors. Streaming implementations of key analytical, learning and prediction algorithms are included in Swim, but it is also easy to interface with other open source or commercial technologies, including Apache Spark or Apache Flink.
Summary
Organizations need to analyze, learn and predict continuously, in context, at scale. They need to act in real-time or fall behind the rate at which their assets and infrastructure stream events. Event streaming is a useful abstraction but offers no solution to the challenge of developing stateful, concurrent applications that continuously compute on streaming data to deliver real-time insights and responses at scale. Pushing additional analytical features or data management systems into the database doesn’t help either: Databases do not perform sophisticated contextual computation that delivers meaning from streams of seemingly unrelated events. Finally, streaming analytics systems offer a top-down, management-centric approach to creating dashboards and delivering KPIs. They tend to be application domain specific, and they fail to address the need to deliver responses of local, contextual value, everywhere, concurrently.
Continuous intelligence addresses the need to statefully fuse streaming and traditional data, analyzing, learning, and predicting on-the-fly in response to streaming data from distributed sources – concurrently and at huge scale.
Continuous intelligence embraces infrastructure service patterns like “pub/sub” from event streaming. It addresses the application platform need to help organizations develop, deploy, and operate stateful applications that consume streaming events, analyzing, learning and predicting on the fly to deliver streams of real-time insights and responses.
Although modern databases can store data for later analysis, and update relational tables or modify graphs, continuous intelligence drives analysis from the arrival of data – adopting an “analyze-then-store” architecture that automatically builds and continuously executes a distributed, live model from streaming data. Whereas streaming analytics applications use a top-down query/response visualization/user-driven control loop, continuous intelligence applications continuously compute and stream insights, deliver truly real-time user experiences and facilitate real-time automatic responses at massive scale.
To read parts 1 to 5 of this guest article series, please visit the Swim blog. Or, you can download the entire series, parts 1 through 6, as an eBook here.
Speaker bio:
Simon Crosby is CTO at Swim. Swim offers the first open core, enterprise-grade platform for continuous intelligence at scale, providing businesses with complete situational awareness and operational decision support at every moment. Simon co-founded Bromium (now HP SureClick) in 2010 and currently serves as a strategic advisor. Previously, he was the CTO of the Data Center and Cloud Division at Citrix Systems; founder, CTO, and vice president of strategy and corporate development at XenSource; and a principal engineer at Intel, as well as a faculty member at Cambridge University, where he led the research on network performance and control and multimedia operating systems.
Simon is an equity partner at DCVC, serves on the board of Cambridge in America, and is an investor in and advisor to numerous startups. He is the author of 35 research papers and patents on a number of data center and networking topics, including security, network and server virtualization, and resource optimization and performance. He holds a PhD in computer science from the University of Cambridge, an MSc from the University of Stellenbosch, South Africa, and a BSc (with honors) in computer science and mathematics from the University of Cape Town, South Africa.



Speak Your Mind